 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSUTRA: Scalable Multilingual Language Model Architecture
May 07, 2024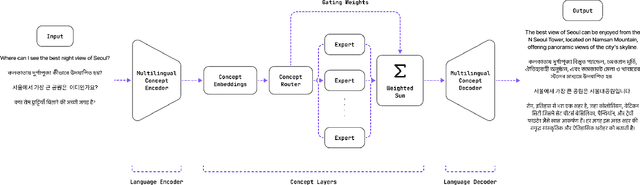

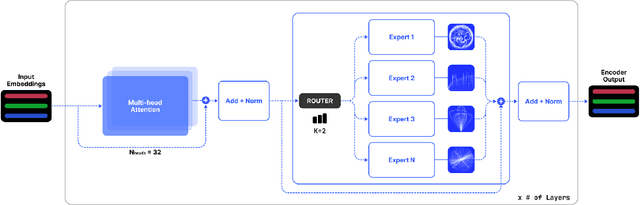

In this paper, we introduce SUTRA, multilingual Large Language Model architecture capable of understanding, reasoning, and generating text in over 50 languages. SUTRA's design uniquely decouples core conceptual understanding from language-specific processing, which facilitates scalable and efficient multilingual alignment and learning. Employing a Mixture of Experts framework both in language and concept processing, SUTRA demonstrates both computational efficiency and responsiveness. Through extensive evaluations, SUTRA is demonstrated to surpass existing models like GPT-3.5, Llama2 by 20-30% on leading Massive Multitask Language Understanding (MMLU) benchmarks for multilingual tasks. SUTRA models are also online LLMs that can use knowledge from the internet to provide hallucination-free, factual and up-to-date responses while retaining their multilingual capabilities. Furthermore, we explore the broader implications of its architecture for the future of multilingual AI, highlighting its potential to democratize access to AI technology globally and to improve the equity and utility of AI in regions with predominantly non-English languages. Our findings suggest that SUTRA not only fills pivotal gaps in multilingual model capabilities but also establishes a new benchmark for operational efficiency and scalability in AI applications.
Straight to Shapes++: Real-time Instance Segmentation Made More Accurate
May 27, 2019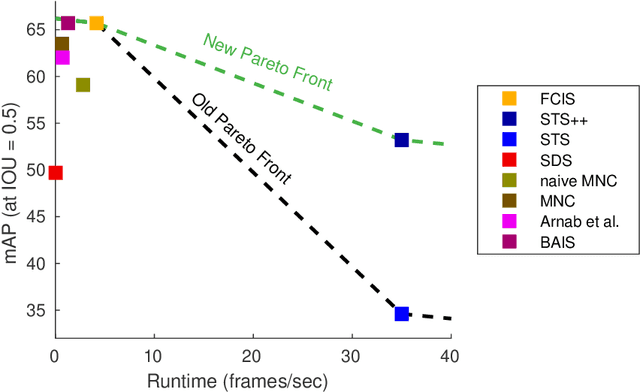
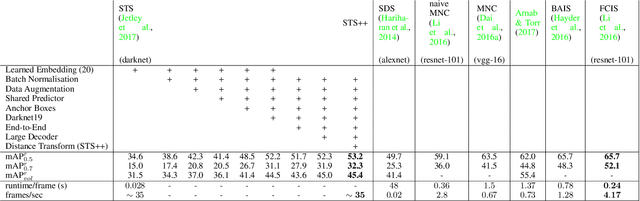
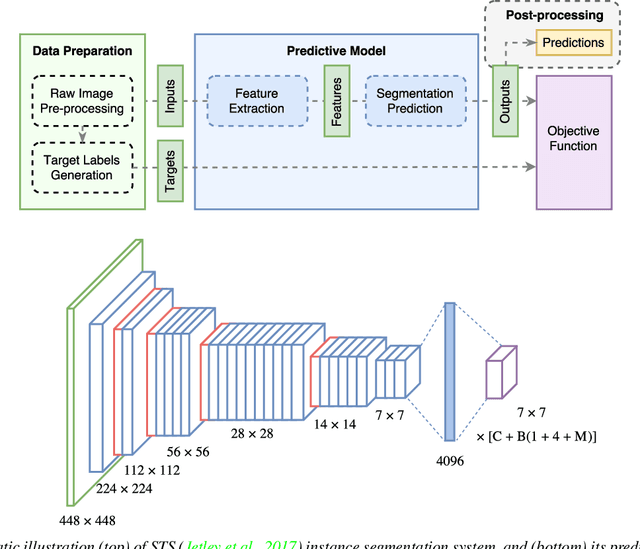
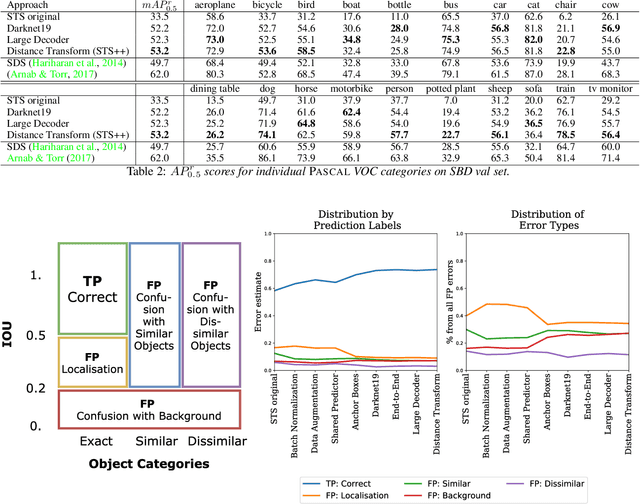
Instance segmentation is an important problem in computer vision, with applications in autonomous driving, drone navigation and robotic manipulation. However, most existing methods are not real-time, complicating their deployment in time-sensitive contexts. In this work, we extend an existing approach to real-time instance segmentation, called `Straight to Shapes' (STS), which makes use of low-dimensional shape embedding spaces to directly regress to object shape masks. The STS model can run at 35 FPS on a high-end desktop, but its accuracy is significantly worse than that of offline state-of-the-art methods. We leverage recent advances in the design and training of deep instance segmentation models to improve the performance accuracy of the STS model whilst keeping its real-time capabilities intact. In particular, we find that parameter sharing, more aggressive data augmentation and the use of structured loss for shape mask prediction all provide a useful boost to the network performance. Our proposed approach, `Straight to Shapes++', achieves a remarkable 19.7 point improvement in mAP (at IOU of 0.5) over the original method as evaluated on the PASCAL VOC dataset, thus redefining the accuracy frontier at real-time speeds. Since the accuracy of instance segmentation is closely tied to that of object bounding box prediction, we also study the error profile of the latter and examine the failure modes of our method for future improvements.
Incremental Tube Construction for Human Action Detection
Jul 23, 2018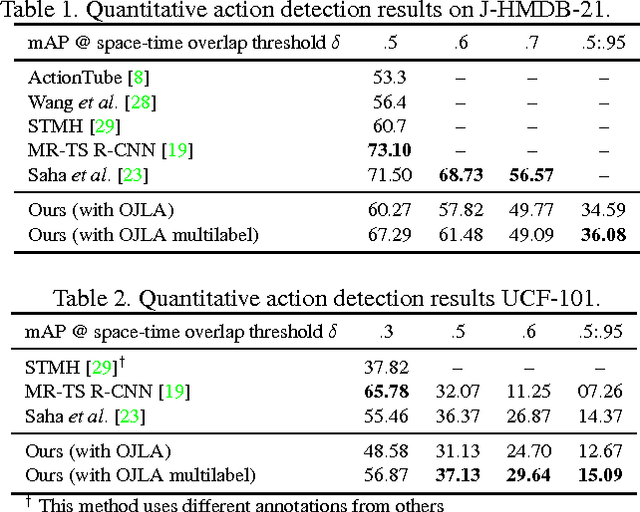
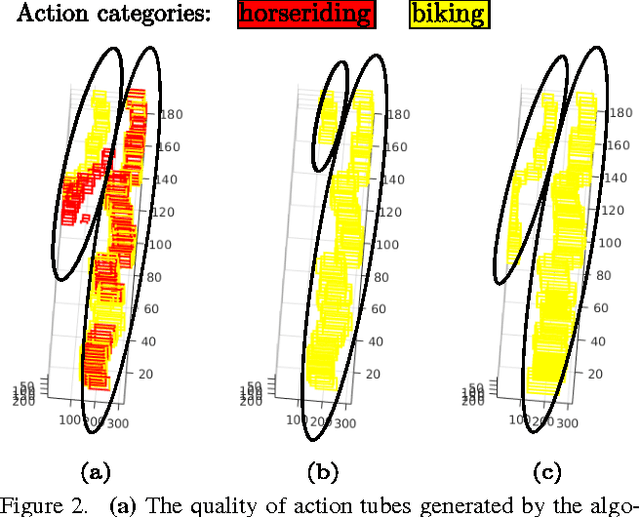
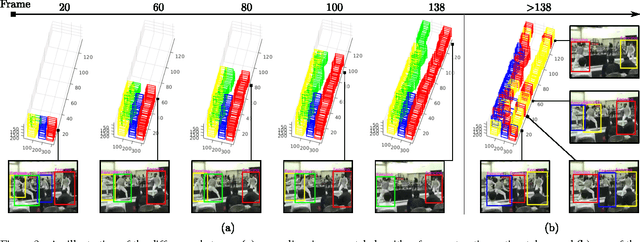

Current state-of-the-art action detection systems are tailored for offline batch-processing applications. However, for online applications like human-robot interaction, current systems fall short, either because they only detect one action per video, or because they assume that the entire video is available ahead of time. In this work, we introduce a real-time and online joint-labelling and association algorithm for action detection that can incrementally construct space-time action tubes on the most challenging action videos in which different action categories occur concurrently. In contrast to previous methods, we solve the detection-window association and action labelling problems jointly in a single pass. We demonstrate superior online association accuracy and speed (2.2ms per frame) as compared to the current state-of-the-art offline systems. We further demonstrate that the entire action detection pipeline can easily be made to work effectively in real-time using our action tube construction algorithm.
Online Real-time Multiple Spatiotemporal Action Localisation and Prediction
Aug 24, 2017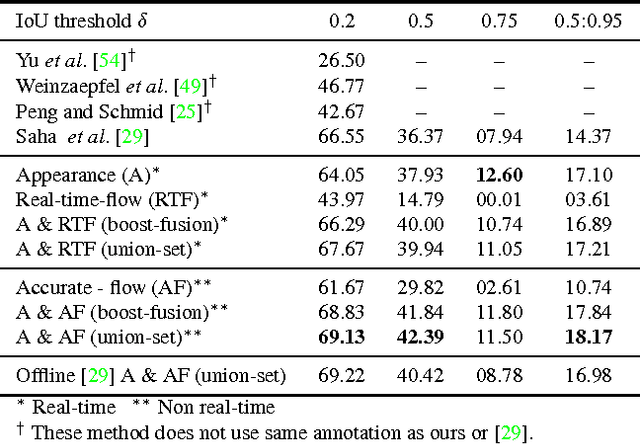
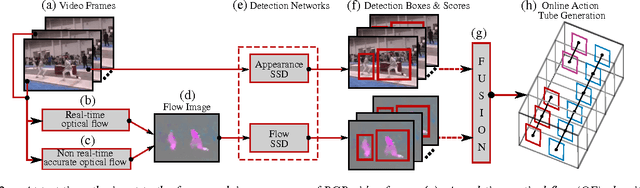
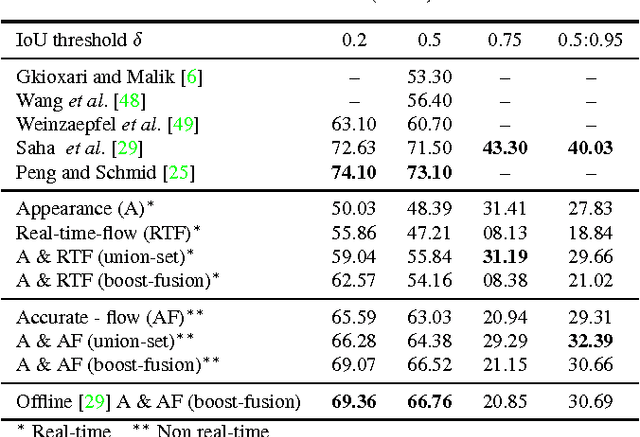
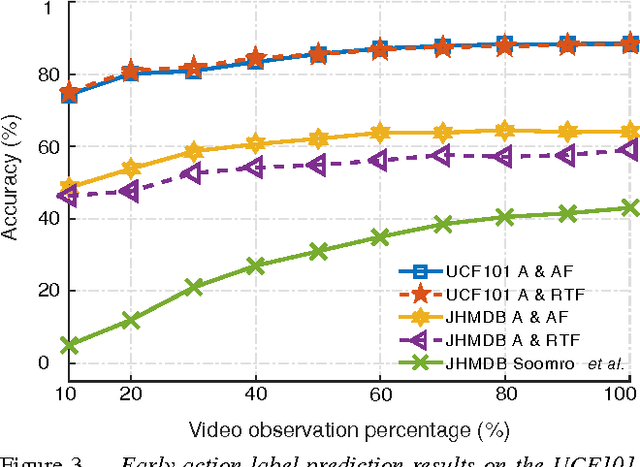
We present a deep-learning framework for real-time multiple spatio-temporal (S/T) action localisation, classification and early prediction. Current state-of-the-art approaches work offline and are too slow to be useful in real- world settings. To overcome their limitations we introduce two major developments. Firstly, we adopt real-time SSD (Single Shot MultiBox Detector) convolutional neural networks to regress and classify detection boxes in each video frame potentially containing an action of interest. Secondly, we design an original and efficient online algorithm to incrementally construct and label `action tubes' from the SSD frame level detections. As a result, our system is not only capable of performing S/T detection in real time, but can also perform early action prediction in an online fashion. We achieve new state-of-the-art results in both S/T action localisation and early action prediction on the challenging UCF101-24 and J-HMDB-21 benchmarks, even when compared to the top offline competitors. To the best of our knowledge, ours is the first real-time (up to 40fps) system able to perform online S/T action localisation and early action prediction on the untrimmed videos of UCF101-24.
Spatio-temporal Human Action Localisation and Instance Segmentation in Temporally Untrimmed Videos
Aug 06, 2017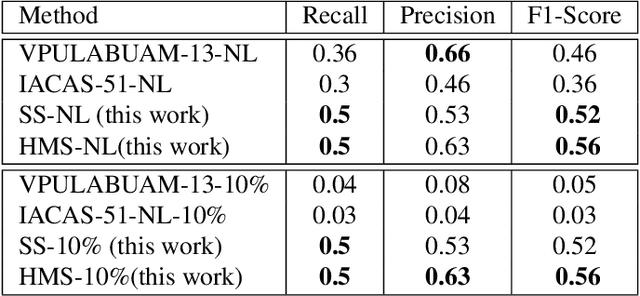



Current state-of-the-art human action recognition is focused on the classification of temporally trimmed videos in which only one action occurs per frame. In this work we address the problem of action localisation and instance segmentation in which multiple concurrent actions of the same class may be segmented out of an image sequence. We cast the action tube extraction as an energy maximisation problem in which configurations of region proposals in each frame are assigned a cost and the best action tubes are selected via two passes of dynamic programming. One pass associates region proposals in space and time for each action category, and another pass is used to solve for the tube's temporal extent and to enforce a smooth label sequence through the video. In addition, by taking advantage of recent work on action foreground-background segmentation, we are able to associate each tube with class-specific segmentations. We demonstrate the performance of our algorithm on the challenging LIRIS-HARL dataset and achieve a new state-of-the-art result which is 14.3 times better than previous methods.
InfiniTAM v3: A Framework for Large-Scale 3D Reconstruction with Loop Closure
Aug 02, 2017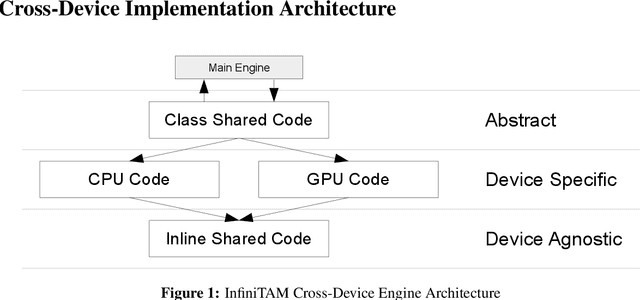
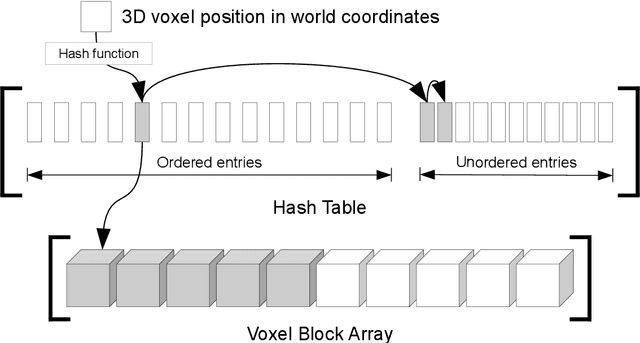
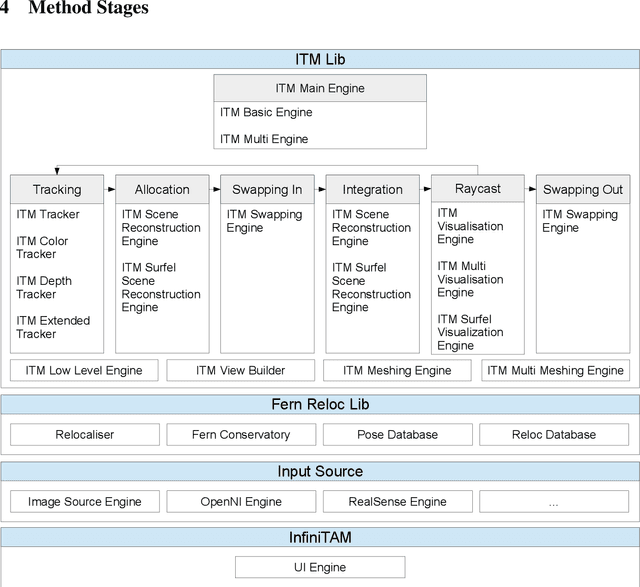
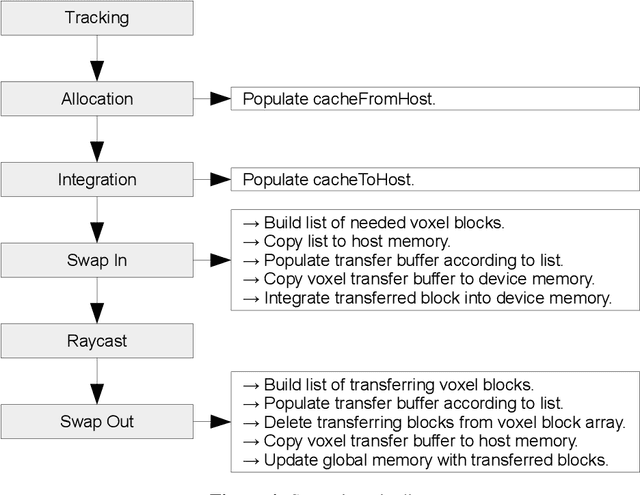
Volumetric models have become a popular representation for 3D scenes in recent years. One breakthrough leading to their popularity was KinectFusion, which focuses on 3D reconstruction using RGB-D sensors. However, monocular SLAM has since also been tackled with very similar approaches. Representing the reconstruction volumetrically as a TSDF leads to most of the simplicity and efficiency that can be achieved with GPU implementations of these systems. However, this representation is memory-intensive and limits applicability to small-scale reconstructions. Several avenues have been explored to overcome this. With the aim of summarizing them and providing for a fast, flexible 3D reconstruction pipeline, we propose a new, unifying framework called InfiniTAM. The idea is that steps like camera tracking, scene representation and integration of new data can easily be replaced and adapted to the user's needs. This report describes the technical implementation details of InfiniTAM v3, the third version of our InfiniTAM system. We have added various new features, as well as making numerous enhancements to the low-level code that significantly improve our camera tracking performance. The new features that we expect to be of most interest are (i) a robust camera tracking module; (ii) an implementation of Glocker et al.'s keyframe-based random ferns camera relocaliser; (iii) a novel approach to globally-consistent TSDF-based reconstruction, based on dividing the scene into rigid submaps and optimising the relative poses between them; and (iv) an implementation of Keller et al.'s surfel-based reconstruction approach.
Straight to Shapes: Real-time Detection of Encoded Shapes
Jul 05, 2017


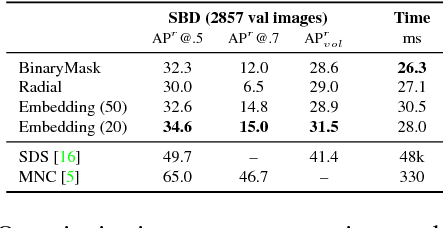
Current object detection approaches predict bounding boxes, but these provide little instance-specific information beyond location, scale and aspect ratio. In this work, we propose to directly regress to objects' shapes in addition to their bounding boxes and categories. It is crucial to find an appropriate shape representation that is compact and decodable, and in which objects can be compared for higher-order concepts such as view similarity, pose variation and occlusion. To achieve this, we use a denoising convolutional auto-encoder to establish an embedding space, and place the decoder after a fast end-to-end network trained to regress directly to the encoded shape vectors. This yields what to the best of our knowledge is the first real-time shape prediction network, running at ~35 FPS on a high-end desktop. With higher-order shape reasoning well-integrated into the network pipeline, the network shows the useful practical quality of generalising to unseen categories similar to the ones in the training set, something that most existing approaches fail to handle.
Deep Learning for Detecting Multiple Space-Time Action Tubes in Videos
Aug 04, 2016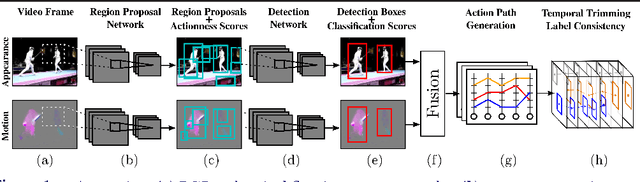
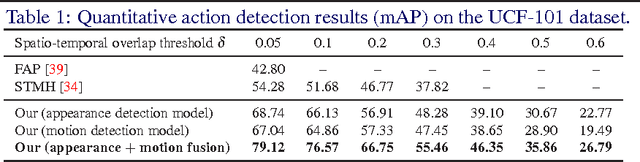
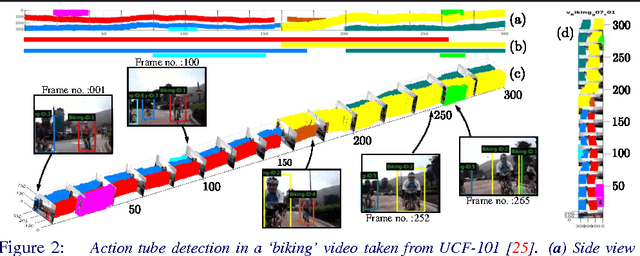
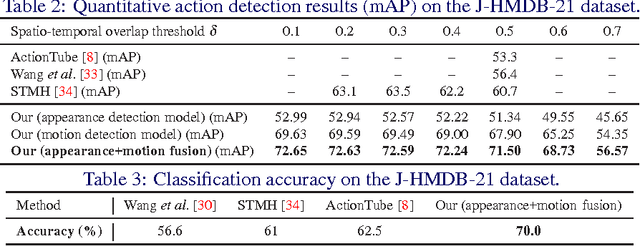
In this work, we propose an approach to the spatiotemporal localisation (detection) and classification of multiple concurrent actions within temporally untrimmed videos. Our framework is composed of three stages. In stage 1, appearance and motion detection networks are employed to localise and score actions from colour images and optical flow. In stage 2, the appearance network detections are boosted by combining them with the motion detection scores, in proportion to their respective spatial overlap. In stage 3, sequences of detection boxes most likely to be associated with a single action instance, called action tubes, are constructed by solving two energy maximisation problems via dynamic programming. While in the first pass, action paths spanning the whole video are built by linking detection boxes over time using their class-specific scores and their spatial overlap, in the second pass, temporal trimming is performed by ensuring label consistency for all constituting detection boxes. We demonstrate the performance of our algorithm on the challenging UCF101, J-HMDB-21 and LIRIS-HARL datasets, achieving new state-of-the-art results across the board and significantly increasing detection speed at test time. We achieve a huge leap forward in action detection performance and report a 20% and 11% gain in mAP (mean average precision) on UCF-101 and J-HMDB-21 datasets respectively when compared to the state-of-the-art.
Joint Object-Material Category Segmentation from Audio-Visual Cues
Jan 10, 2016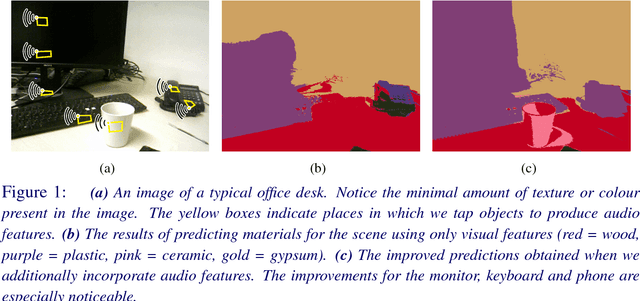


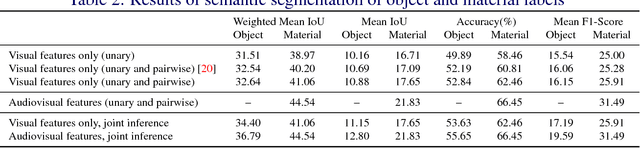
It is not always possible to recognise objects and infer material properties for a scene from visual cues alone, since objects can look visually similar whilst being made of very different materials. In this paper, we therefore present an approach that augments the available dense visual cues with sparse auditory cues in order to estimate dense object and material labels. Since estimates of object class and material properties are mutually informative, we optimise our multi-output labelling jointly using a random-field framework. We evaluate our system on a new dataset with paired visual and auditory data that we make publicly available. We demonstrate that this joint estimation of object and material labels significantly outperforms the estimation of either category in isolation.
SemanticPaint: A Framework for the Interactive Segmentation of 3D Scenes
Oct 13, 2015
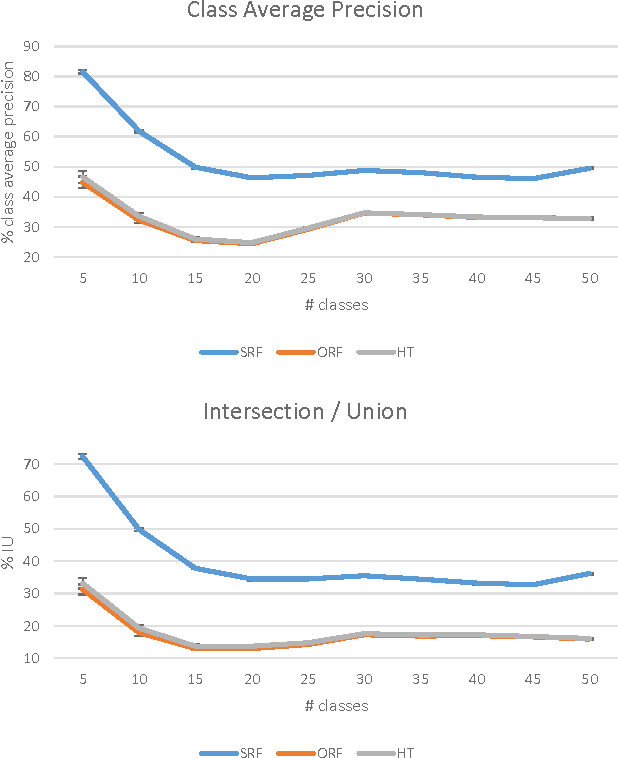

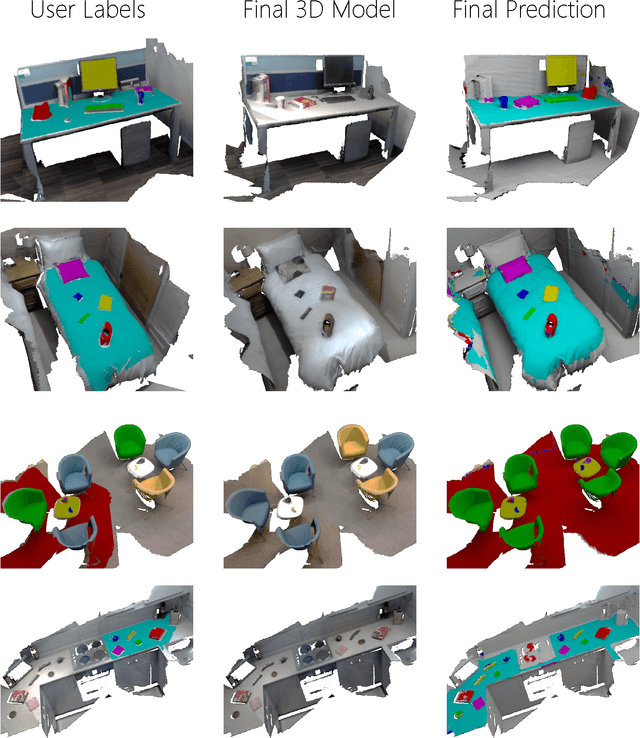
We present an open-source, real-time implementation of SemanticPaint, a system for geometric reconstruction, object-class segmentation and learning of 3D scenes. Using our system, a user can walk into a room wearing a depth camera and a virtual reality headset, and both densely reconstruct the 3D scene and interactively segment the environment into object classes such as 'chair', 'floor' and 'table'. The user interacts physically with the real-world scene, touching objects and using voice commands to assign them appropriate labels. These user-generated labels are leveraged by an online random forest-based machine learning algorithm, which is used to predict labels for previously unseen parts of the scene. The entire pipeline runs in real time, and the user stays 'in the loop' throughout the process, receiving immediate feedback about the progress of the labelling and interacting with the scene as necessary to refine the predicted segmentation.