 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextbooks Are All You Need
Jun 20, 2023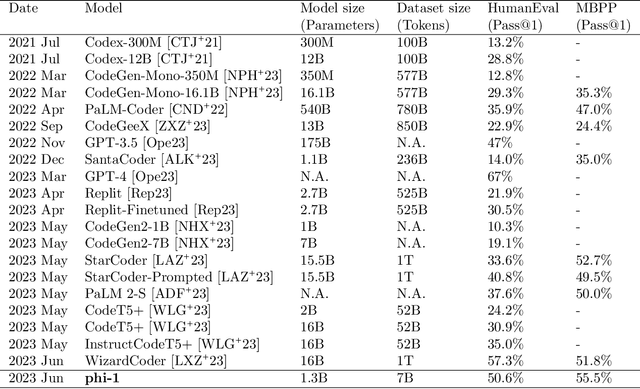
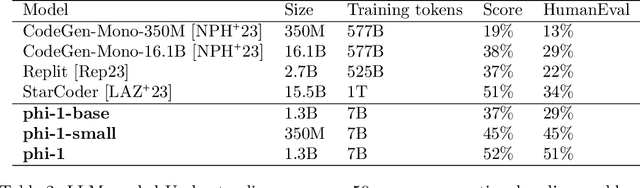
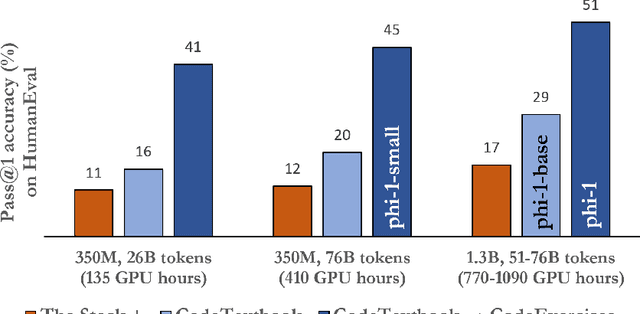
We introduce phi-1, a new large language model for code, with significantly smaller size than competing models: phi-1 is a Transformer-based model with 1.3B parameters, trained for 4 days on 8 A100s, using a selection of ``textbook quality" data from the web (6B tokens) and synthetically generated textbooks and exercises with GPT-3.5 (1B tokens). Despite this small scale, phi-1 attains pass@1 accuracy 50.6% on HumanEval and 55.5% on MBPP. It also displays surprising emergent properties compared to phi-1-base, our model before our finetuning stage on a dataset of coding exercises, and phi-1-small, a smaller model with 350M parameters trained with the same pipeline as phi-1 that still achieves 45% on HumanEval.
Scaling the Convex Barrier with Sparse Dual Algorithms
Jan 26, 2021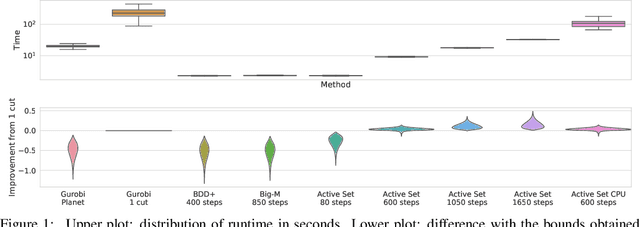
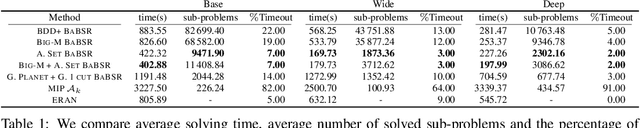
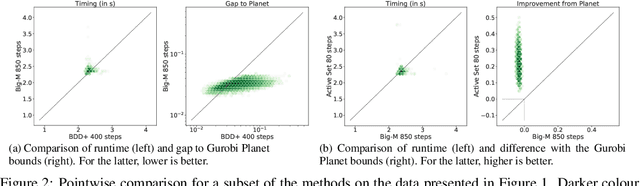
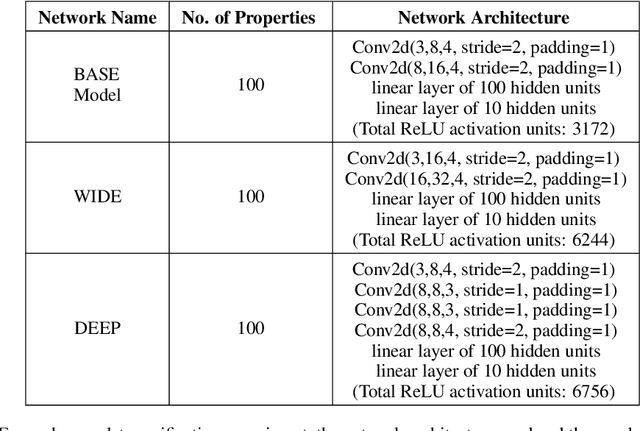
Tight and efficient neural network bounding is crucial to the scaling of neural network verification systems. Many efficient bounding algorithms have been presented recently, but they are often too loose to verify more challenging properties. This is due to the weakness of the employed relaxation, which is usually a linear program of size linear in the number of neurons. While a tighter linear relaxation for piecewise-linear activations exists, it comes at the cost of exponentially many constraints and currently lacks an efficient customized solver. We alleviate this deficiency by presenting two novel dual algorithms: one operates a subgradient method on a small active set of dual variables, the other exploits the sparsity of Frank-Wolfe type optimizers to incur only a linear memory cost. Both methods recover the strengths of the new relaxation: tightness and a linear separation oracle. At the same time, they share the benefits of previous dual approaches for weaker relaxations: massive parallelism, GPU implementation, low cost per iteration and valid bounds at any time. As a consequence, we can obtain better bounds than off-the-shelf solvers in only a fraction of their running time, attaining significant formal verification speed-ups.
AutoSimulate: (Quickly) Learning Synthetic Data Generation
Aug 16, 2020

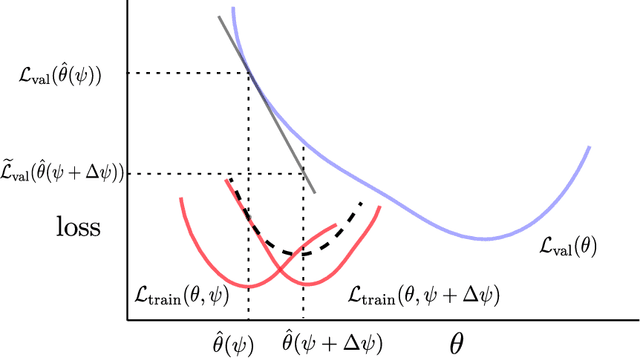

Simulation is increasingly being used for generating large labelled datasets in many machine learning problems. Recent methods have focused on adjusting simulator parameters with the goal of maximising accuracy on a validation task, usually relying on REINFORCE-like gradient estimators. However these approaches are very expensive as they treat the entire data generation, model training, and validation pipeline as a black-box and require multiple costly objective evaluations at each iteration. We propose an efficient alternative for optimal synthetic data generation, based on a novel differentiable approximation of the objective. This allows us to optimize the simulator, which may be non-differentiable, requiring only one objective evaluation at each iteration with a little overhead. We demonstrate on a state-of-the-art photorealistic renderer that the proposed method finds the optimal data distribution faster (up to $50\times$), with significantly reduced training data generation (up to $30\times$) and better accuracy ($+8.7\%$) on real-world test datasets than previous methods.
* ECCV 2020
STEER: Simple Temporal Regularization For Neural ODEs
Jul 01, 2020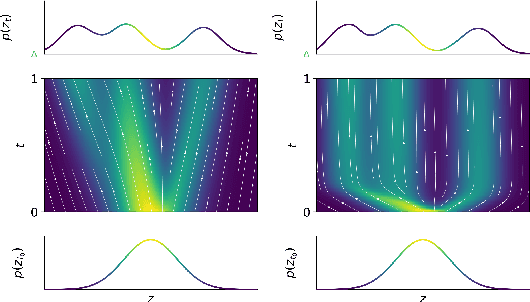
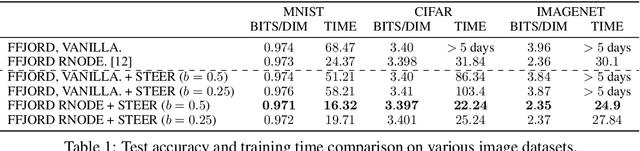
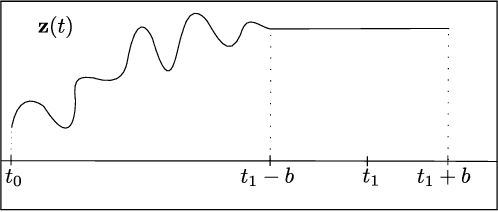
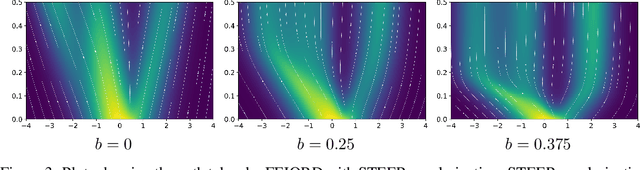
Training Neural Ordinary Differential Equations (ODEs) is often computationally expensive. Indeed, computing the forward pass of such models involves solving an ODE which can become arbitrarily complex during training. Recent works have shown that regularizing the dynamics of the ODE can partially alleviate this. In this paper we propose a new regularization technique: randomly sampling the end time of the ODE during training. The proposed regularization is simple to implement, has negligible overhead and is effective across a wide variety of tasks. Further, the technique is orthogonal to several other methods proposed to regularize the dynamics of ODEs and as such can be used in conjunction with them. We show through experiments on normalizing flows, time series models and image recognition that the proposed regularization can significantly decrease training time and even improve performance over baseline models.
Alpha MAML: Adaptive Model-Agnostic Meta-Learning
May 17, 2019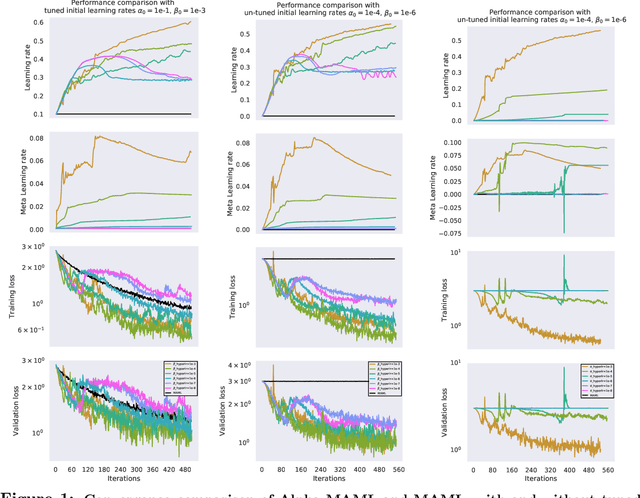


Model-agnostic meta-learning (MAML) is a meta-learning technique to train a model on a multitude of learning tasks in a way that primes the model for few-shot learning of new tasks. The MAML algorithm performs well on few-shot learning problems in classification, regression, and fine-tuning of policy gradients in reinforcement learning, but comes with the need for costly hyperparameter tuning for training stability. We address this shortcoming by introducing an extension to MAML, called Alpha MAML, to incorporate an online hyperparameter adaptation scheme that eliminates the need to tune meta-learning and learning rates. Our results with the Omniglot database demonstrate a substantial reduction in the need to tune MAML training hyperparameters and improvement to training stability with less sensitivity to hyperparameter choice.
Meta Learning Deep Visual Words for Fast Video Object Segmentation
Dec 04, 2018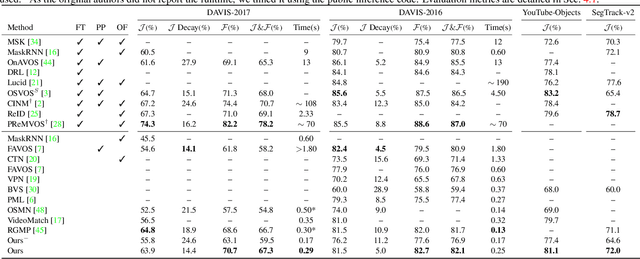

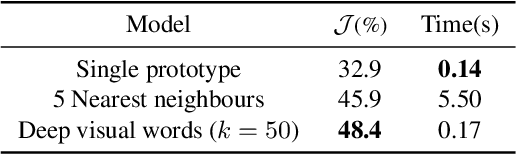
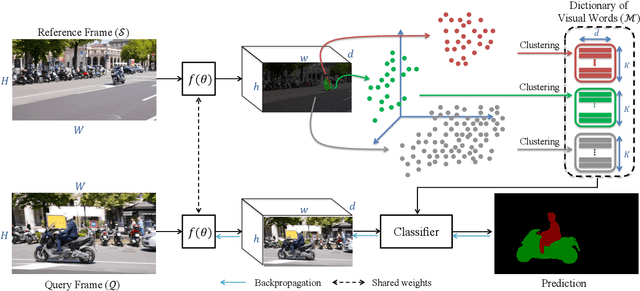
Meta learning has attracted a lot of attention recently. In this paper, we propose a fast and novel meta learning based method for video object segmentation that quickly adapts to new domains without any fine-tuning. The proposed model performs segmentation by matching pixels to object parts. The model represents object parts using deep visual words, and meta learns them with the objective of minimizing the object segmentation loss. This is however not straightforward as no ground-truth information is available for the object parts. We tackle this problem by iteratively performing unsupervised learning of the deep visual words, followed by supervised learning of the segmentation problem, given the visual words. Our experiments show that the proposed method performs on-par with state-of-the-art methods, while being computationally much more efficient.
Incremental Tube Construction for Human Action Detection
Jul 23, 2018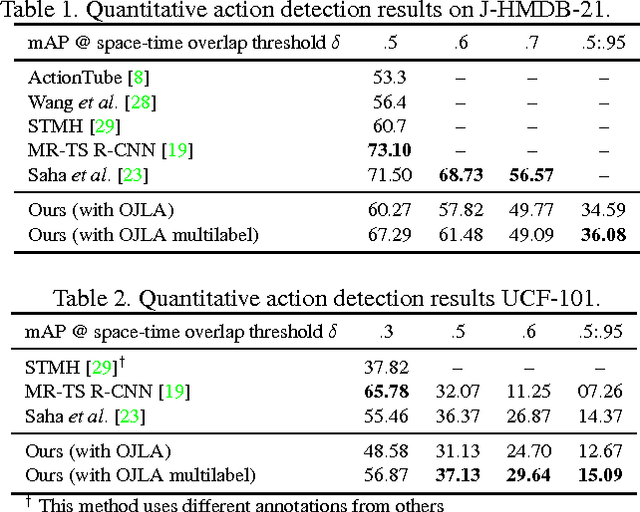
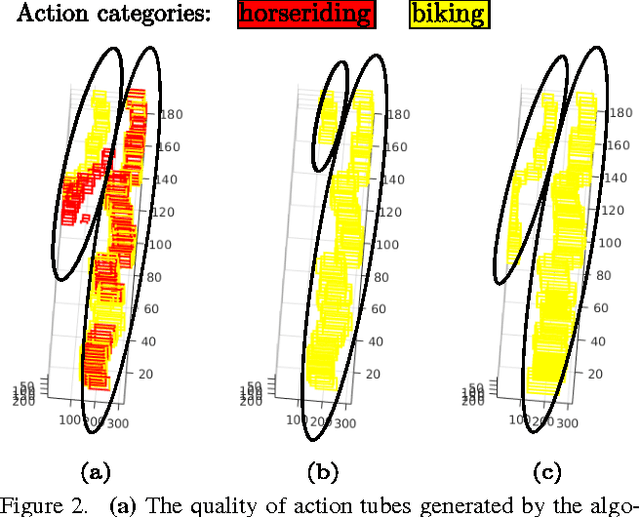
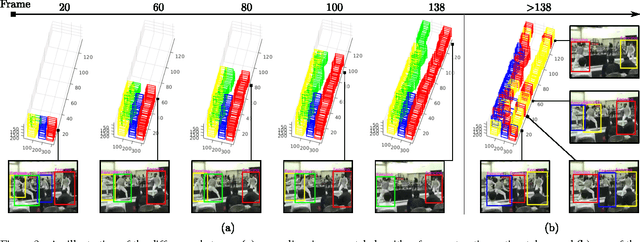

Current state-of-the-art action detection systems are tailored for offline batch-processing applications. However, for online applications like human-robot interaction, current systems fall short, either because they only detect one action per video, or because they assume that the entire video is available ahead of time. In this work, we introduce a real-time and online joint-labelling and association algorithm for action detection that can incrementally construct space-time action tubes on the most challenging action videos in which different action categories occur concurrently. In contrast to previous methods, we solve the detection-window association and action labelling problems jointly in a single pass. We demonstrate superior online association accuracy and speed (2.2ms per frame) as compared to the current state-of-the-art offline systems. We further demonstrate that the entire action detection pipeline can easily be made to work effectively in real-time using our action tube construction algorithm.