 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrediction of Sewer Pipe Deterioration Using Random Forest Classification
Dec 09, 2019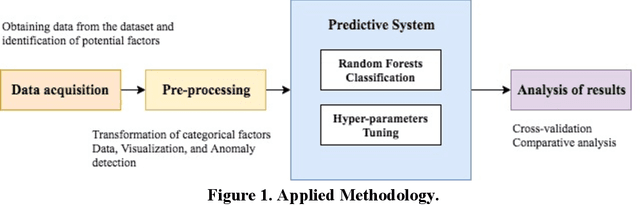


Wastewater infrastructure systems deteriorate over time due to a combination of physical and chemical factors. Failure of this significant infrastructure could affect important social, environmental, and economic impacts. Furthermore, recognizing the optimized timeline for inspection of sewer pipelines are challenging tasks for the utility managers and other authorities. Regular examination of sewer networks is not cost-effective due to limited time and high cost of assessment technologies and a large inventory of pipes. To avoid such obstacles, various researchers endeavored to improve infrastructure condition assessment methodologies to maintain sewer pipe systems at the desired condition. Sewer condition prediction models are developed to provide a framework to forecast the future condition of pipes to schedule inspection frequencies. The main goal of this study is to develop a predictive model for wastewater pipes using random forest classification. Predictive models can effectively predict sewer pipe condition and can increase the certainty level of the predictive results and decrease uncertainty in the current condition of wastewater pipes. The developed random forest classification model has achieved a stratified test set false negative rate, the false positive rate, and an excellent area under the ROC curve of 0.81 in a case study application for the City of LA, California. An area under the ROC curve > 0.80 indicates the developed model is an "excellent" choice for predicting the condition of individual pipes in a sewer network. The deterioration models can be used in the industry to improve the inspection timeline and maintenance planning.
Artificial Neural Networks and Adaptive Neuro-fuzzy Models for Prediction of Remaining Useful Life
Aug 28, 2019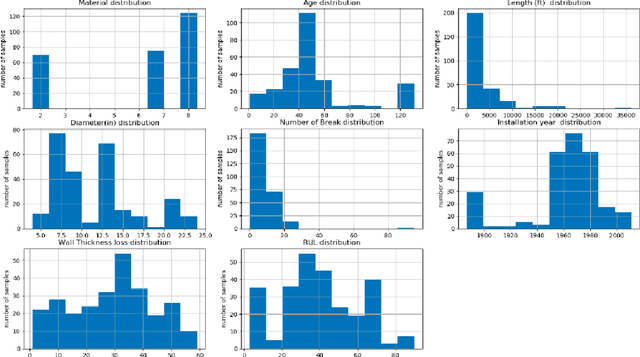
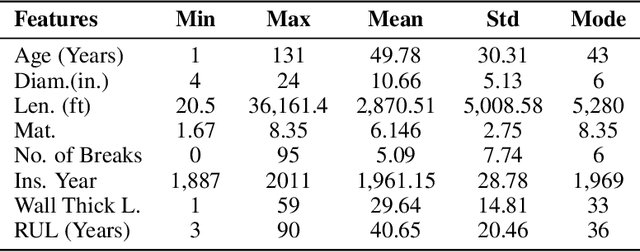
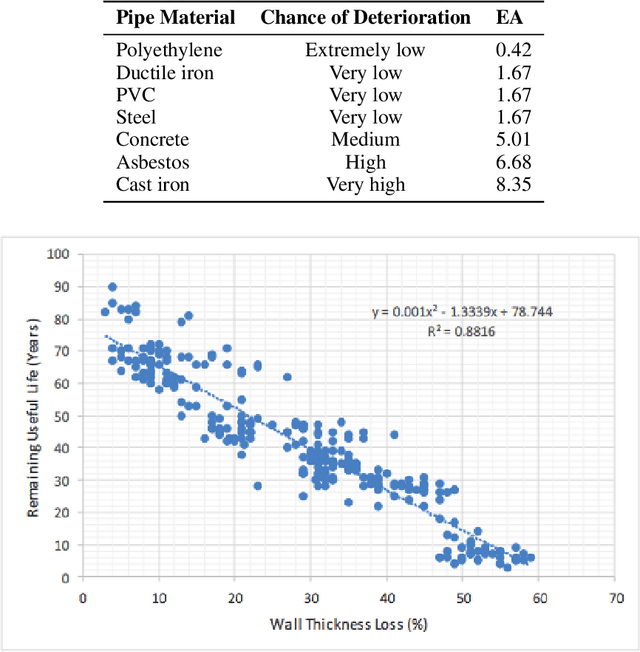
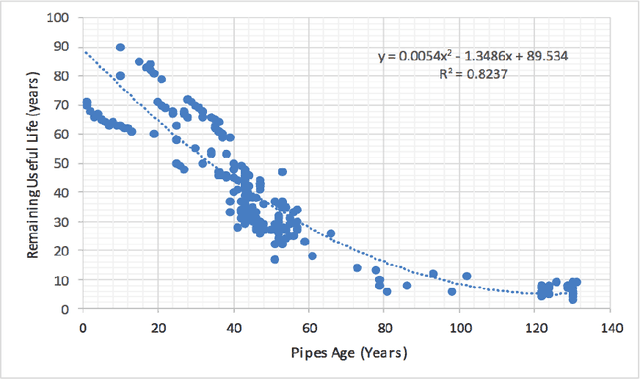
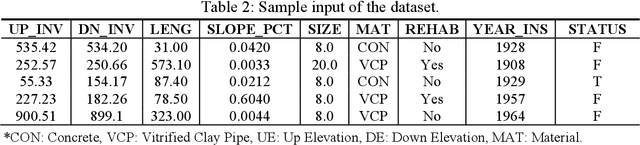
The U.S. water distribution system contains thousands of miles of pipes constructed from different materials, and of various sizes, and age. These pipes suffer from physical, environmental, structural and operational stresses, causing deterioration which eventually leads to their failure. Pipe deterioration results in increased break rates, reduced hydraulic capacity, and detrimental impacts on water quality. Therefore, it is crucial to use accurate models to forecast deterioration rates along with estimating the remaining useful life of the pipes to implement essential interference plans in order to prevent catastrophic failures. This paper discusses a computational model that forecasts the RUL of water pipes by applying Artificial Neural Networks (ANNs) as well as Adaptive Neural Fuzzy Inference System (ANFIS). These models are trained and tested acquired field data to identify the significant parameters that impact the prediction of RUL. It is concluded that, on average, with approximately 10\% of wall thickness loss in existing cast iron, ductile iron, asbestos-cement, and steel water pipes, the reduction of the remaining useful life is approximately 50%
Meta Learning Deep Visual Words for Fast Video Object Segmentation
Dec 04, 2018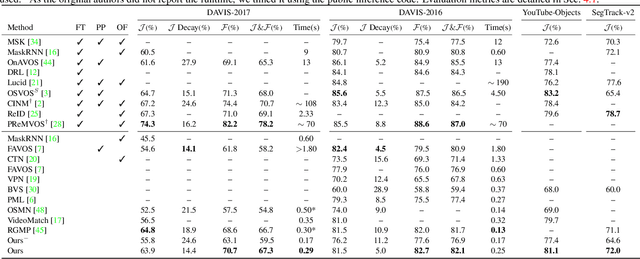

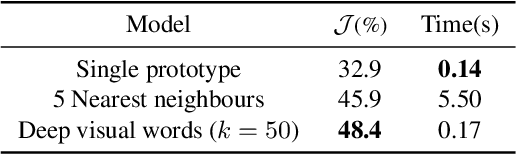
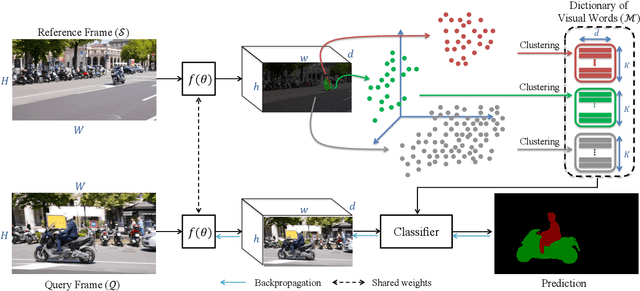
Meta learning has attracted a lot of attention recently. In this paper, we propose a fast and novel meta learning based method for video object segmentation that quickly adapts to new domains without any fine-tuning. The proposed model performs segmentation by matching pixels to object parts. The model represents object parts using deep visual words, and meta learns them with the objective of minimizing the object segmentation loss. This is however not straightforward as no ground-truth information is available for the object parts. We tackle this problem by iteratively performing unsupervised learning of the deep visual words, followed by supervised learning of the segmentation problem, given the visual words. Our experiments show that the proposed method performs on-par with state-of-the-art methods, while being computationally much more efficient.
Soft Correspondences in Multimodal Scene Parsing
Sep 28, 2017


Exploiting multiple modalities for semantic scene parsing has been shown to improve accuracy over the singlemodality scenario. However multimodal datasets often suffer from problems such as data misalignment and label inconsistencies, where the existing methods assume that corresponding regions in two modalities must have identical labels. We propose to address this issue, by formulating multimodal semantic labeling as inference in a CRF and introducing latent nodes to explicitly model inconsistencies between two modalities. These latent nodes allow us not only to leverage information from both domains to improve their labeling, but also to cut the edges between inconsistent regions. We propose to learn intradomain and inter-domain potential functions from training data to avoid hand-tuning of the model parameters. We evaluate our approach on two publicly available datasets containing 2D and 3D data. Thanks to our latent nodes and our learning strategy, our method outperforms the state-of-the-art in both cases. Moreover, in order to highlight the benefits of the geometric information and the potential of our method in simultaneous 2D/3D semantic and geometric inference, we performed simultaneous inference of semantic and geometric classes both in 2D and 3D that led to satisfactory improvements of the labeling results in both datasets.
Sample and Filter: Nonparametric Scene Parsing via Efficient Filtering
Mar 15, 2016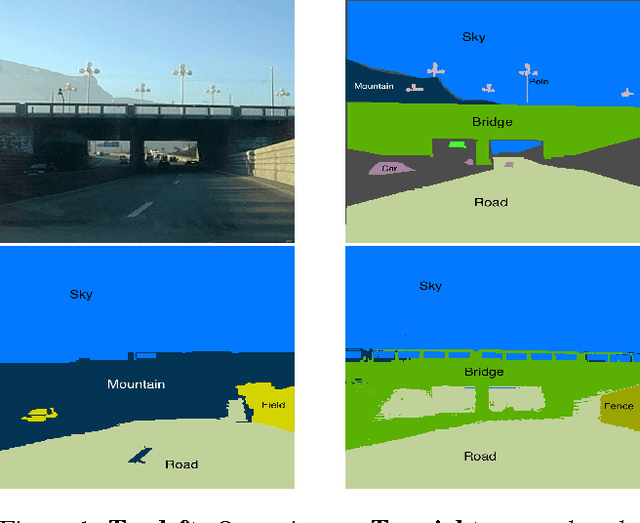
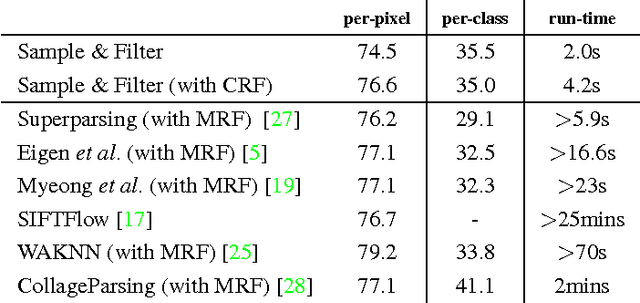

Scene parsing has attracted a lot of attention in computer vision. While parametric models have proven effective for this task, they cannot easily incorporate new training data. By contrast, nonparametric approaches, which bypass any learning phase and directly transfer the labels from the training data to the query images, can readily exploit new labeled samples as they become available. Unfortunately, because of the computational cost of their label transfer procedures, state-of-the-art nonparametric methods typically filter out most training images to only keep a few relevant ones to label the query. As such, these methods throw away many images that still contain valuable information and generally obtain an unbalanced set of labeled samples. In this paper, we introduce a nonparametric approach to scene parsing that follows a sample-and-filter strategy. More specifically, we propose to sample labeled superpixels according to an image similarity score, which allows us to obtain a balanced set of samples. We then formulate label transfer as an efficient filtering procedure, which lets us exploit more labeled samples than existing techniques. Our experiments evidence the benefits of our approach over state-of-the-art nonparametric methods on two benchmark datasets.