 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta Learning Deep Visual Words for Fast Video Object Segmentation
Paper and Code
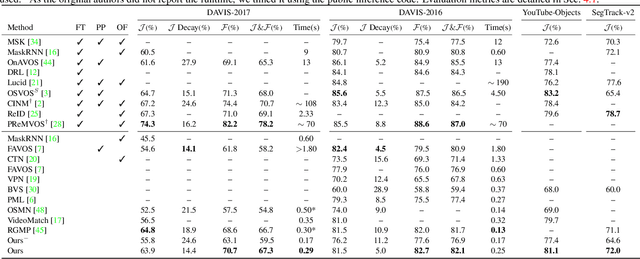

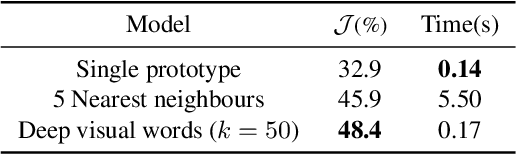
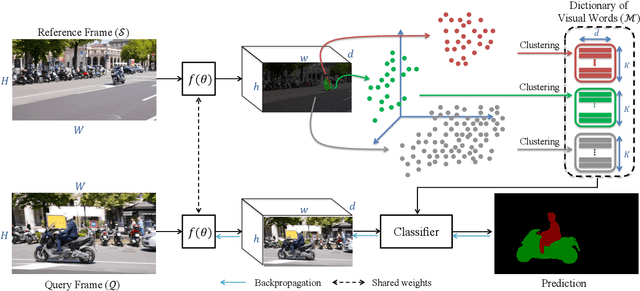
Meta learning has attracted a lot of attention recently. In this paper, we propose a fast and novel meta learning based method for video object segmentation that quickly adapts to new domains without any fine-tuning. The proposed model performs segmentation by matching pixels to object parts. The model represents object parts using deep visual words, and meta learns them with the objective of minimizing the object segmentation loss. This is however not straightforward as no ground-truth information is available for the object parts. We tackle this problem by iteratively performing unsupervised learning of the deep visual words, followed by supervised learning of the segmentation problem, given the visual words. Our experiments show that the proposed method performs on-par with state-of-the-art methods, while being computationally much more efficient.