 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft Correspondences in Multimodal Scene Parsing
Sep 28, 2017


Exploiting multiple modalities for semantic scene parsing has been shown to improve accuracy over the singlemodality scenario. However multimodal datasets often suffer from problems such as data misalignment and label inconsistencies, where the existing methods assume that corresponding regions in two modalities must have identical labels. We propose to address this issue, by formulating multimodal semantic labeling as inference in a CRF and introducing latent nodes to explicitly model inconsistencies between two modalities. These latent nodes allow us not only to leverage information from both domains to improve their labeling, but also to cut the edges between inconsistent regions. We propose to learn intradomain and inter-domain potential functions from training data to avoid hand-tuning of the model parameters. We evaluate our approach on two publicly available datasets containing 2D and 3D data. Thanks to our latent nodes and our learning strategy, our method outperforms the state-of-the-art in both cases. Moreover, in order to highlight the benefits of the geometric information and the potential of our method in simultaneous 2D/3D semantic and geometric inference, we performed simultaneous inference of semantic and geometric classes both in 2D and 3D that led to satisfactory improvements of the labeling results in both datasets.
Sample and Filter: Nonparametric Scene Parsing via Efficient Filtering
Mar 15, 2016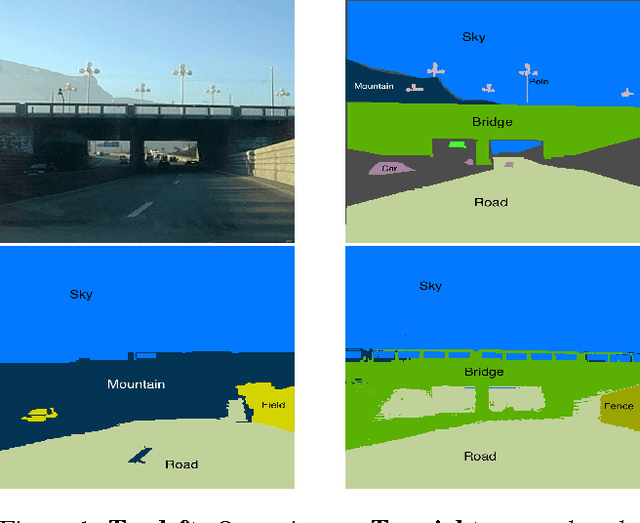
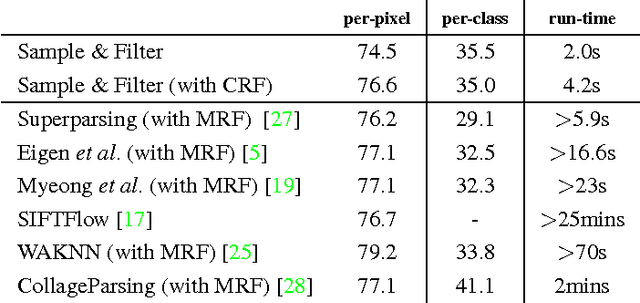

Scene parsing has attracted a lot of attention in computer vision. While parametric models have proven effective for this task, they cannot easily incorporate new training data. By contrast, nonparametric approaches, which bypass any learning phase and directly transfer the labels from the training data to the query images, can readily exploit new labeled samples as they become available. Unfortunately, because of the computational cost of their label transfer procedures, state-of-the-art nonparametric methods typically filter out most training images to only keep a few relevant ones to label the query. As such, these methods throw away many images that still contain valuable information and generally obtain an unbalanced set of labeled samples. In this paper, we introduce a nonparametric approach to scene parsing that follows a sample-and-filter strategy. More specifically, we propose to sample labeled superpixels according to an image similarity score, which allows us to obtain a balanced set of samples. We then formulate label transfer as an efficient filtering procedure, which lets us exploit more labeled samples than existing techniques. Our experiments evidence the benefits of our approach over state-of-the-art nonparametric methods on two benchmark datasets.