 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSINE: SINgle Image Editing with Text-to-Image Diffusion Models
Dec 08, 2022

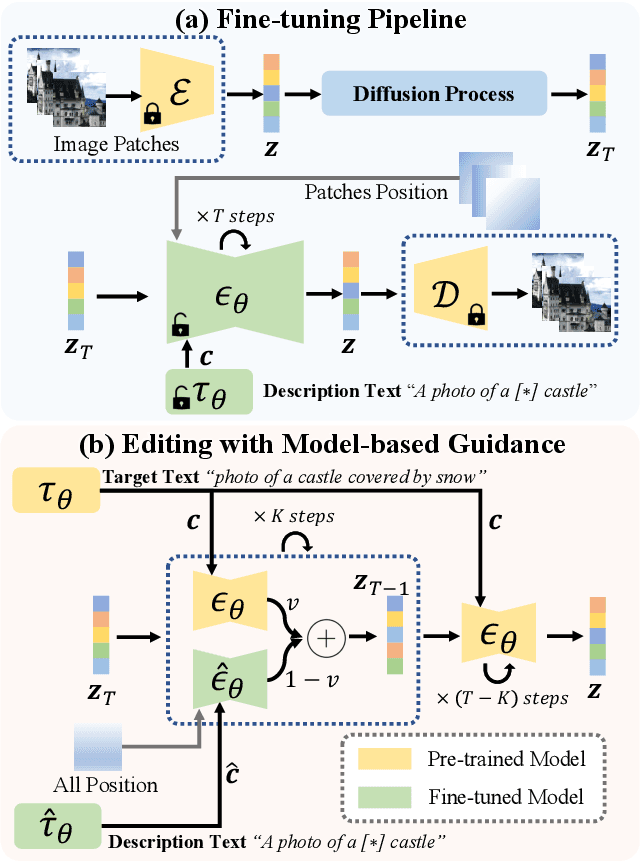
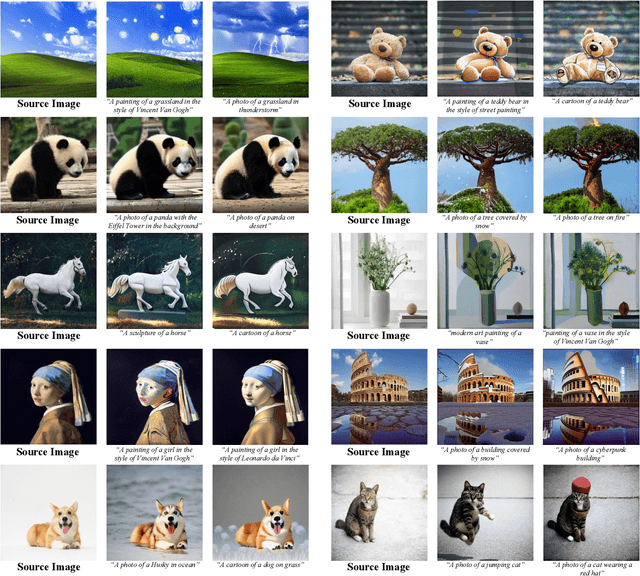
Recent works on diffusion models have demonstrated a strong capability for conditioning image generation, e.g., text-guided image synthesis. Such success inspires many efforts trying to use large-scale pre-trained diffusion models for tackling a challenging problem--real image editing. Works conducted in this area learn a unique textual token corresponding to several images containing the same object. However, under many circumstances, only one image is available, such as the painting of the Girl with a Pearl Earring. Using existing works on fine-tuning the pre-trained diffusion models with a single image causes severe overfitting issues. The information leakage from the pre-trained diffusion models makes editing can not keep the same content as the given image while creating new features depicted by the language guidance. This work aims to address the problem of single-image editing. We propose a novel model-based guidance built upon the classifier-free guidance so that the knowledge from the model trained on a single image can be distilled into the pre-trained diffusion model, enabling content creation even with one given image. Additionally, we propose a patch-based fine-tuning that can effectively help the model generate images of arbitrary resolution. We provide extensive experiments to validate the design choices of our approach and show promising editing capabilities, including changing style, content addition, and object manipulation. The code is available for research purposes at https://github.com/zhang-zx/SINE.git .
STEER: Simple Temporal Regularization For Neural ODEs
Jul 01, 2020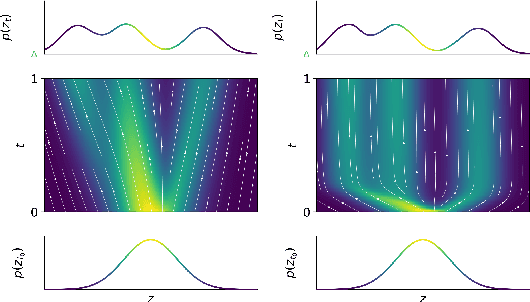
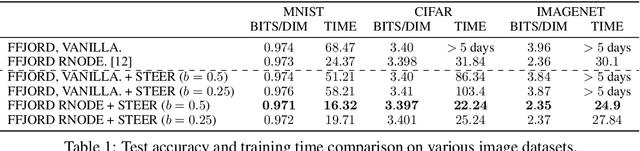
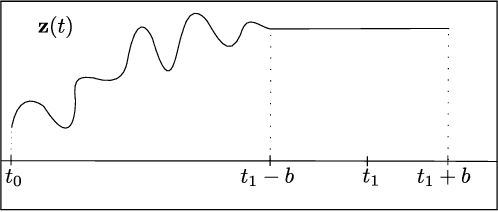
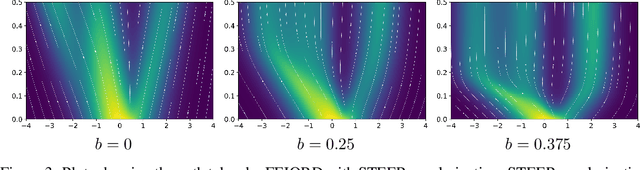
Training Neural Ordinary Differential Equations (ODEs) is often computationally expensive. Indeed, computing the forward pass of such models involves solving an ODE which can become arbitrarily complex during training. Recent works have shown that regularizing the dynamics of the ODE can partially alleviate this. In this paper we propose a new regularization technique: randomly sampling the end time of the ODE during training. The proposed regularization is simple to implement, has negligible overhead and is effective across a wide variety of tasks. Further, the technique is orthogonal to several other methods proposed to regularize the dynamics of ODEs and as such can be used in conjunction with them. We show through experiments on normalizing flows, time series models and image recognition that the proposed regularization can significantly decrease training time and even improve performance over baseline models.
Interactive Sketch & Fill: Multiclass Sketch-to-Image Translation
Sep 25, 2019


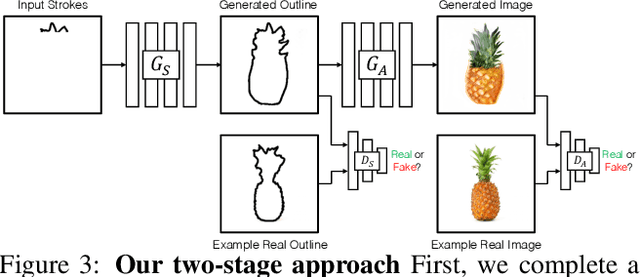
We propose an interactive GAN-based sketch-to-image translation method that helps novice users create images of simple objects. As the user starts to draw a sketch of a desired object type, the network interactively recommends plausible completions, and shows a corresponding synthesized image to the user. This enables a feedback loop, where the user can edit their sketch based on the network's recommendations, visualizing both the completed shape and final rendered image while they draw. In order to use a single trained model across a wide array of object classes, we introduce a gating-based approach for class conditioning, which allows us to generate distinct classes without feature mixing, from a single generator network. Video available at our website: https://arnabgho.github.io/iSketchNFill/.
Multi-Agent Diverse Generative Adversarial Networks
Jul 16, 2018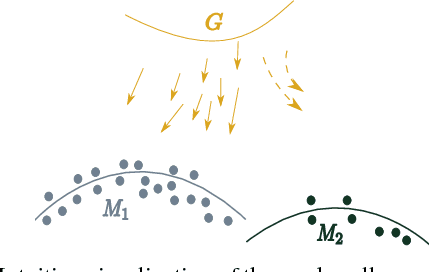
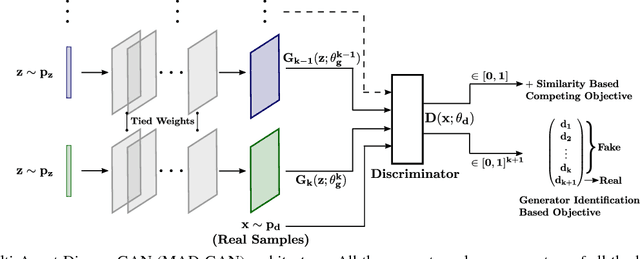

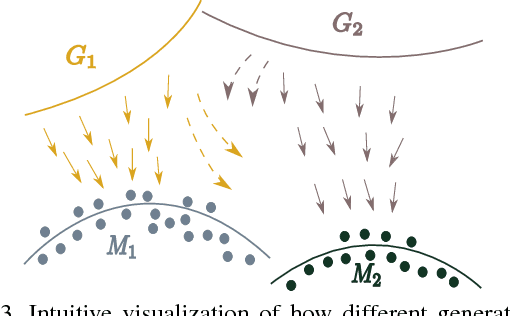
We propose MAD-GAN, an intuitive generalization to the Generative Adversarial Networks (GANs) and its conditional variants to address the well known problem of mode collapse. First, MAD-GAN is a multi-agent GAN architecture incorporating multiple generators and one discriminator. Second, to enforce that different generators capture diverse high probability modes, the discriminator of MAD-GAN is designed such that along with finding the real and fake samples, it is also required to identify the generator that generated the given fake sample. Intuitively, to succeed in this task, the discriminator must learn to push different generators towards different identifiable modes. We perform extensive experiments on synthetic and real datasets and compare MAD-GAN with different variants of GAN. We show high quality diverse sample generations for challenging tasks such as image-to-image translation and face generation. In addition, we also show that MAD-GAN is able to disentangle different modalities when trained using highly challenging diverse-class dataset (e.g. dataset with images of forests, icebergs, and bedrooms). In the end, we show its efficacy on the unsupervised feature representation task. In Appendix, we introduce a similarity based competing objective (MAD-GAN-Sim) which encourages different generators to generate diverse samples based on a user defined similarity metric. We show its performance on the image-to-image translation, and also show its effectiveness on the unsupervised feature representation task.
DGPose: Disentangled Semi-supervised Deep Generative Models for Human Body Analysis
Apr 17, 2018
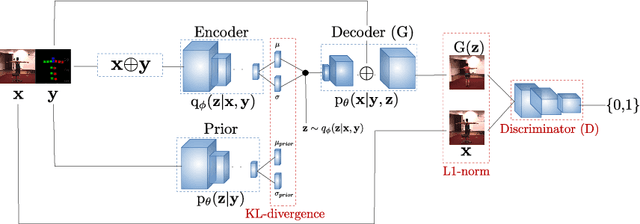
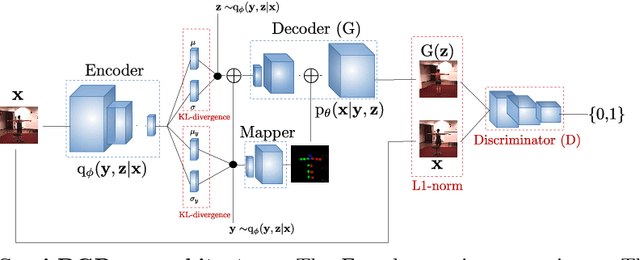
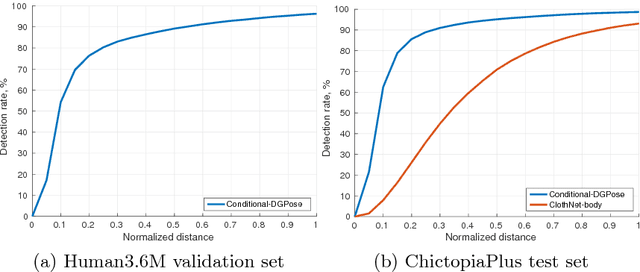
Deep generative modelling for robust human body analysis is an emerging problem with many interesting applications, since it enables analysis-by-synthesis and unsupervised learning. However, the latent space learned by such models is typically not human-interpretable, resulting in less flexible models. In this work, we adopt a structured semi-supervised variational auto-encoder approach and present a deep generative model for human body analysis where the pose and appearance are disentangled in the latent space, allowing for pose estimation. Such a disentanglement allows independent manipulation of pose and appearance and hence enables applications such as pose-transfer without being explicitly trained for such a task. In addition, the ability to train in a semi-supervised setting relaxes the need for labelled data. We demonstrate the merits of our generative model on the Human3.6M and ChictopiaPlus datasets.
Contextual RNN-GANs for Abstract Reasoning Diagram Generation
Dec 06, 2016
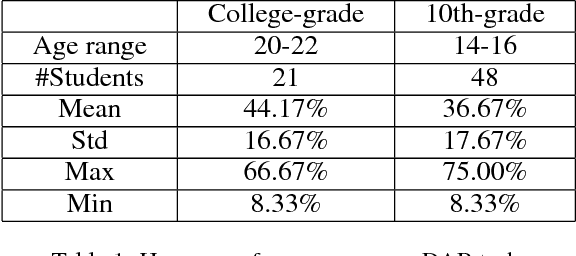
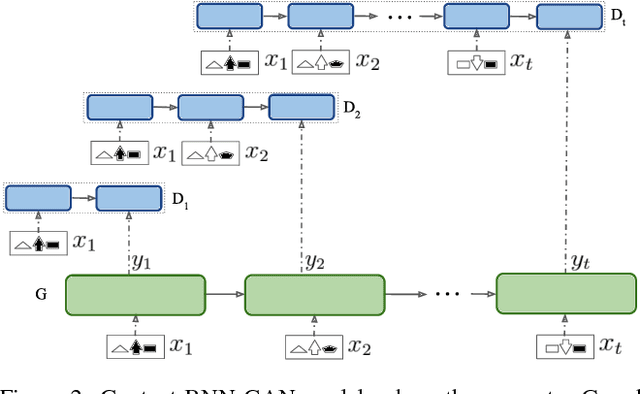
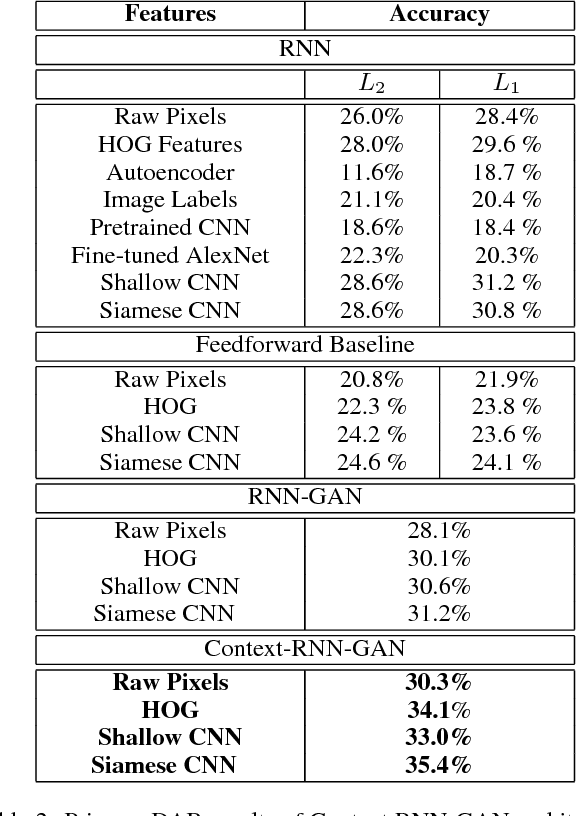
Understanding, predicting, and generating object motions and transformations is a core problem in artificial intelligence. Modeling sequences of evolving images may provide better representations and models of motion and may ultimately be used for forecasting, simulation, or video generation. Diagrammatic Abstract Reasoning is an avenue in which diagrams evolve in complex patterns and one needs to infer the underlying pattern sequence and generate the next image in the sequence. For this, we develop a novel Contextual Generative Adversarial Network based on Recurrent Neural Networks (Context-RNN-GANs), where both the generator and the discriminator modules are based on contextual history (modeled as RNNs) and the adversarial discriminator guides the generator to produce realistic images for the particular time step in the image sequence. We evaluate the Context-RNN-GAN model (and its variants) on a novel dataset of Diagrammatic Abstract Reasoning, where it performs competitively with 10th-grade human performance but there is still scope for interesting improvements as compared to college-grade human performance. We also evaluate our model on a standard video next-frame prediction task, achieving improved performance over comparable state-of-the-art.
Message Passing Multi-Agent GANs
Dec 05, 2016
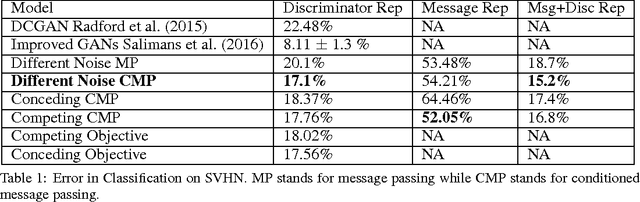


Communicating and sharing intelligence among agents is an important facet of achieving Artificial General Intelligence. As a first step towards this challenge, we introduce a novel framework for image generation: Message Passing Multi-Agent Generative Adversarial Networks (MPM GANs). While GANs have recently been shown to be very effective for image generation and other tasks, these networks have been limited to mostly single generator-discriminator networks. We show that we can obtain multi-agent GANs that communicate through message passing to achieve better image generation. The objectives of the individual agents in this framework are two fold: a co-operation objective and a competing objective. The co-operation objective ensures that the message sharing mechanism guides the other generator to generate better than itself while the competing objective encourages each generator to generate better than its counterpart. We analyze and visualize the messages that these GANs share among themselves in various scenarios. We quantitatively show that the message sharing formulation serves as a regularizer for the adversarial training. Qualitatively, we show that the different generators capture different traits of the underlying data distribution.
An Evolutionary Approach to Drug-Design Using a Novel Neighbourhood Based Genetic Algorithm
May 03, 2012
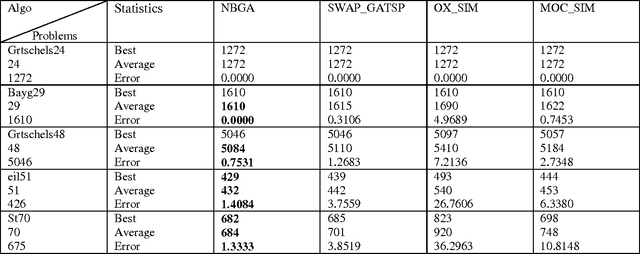
The present work provides a new approach to evolve ligand structures which represent possible drug to be docked to the active site of the target protein. The structure is represented as a tree where each non-empty node represents a functional group. It is assumed that the active site configuration of the target protein is known with position of the essential residues. In this paper the interaction energy of the ligands with the protein target is minimized. Moreover, the size of the tree is difficult to obtain and it will be different for different active sites. To overcome the difficulty, a variable tree size configuration is used for designing ligands. The optimization is done using a novel Neighbourhood Based Genetic Algorithm (NBGA) which uses dynamic neighbourhood topology. To get variable tree size, a variable-length version of the above algorithm is devised. To judge the merit of the algorithm, it is initially applied on the well known Travelling Salesman Problem (TSP).
Multi-robot Cooperative Box-pushing problem using Multi-objective Particle Swarm Optimization Technique
May 03, 2012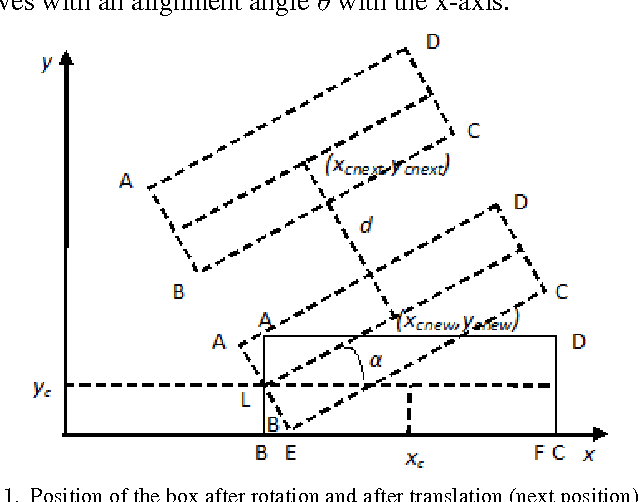
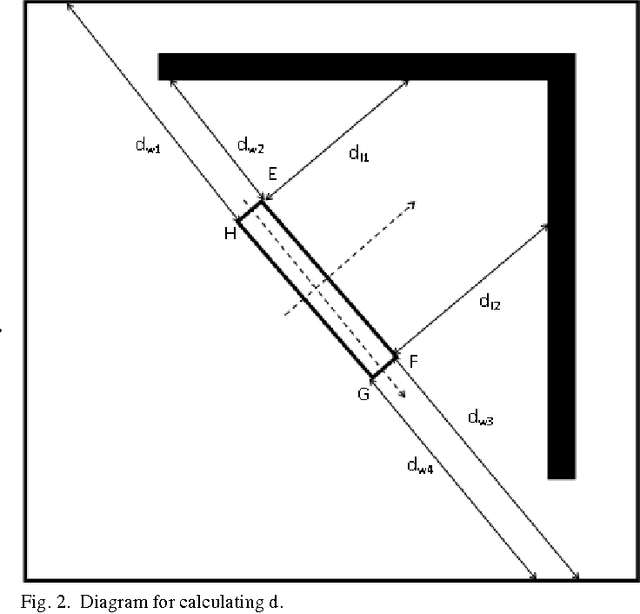
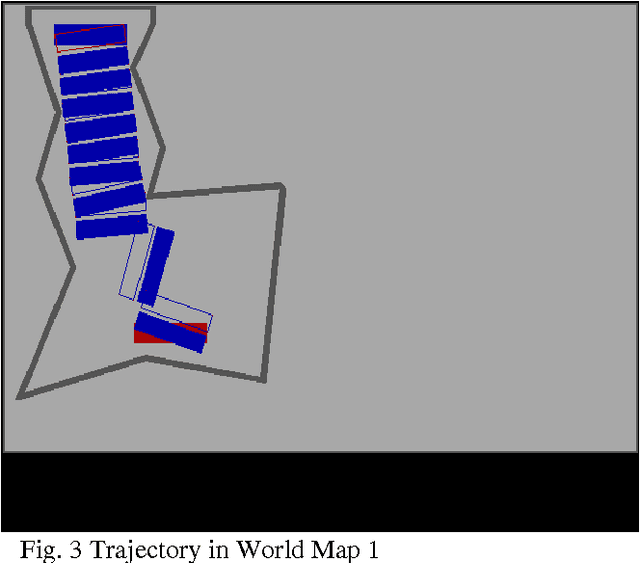
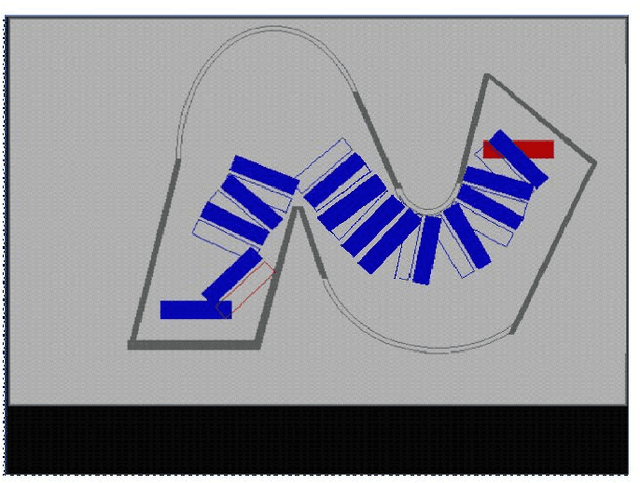
The present work provides a new approach to solve the well-known multi-robot co-operative box pushing problem as a multi objective optimization problem using modified Multi-objective Particle Swarm Optimization. The method proposed here allows both turning and translation of the box, during shift to a desired goal position. We have employed local planning scheme to determine the magnitude of the forces applied by the two mobile robots perpendicularly at specific locations on the box to align and translate it in each distinct step of motion of the box, for minimization of both time and energy. Finally the results are compared with the results obtained by solving the same problem using Non-dominated Sorting Genetic Algorithm-II (NSGA-II). The proposed scheme is found to give better results compared to NSGA-II.
An Evolutionary Approach to Drug-Design Using Quantam Binary Particle Swarm Optimization Algorithm
May 03, 2012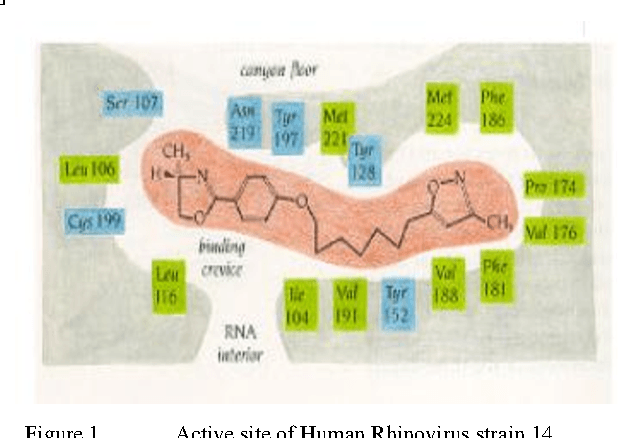
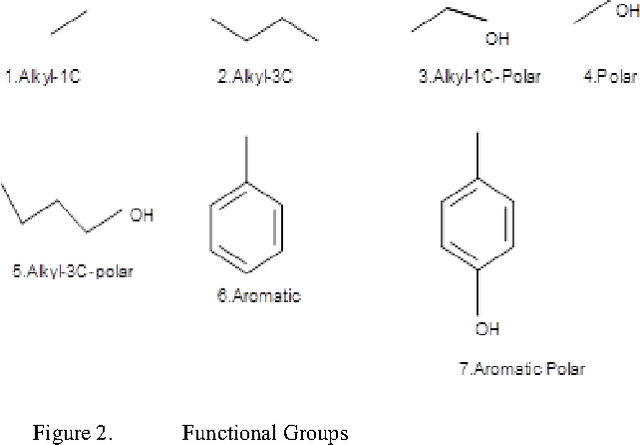
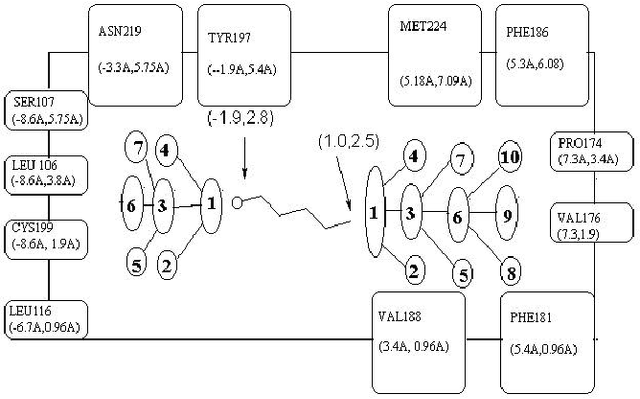
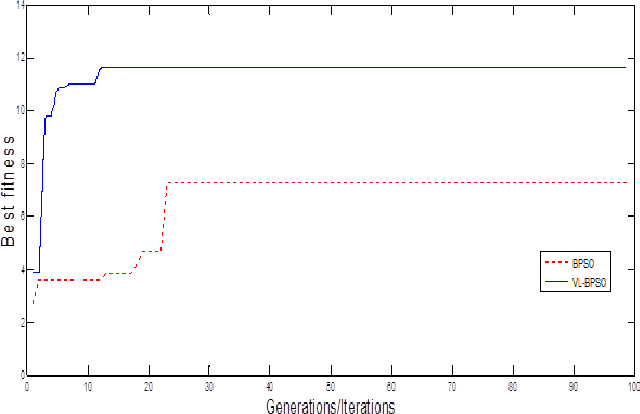
The present work provides a new approach to evolve ligand structures which represent possible drug to be docked to the active site of the target protein. The structure is represented as a tree where each non-empty node represents a functional group. It is assumed that the active site configuration of the target protein is known with position of the essential residues. In this paper the interaction energy of the ligands with the protein target is minimized. Moreover, the size of the tree is difficult to obtain and it will be different for different active sites. To overcome the difficulty, a variable tree size configuration is used for designing ligands. The optimization is done using a quantum discrete PSO. The result using fixed length and variable length configuration are compared.