 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDGPose: Disentangled Semi-supervised Deep Generative Models for Human Body Analysis
Paper and Code
Apr 17, 2018
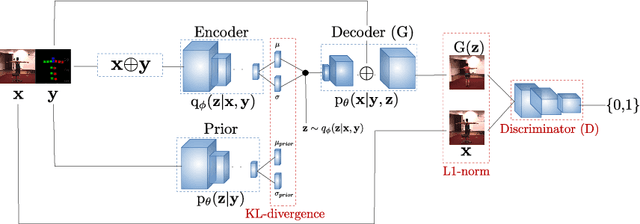
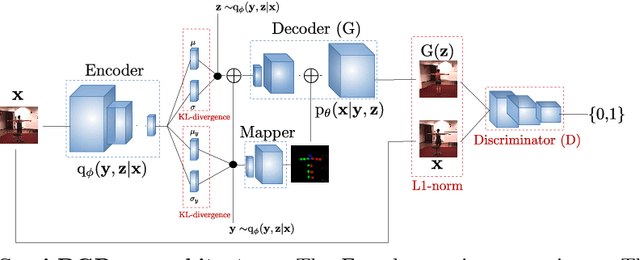
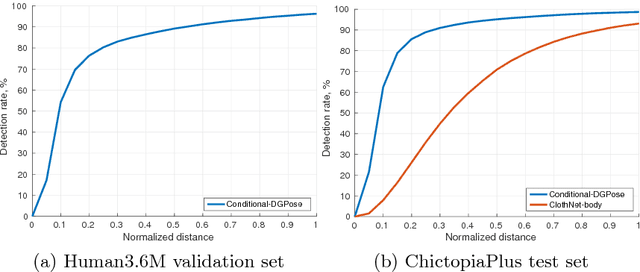
Deep generative modelling for robust human body analysis is an emerging problem with many interesting applications, since it enables analysis-by-synthesis and unsupervised learning. However, the latent space learned by such models is typically not human-interpretable, resulting in less flexible models. In this work, we adopt a structured semi-supervised variational auto-encoder approach and present a deep generative model for human body analysis where the pose and appearance are disentangled in the latent space, allowing for pose estimation. Such a disentanglement allows independent manipulation of pose and appearance and hence enables applications such as pose-transfer without being explicitly trained for such a task. In addition, the ability to train in a semi-supervised setting relaxes the need for labelled data. We demonstrate the merits of our generative model on the Human3.6M and ChictopiaPlus datasets.