 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBanyan: Improved Representation Learning with Explicit Structure
Jul 25, 2024



We present Banyan, an improved model to learn semantic representations by inducing explicit structure over data. In contrast to prior approaches using structure spanning single sentences, Banyan learns by resolving multiple constituent structures into a shared one explicitly incorporating global context. Combined with an improved message-passing scheme inspired by Griffin, Banyan learns significantly better representations, avoids spurious false negatives with contrastive learning, and drastically improves memory efficiency in such explicit-structured models. Using the Self-StrAE framework, we show that Banyan (a) outperforms baselines using sentential structure across various settings (b) matches or outperforms unstructured baselines like GloVe (+augmentations) and a RoBERTa medium (+simcse) pre-trained on 100M tokens, despite having just a handful of (non-embedding) parameters, and (c) also learns effective representations across several low resource (Asian and African) languages as measured on SemRel tasks.
Multi-Label Classification for Implicit Discourse Relation Recognition
Jun 06, 2024Discourse relations play a pivotal role in establishing coherence within textual content, uniting sentences and clauses into a cohesive narrative. The Penn Discourse Treebank (PDTB) stands as one of the most extensively utilized datasets in this domain. In PDTB-3, the annotators can assign multiple labels to an example, when they believe that multiple relations are present. Prior research in discourse relation recognition has treated these instances as separate examples during training, and only one example needs to have its label predicted correctly for the instance to be judged as correct. However, this approach is inadequate, as it fails to account for the interdependence of labels in real-world contexts and to distinguish between cases where only one sense relation holds and cases where multiple relations hold simultaneously. In our work, we address this challenge by exploring various multi-label classification frameworks to handle implicit discourse relation recognition. We show that multi-label classification methods don't depress performance for single-label prediction. Additionally, we give comprehensive analysis of results and data. Our work contributes to advancing the understanding and application of discourse relations and provide a foundation for the future study
Self-StrAE at SemEval-2024 Task 1: Making Self-Structuring AutoEncoders Learn More With Less
Apr 02, 2024This paper presents two simple improvements to the Self-Structuring AutoEncoder (Self-StrAE). Firstly, we show that including reconstruction to the vocabulary as an auxiliary objective improves representation quality. Secondly, we demonstrate that increasing the number of independent channels leads to significant improvements in embedding quality, while simultaneously reducing the number of parameters. Surprisingly, we demonstrate that this trend can be followed to the extreme, even to point of reducing the total number of non-embedding parameters to seven. Our system can be pre-trained from scratch with as little as 10M tokens of input data, and proves effective across English, Spanish and Afrikaans.
On the effect of curriculum learning with developmental data for grammar acquisition
Nov 03, 2023This work explores the degree to which grammar acquisition is driven by language `simplicity' and the source modality (speech vs. text) of data. Using BabyBERTa as a probe, we find that grammar acquisition is largely driven by exposure to speech data, and in particular through exposure to two of the BabyLM training corpora: AO-Childes and Open Subtitles. We arrive at this finding by examining various ways of presenting input data to our model. First, we assess the impact of various sequence-level complexity based curricula. We then examine the impact of learning over `blocks' -- covering spans of text that are balanced for the number of tokens in each of the source corpora (rather than number of lines). Finally, we explore curricula that vary the degree to which the model is exposed to different corpora. In all cases, we find that over-exposure to AO-Childes and Open Subtitles significantly drives performance. We verify these findings through a comparable control dataset in which exposure to these corpora, and speech more generally, is limited by design. Our findings indicate that it is not the proportion of tokens occupied by high-utility data that aids acquisition, but rather the proportion of training steps assigned to such data. We hope this encourages future research into the use of more developmentally plausible linguistic data (which tends to be more scarce) to augment general purpose pre-training regimes.
DreamDecompiler: Improved Bayesian Program Learning by Decompiling Amortised Knowledge
Jun 13, 2023Solving program induction problems requires searching through an enormous space of possibilities. DreamCoder is an inductive program synthesis system that, whilst solving problems, learns to simplify search in an iterative wake-sleep procedure. The cost of search is amortised by training a neural search policy, reducing search breadth and effectively "compiling" useful information to compose program solutions across tasks. Additionally, a library of program components is learnt to express discovered solutions in fewer components, reducing search depth. In DreamCoder, the neural search policy has only an indirect effect on the library learnt through the program solutions it helps discover. We present an approach for library learning that directly leverages the neural search policy, effectively "decompiling" its amortised knowledge to extract relevant program components. This provides stronger amortised inference: the amortised knowledge learnt to reduce search breadth is now also used to reduce search depth. We integrate our approach with DreamCoder and demonstrate faster domain proficiency with improved generalisation on a range of domains, particularly when fewer example solutions are available.
Autoencoding Conditional Neural Processes for Representation Learning
May 29, 2023
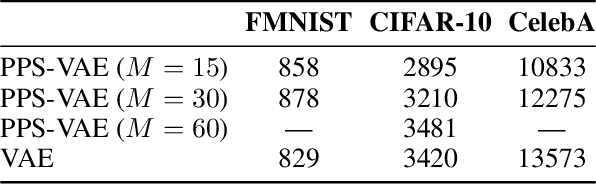
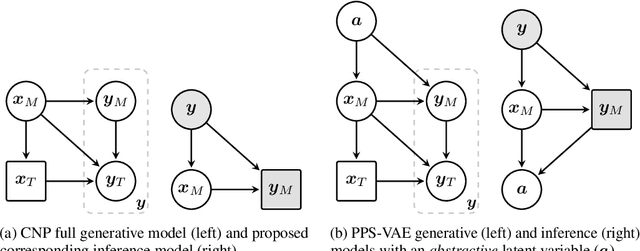
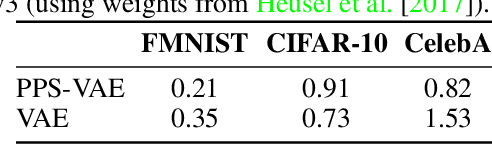
Conditional neural processes (CNPs) are a flexible and efficient family of models that learn to learn a stochastic process from observations. In the visual domain, they have seen particular application in contextual image completion - observing pixel values at some locations to predict a distribution over values at other unobserved locations. However, the choice of pixels in learning such a CNP is typically either random or derived from a simple statistical measure (e.g. pixel variance). Here, we turn the problem on its head and ask: which pixels would a CNP like to observe? That is, which pixels allow fitting CNP, and do such pixels tell us something about the underlying image? Viewing the context provided to the CNP as fixed-size latent representations, we construct an amortised variational framework, Partial Pixel Space Variational Autoencoder (PPS-VAE), for predicting this context simultaneously with learning a CNP. We evaluate PPS-VAE on a set of vision datasets, and find that not only is it possible to learn context points while also fitting CNPs, but that their spatial arrangement and values provides strong signal for the information contained in the image - evaluated through the lens of classification. We believe the PPS-VAE provides a promising avenue to explore learning interpretable and effective visual representations.
StrAE: Autoencoding for Pre-Trained Embeddings using Explicit Structure
May 09, 2023This work explores the utility of explicit structure for representation learning in NLP by developing StrAE -- an autoencoding framework that faithfully leverages sentence structure to learn multi-level node embeddings in an unsupervised fashion. We use StrAE to train models across different types of sentential structure and objectives, including a novel contrastive loss over structure, and evaluate the learnt embeddings on a series of both intrinsic and extrinsic tasks. Our experiments indicate that leveraging explicit structure through StrAE leads to improved embeddings over prior work, and that our novel contrastive objective over structure outperforms the standard cross-entropy objective. Moreover, in contrast to findings from prior work that weakly leverages structure, we find that being completely faithful to structure does enable disambiguation between types of structure based on the corresponding model's performance. As further evidence of StrAE's utility, we develop a simple proof-of-concept approach to simultaneously induce structure while learning embeddings, rather than being given structure, and find that performance is comparable to that of the best-performing models where structure is given. Finally, we contextualise these results by comparing StrAE against standard unstructured baselines learnt in similar settings, and show that faithfully leveraging explicit structure can be beneficial in lexical and sentence-level semantics.
Drawing out of Distribution with Neuro-Symbolic Generative Models
Jun 03, 2022
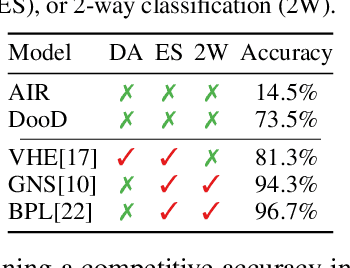
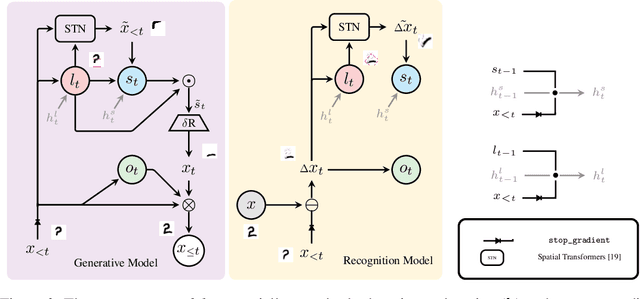
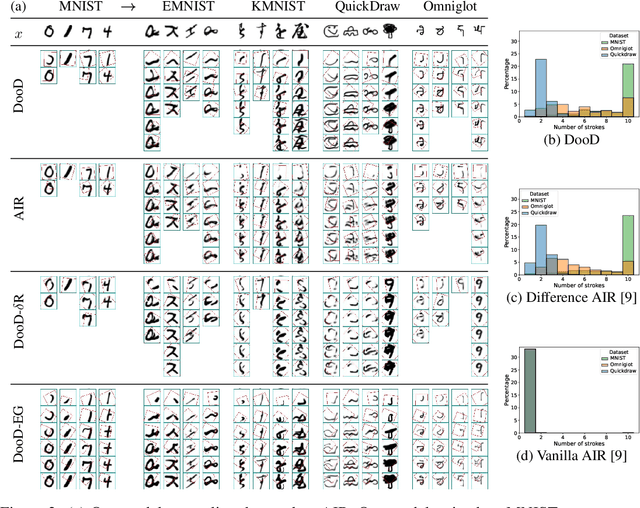
Learning general-purpose representations from perceptual inputs is a hallmark of human intelligence. For example, people can write out numbers or characters, or even draw doodles, by characterizing these tasks as different instantiations of the same generic underlying process -- compositional arrangements of different forms of pen strokes. Crucially, learning to do one task, say writing, implies reasonable competence at another, say drawing, on account of this shared process. We present Drawing out of Distribution (DooD), a neuro-symbolic generative model of stroke-based drawing that can learn such general-purpose representations. In contrast to prior work, DooD operates directly on images, requires no supervision or expensive test-time inference, and performs unsupervised amortised inference with a symbolic stroke model that better enables both interpretability and generalization. We evaluate DooD on its ability to generalise across both data and tasks. We first perform zero-shot transfer from one dataset (e.g. MNIST) to another (e.g. Quickdraw), across five different datasets, and show that DooD clearly outperforms different baselines. An analysis of the learnt representations further highlights the benefits of adopting a symbolic stroke model. We then adopt a subset of the Omniglot challenge tasks, and evaluate its ability to generate new exemplars (both unconditionally and conditionally), and perform one-shot classification, showing that DooD matches the state of the art. Taken together, we demonstrate that DooD does indeed capture general-purpose representations across both data and task, and takes a further step towards building general and robust concept-learning systems.
Adversarial Masking for Self-Supervised Learning
Jan 31, 2022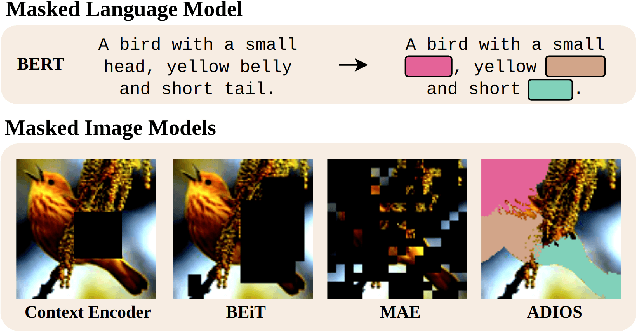
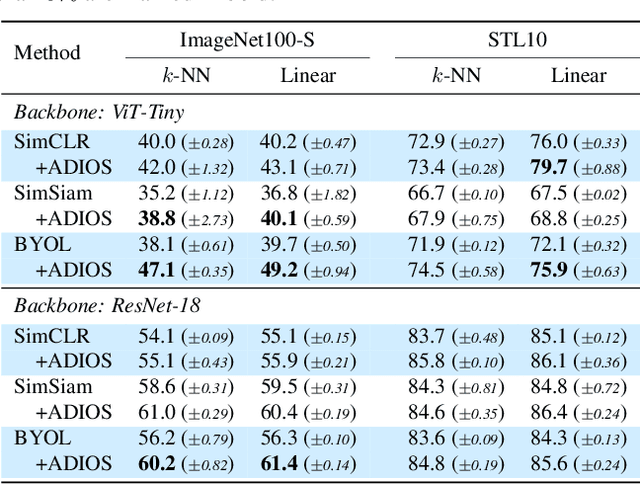

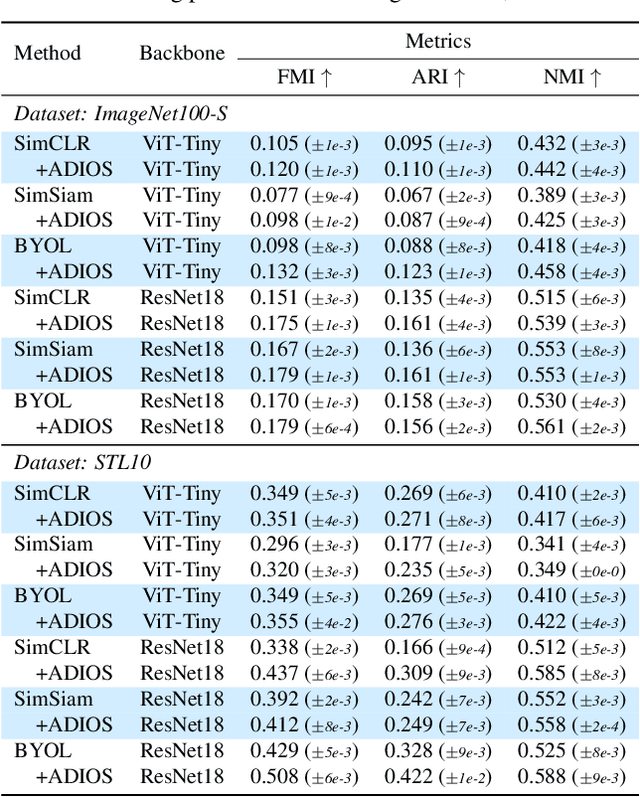
We propose ADIOS, a masked image model (MIM) framework for self-supervised learning, which simultaneously learns a masking function and an image encoder using an adversarial objective. The image encoder is trained to minimise the distance between representations of the original and that of a masked image. The masking function, conversely, aims at maximising this distance. ADIOS consistently improves on state-of-the-art self-supervised learning (SSL) methods on a variety of tasks and datasets -- including classification on ImageNet100 and STL10, transfer learning on CIFAR10/100, Flowers102 and iNaturalist, as well as robustness evaluated on the backgrounds challenge (Xiao et al., 2021) -- while generating semantically meaningful masks. Unlike modern MIM models such as MAE, BEiT and iBOT, ADIOS does not rely on the image-patch tokenisation construction of Vision Transformers, and can be implemented with convolutional backbones. We further demonstrate that the masks learned by ADIOS are more effective in improving representation learning of SSL methods than masking schemes used in popular MIM models.
Learning Multimodal VAEs through Mutual Supervision
Jul 01, 2021

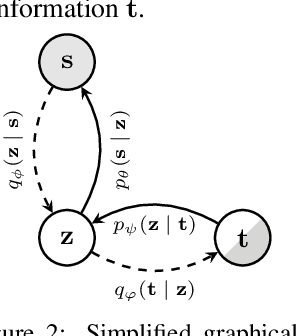

Multimodal VAEs seek to model the joint distribution over heterogeneous data (e.g.\ vision, language), whilst also capturing a shared representation across such modalities. Prior work has typically combined information from the modalities by reconciling idiosyncratic representations directly in the recognition model through explicit products, mixtures, or other such factorisations. Here we introduce a novel alternative, the MEME, that avoids such explicit combinations by repurposing semi-supervised VAEs to combine information between modalities implicitly through mutual supervision. This formulation naturally allows learning from partially-observed data where some modalities can be entirely missing -- something that most existing approaches either cannot handle, or do so to a limited extent. We demonstrate that MEME outperforms baselines on standard metrics across both partial and complete observation schemes on the MNIST-SVHN (image-image) and CUB (image-text) datasets. We also contrast the quality of the representations learnt by mutual supervision against standard approaches and observe interesting trends in its ability to capture relatedness between data.