 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaser: Latent Set Representations for 3D Generative Modeling
Jan 13, 2023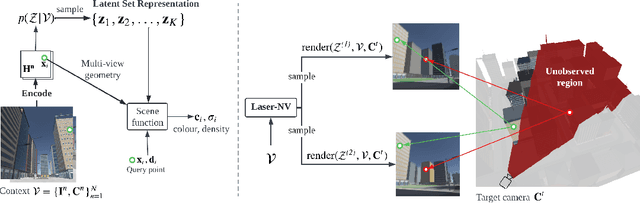
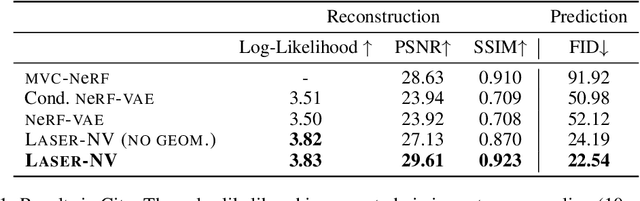


NeRF provides unparalleled fidelity of novel view synthesis: rendering a 3D scene from an arbitrary viewpoint. NeRF requires training on a large number of views that fully cover a scene, which limits its applicability. While these issues can be addressed by learning a prior over scenes in various forms, previous approaches have been either applied to overly simple scenes or struggling to render unobserved parts. We introduce Laser-NV: a generative model which achieves high modelling capacity, and which is based on a set-valued latent representation modelled by normalizing flows. Similarly to previous amortized approaches, Laser-NV learns structure from multiple scenes and is capable of fast, feed-forward inference from few views. To encourage higher rendering fidelity and consistency with observed views, Laser-NV further incorporates a geometry-informed attention mechanism over the observed views. Laser-NV further produces diverse and plausible completions of occluded parts of a scene while remaining consistent with observations. Laser-NV shows state-of-the-art novel-view synthesis quality when evaluated on ShapeNet and on a novel simulated City dataset, which features high uncertainty in the unobserved regions of the scene.
Adversarial Masking for Self-Supervised Learning
Jan 31, 2022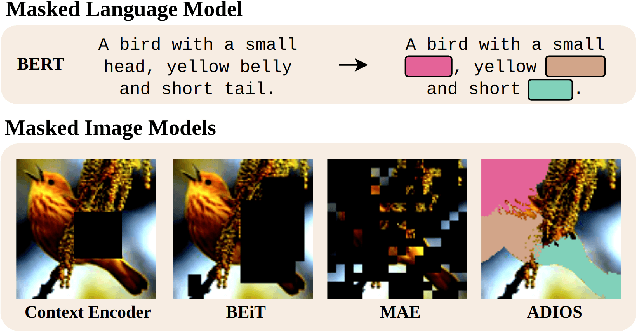
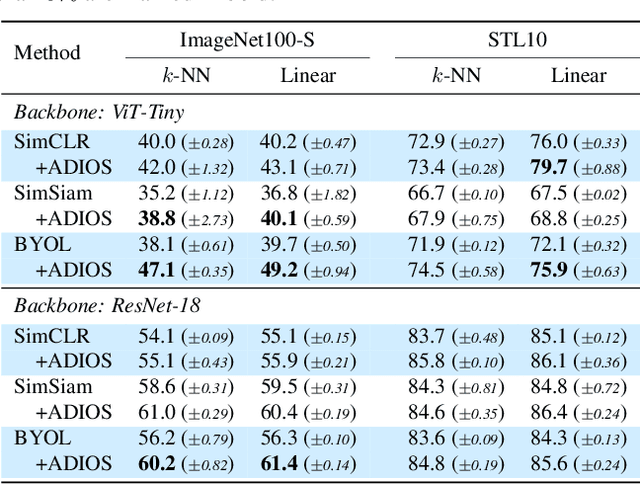

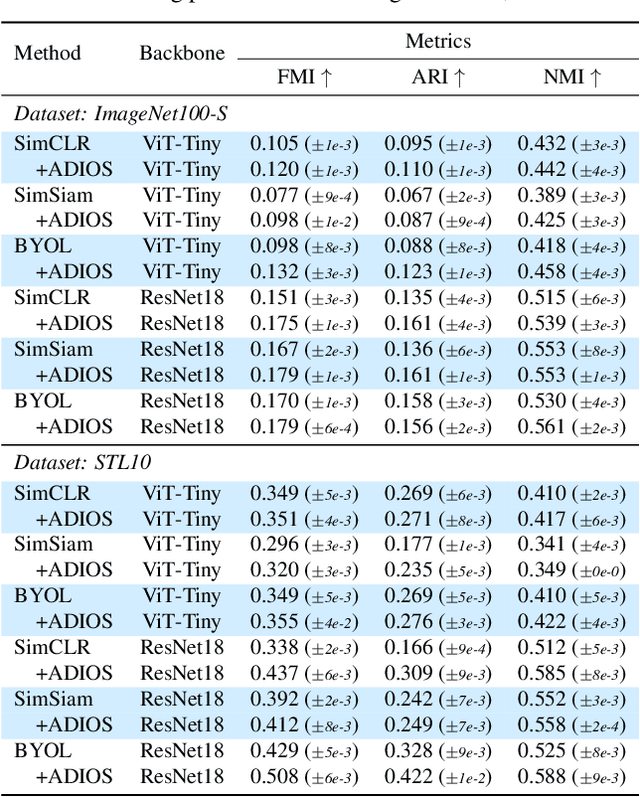
We propose ADIOS, a masked image model (MIM) framework for self-supervised learning, which simultaneously learns a masking function and an image encoder using an adversarial objective. The image encoder is trained to minimise the distance between representations of the original and that of a masked image. The masking function, conversely, aims at maximising this distance. ADIOS consistently improves on state-of-the-art self-supervised learning (SSL) methods on a variety of tasks and datasets -- including classification on ImageNet100 and STL10, transfer learning on CIFAR10/100, Flowers102 and iNaturalist, as well as robustness evaluated on the backgrounds challenge (Xiao et al., 2021) -- while generating semantically meaningful masks. Unlike modern MIM models such as MAE, BEiT and iBOT, ADIOS does not rely on the image-patch tokenisation construction of Vision Transformers, and can be implemented with convolutional backbones. We further demonstrate that the masks learned by ADIOS are more effective in improving representation learning of SSL methods than masking schemes used in popular MIM models.
Decomposing 3D Scenes into Objects via Unsupervised Volume Segmentation
Apr 02, 2021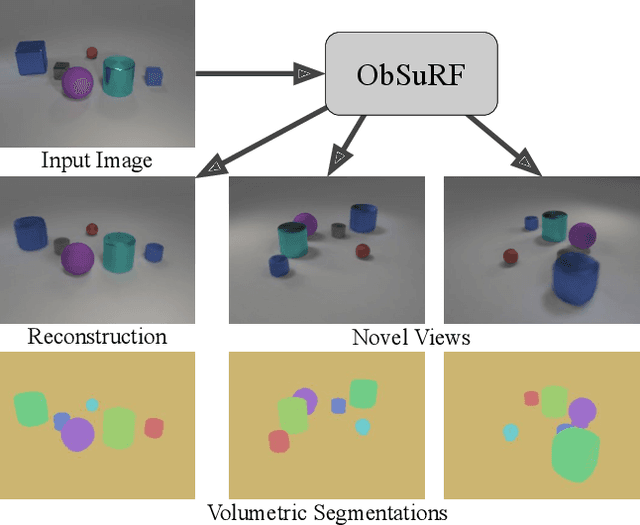
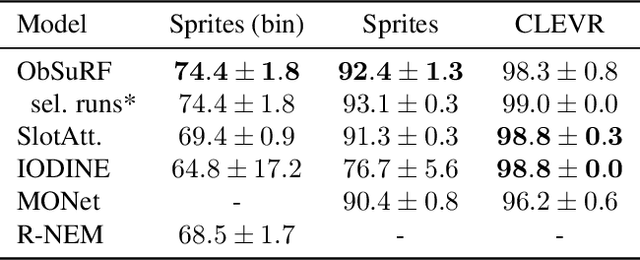
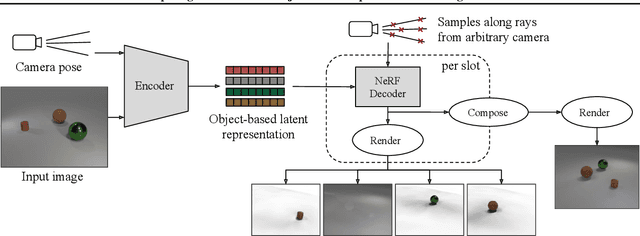

We present ObSuRF, a method which turns a single image of a scene into a 3D model represented as a set of Neural Radiance Fields (NeRFs), with each NeRF corresponding to a different object. A single forward pass of an encoder network outputs a set of latent vectors describing the objects in the scene. These vectors are used independently to condition a NeRF decoder, defining the geometry and appearance of each object. We make learning more computationally efficient by deriving a novel loss, which allows training NeRFs on RGB-D inputs without explicit ray marching. After confirming that the model performs equal or better than state of the art on three 2D image segmentation benchmarks, we apply it to two multi-object 3D datasets: A multiview version of CLEVR, and a novel dataset in which scenes are populated by ShapeNet models. We find that after training ObSuRF on RGB-D views of training scenes, it is capable of not only recovering the 3D geometry of a scene depicted in a single input image, but also to segment it into objects, despite receiving no supervision in that regard.
NeRF-VAE: A Geometry Aware 3D Scene Generative Model
Apr 01, 2021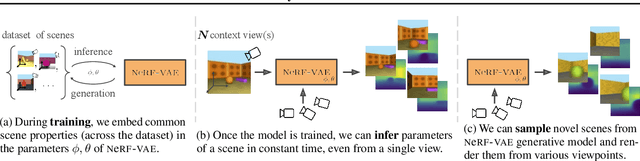

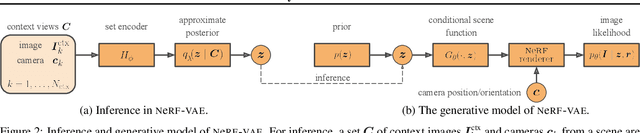
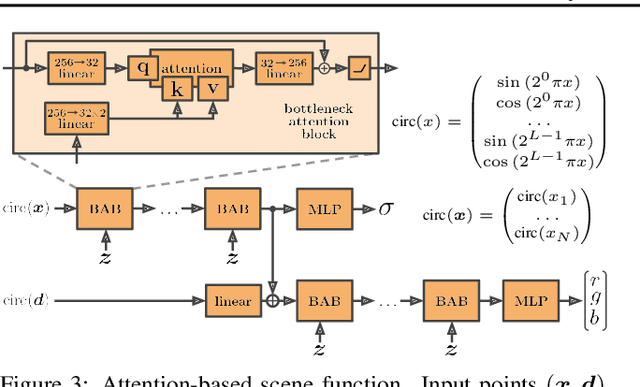
We propose NeRF-VAE, a 3D scene generative model that incorporates geometric structure via NeRF and differentiable volume rendering. In contrast to NeRF, our model takes into account shared structure across scenes, and is able to infer the structure of a novel scene -- without the need to re-train -- using amortized inference. NeRF-VAE's explicit 3D rendering process further contrasts previous generative models with convolution-based rendering which lacks geometric structure. Our model is a VAE that learns a distribution over radiance fields by conditioning them on a latent scene representation. We show that, once trained, NeRF-VAE is able to infer and render geometrically-consistent scenes from previously unseen 3D environments using very few input images. We further demonstrate that NeRF-VAE generalizes well to out-of-distribution cameras, while convolutional models do not. Finally, we introduce and study an attention-based conditioning mechanism of NeRF-VAE's decoder, which improves model performance.
MetaFun: Meta-Learning with Iterative Functional Updates
Dec 05, 2019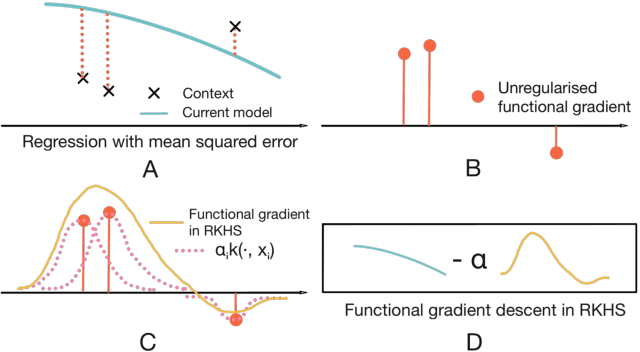
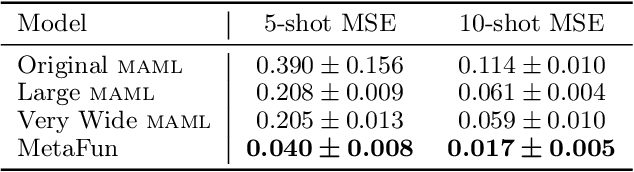
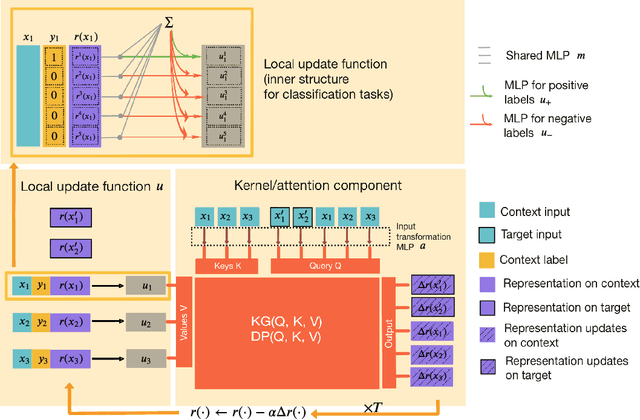
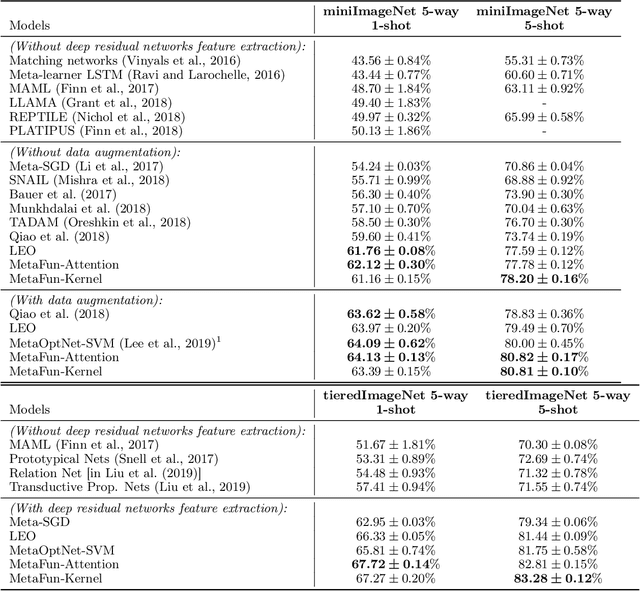
Few-shot supervised learning leverages experience from previous learning tasks to solve new tasks where only a few labelled examples are available. One successful line of approach to this problem is to use an encoder-decoder meta-learning pipeline, whereby labelled data in a task is encoded to produce task representation, and this representation is used to condition the decoder to make predictions on unlabelled data. We propose an approach that uses this pipeline with two important features. 1) We use infinite-dimensional functional representations of the task rather than fixed-dimensional representations. 2) We iteratively apply functional updates to the representation. We show that our approach can be interpreted as extending functional gradient descent, and delivers performance that is comparable to or outperforms previous state-of-the-art on few-shot classification benchmarks such as miniImageNet and tieredImageNet.
End-to-end Recurrent Multi-Object Tracking and Trajectory Prediction with Relational Reasoning
Aug 09, 2019
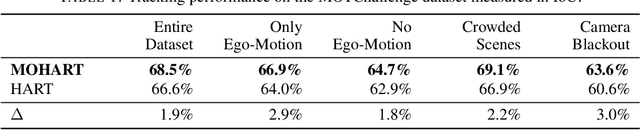

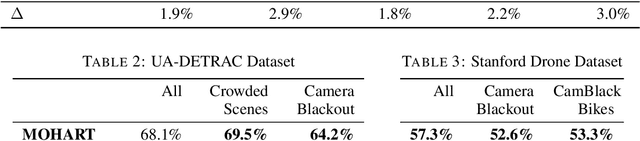
The majority of contemporary object-tracking approaches used in autonomous vehicles do not model interactions between objects. This contrasts with the fact that objects' paths are not independent: a cyclist might abruptly deviate from a previously planned trajectory in order to avoid colliding with a car. Building upon HART, a neural, class-agnostic single-object tracker, we introduce a multi-object tracking method MOHART capable of relational reasoning. Importantly, the entire system, including the understanding of interactions and relations between objects, is class-agnostic and learned simultaneously in an end-to-end fashion. We find that the addition of relational-reasoning capabilities to HART leads to consistent performance gains in tracking as well as future trajectory prediction on several real-world datasets (MOTChallenge, UA-DETRAC, and Stanford Drone dataset), particularly in the presence of ego-motion, occlusions, crowded scenes, and faulty sensor inputs. Finally, based on controlled simulations, we propose that a comparison of MOHART and HART may be used as a novel way to measure the degree to which the objects in a video depend upon each other as they move together through time.
GENESIS: Generative Scene Inference and Sampling with Object-Centric Latent Representations
Jul 30, 2019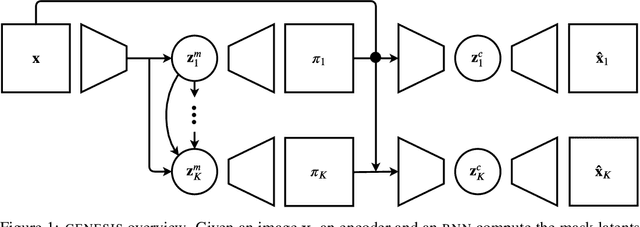
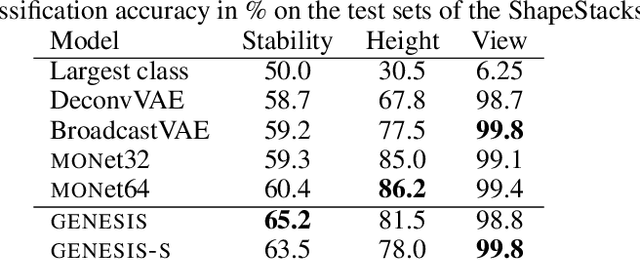
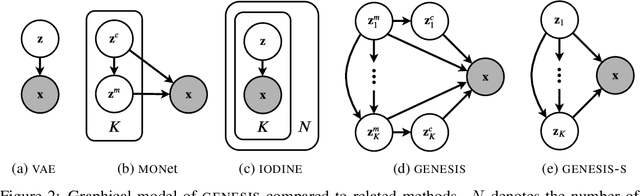

Generative models are emerging as promising tools in robotics and reinforcement learning. Yet, even though tasks in these domains typically involve distinct objects, most state-of-the-art methods do not explicitly capture the compositional nature of visual scenes. Two exceptions, MONet and IODINE, decompose scenes into objects in an unsupervised fashion via a set of latent variables. Their underlying generative processes, however, do not account for component interactions. Hence, neither of them allows for principled sampling of coherent scenes. Here we present GENESIS, the first object-centric generative model of visual scenes capable of both decomposing and generating complete scenes by explicitly capturing relationships between scene components. GENESIS parameterises a spatial GMM over pixels which is encoded by component-wise latent variables that are inferred sequentially or sampled from an autoregressive prior. We train GENESIS on two publicly available datasets and probe the information in the latent representations through a set of classification tasks, outperforming several baselines.
Stacked Capsule Autoencoders
Jun 17, 2019
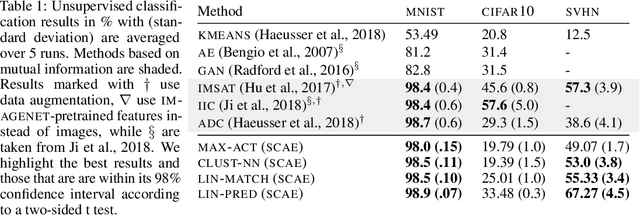

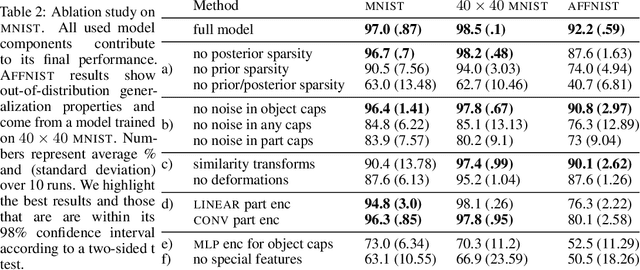
An object can be seen as a geometrically organized set of interrelated parts. A system that makes explicit use of these geometric relationships to recognize objects should be naturally robust to changes in viewpoint, because the intrinsic geometric relationships are viewpoint-invariant. We describe an unsupervised version of capsule networks, in which a neural encoder, which looks at all of the parts, is used to infer the presence and poses of object capsules. The encoder is trained by backpropagating through a decoder, which predicts the pose of each already discovered part using a mixture of pose predictions. The parts are discovered directly from an image, in a similar manner, by using a neural encoder, which infers parts and their affine transformations. The corresponding decoder models each image pixel as a mixture of predictions made by affine-transformed parts. We learn object- and their part-capsules on unlabeled data, and then cluster the vectors of presences of object capsules. When told the names of these clusters, we achieve state-of-the-art results for unsupervised classification on SVHN (55%) and near state-of-the-art on MNIST (98.5%).
Set Transformer
Oct 01, 2018
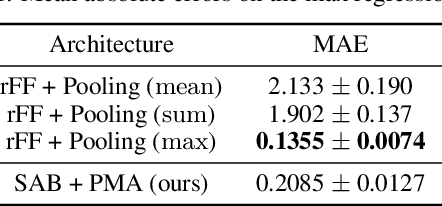

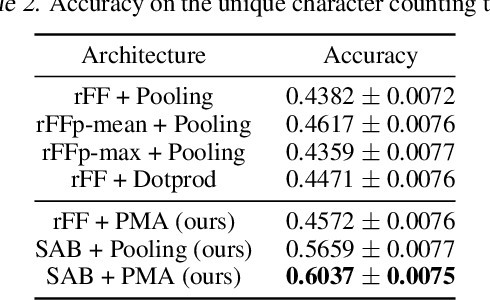
Many machine learning tasks such as multiple instance learning, 3D shape recognition and few-shot image classification are defined on sets of instances. Since solutions to such problems do not depend on the permutation of elements of the set, models used to address them should be permutation invariant. We present an attention-based neural network module, the Set Transformer, specifically designed to model interactions among elements in the input set. The model consists of an encoder and a decoder, both of which rely on attention mechanisms. In an effort to reduce computational complexity, we introduce an attention scheme inspired by inducing point methods from sparse Gaussian process literature. It reduces computation time of self-attention from quadratic to linear in the number of elements in the set. We show that our model is theoretically attractive and we evaluate it on a range of tasks, demonstrating increased performance compared to recent methods for set-structured data.
Tighter Variational Bounds are Not Necessarily Better
Jun 25, 2018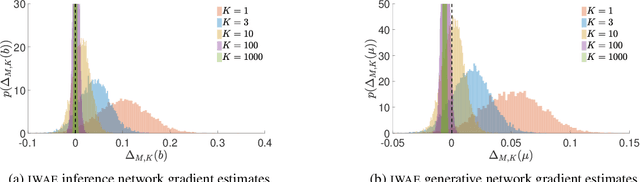

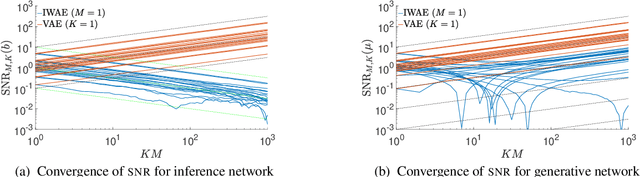
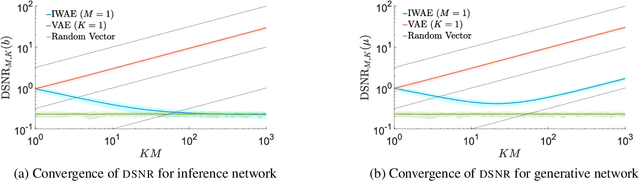
We provide theoretical and empirical evidence that using tighter evidence lower bounds (ELBOs) can be detrimental to the process of learning an inference network by reducing the signal-to-noise ratio of the gradient estimator. Our results call into question common implicit assumptions that tighter ELBOs are better variational objectives for simultaneous model learning and inference amortization schemes. Based on our insights, we introduce three new algorithms: the partially importance weighted auto-encoder (PIWAE), the multiply importance weighted auto-encoder (MIWAE), and the combination importance weighted auto-encoder (CIWAE), each of which includes the standard importance weighted auto-encoder (IWAE) as a special case. We show that each can deliver improvements over IWAE, even when performance is measured by the IWAE target itself. Furthermore, our results suggest that PIWAE may be able to deliver simultaneous improvements in the training of both the inference and generative networks.