 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRight for the Right Latent Factors: Debiasing Generative Models via Disentanglement
Feb 01, 2022

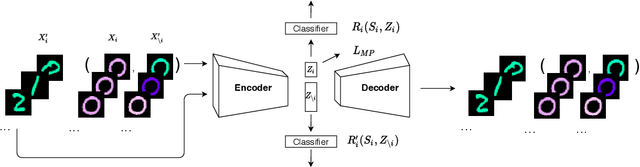
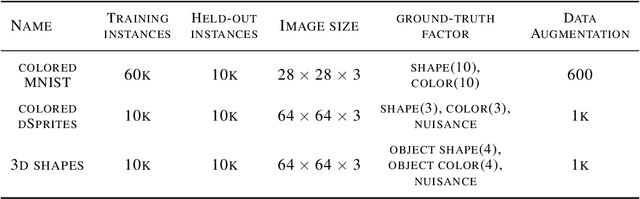
A key assumption of most statistical machine learning methods is that they have access to independent samples from the distribution of data they encounter at test time. As such, these methods often perform poorly in the face of biased data, which breaks this assumption. In particular, machine learning models have been shown to exhibit Clever-Hans-like behaviour, meaning that spurious correlations in the training set are inadvertently learnt. A number of works have been proposed to revise deep classifiers to learn the right correlations. However, generative models have been overlooked so far. We observe that generative models are also prone to Clever-Hans-like behaviour. To counteract this issue, we propose to debias generative models by disentangling their internal representations, which is achieved via human feedback. Our experiments show that this is effective at removing bias even when human feedback covers only a small fraction of the desired distribution. In addition, we achieve strong disentanglement results in a quantitative comparison with recent methods.
Decomposing 3D Scenes into Objects via Unsupervised Volume Segmentation
Apr 02, 2021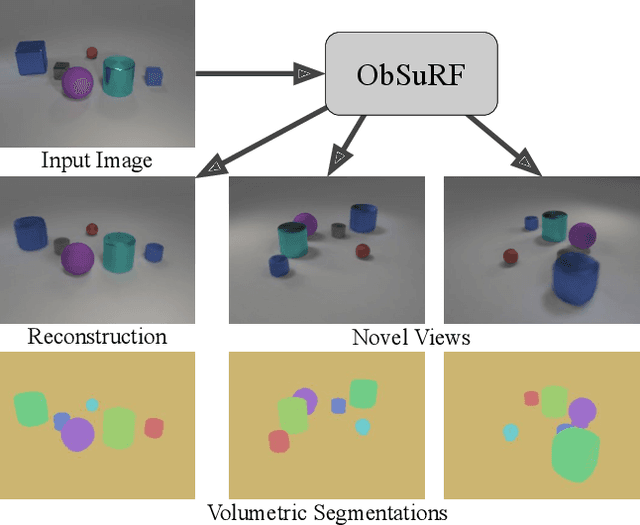
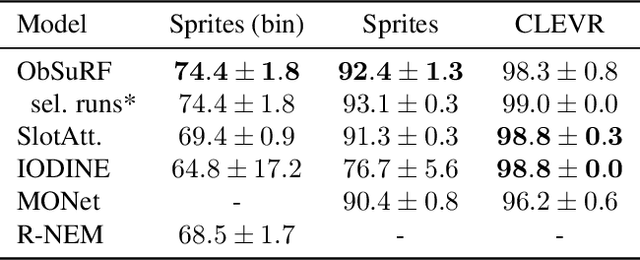
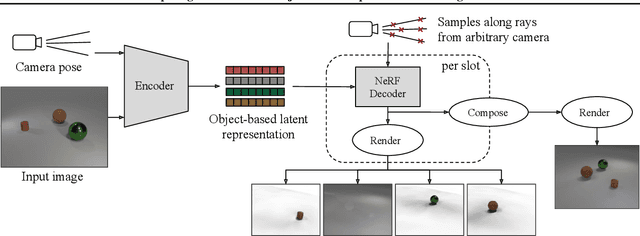

We present ObSuRF, a method which turns a single image of a scene into a 3D model represented as a set of Neural Radiance Fields (NeRFs), with each NeRF corresponding to a different object. A single forward pass of an encoder network outputs a set of latent vectors describing the objects in the scene. These vectors are used independently to condition a NeRF decoder, defining the geometry and appearance of each object. We make learning more computationally efficient by deriving a novel loss, which allows training NeRFs on RGB-D inputs without explicit ray marching. After confirming that the model performs equal or better than state of the art on three 2D image segmentation benchmarks, we apply it to two multi-object 3D datasets: A multiview version of CLEVR, and a novel dataset in which scenes are populated by ShapeNet models. We find that after training ObSuRF on RGB-D views of training scenes, it is capable of not only recovering the 3D geometry of a scene depicted in a single input image, but also to segment it into objects, despite receiving no supervision in that regard.
Einsum Networks: Fast and Scalable Learning of Tractable Probabilistic Circuits
Apr 13, 2020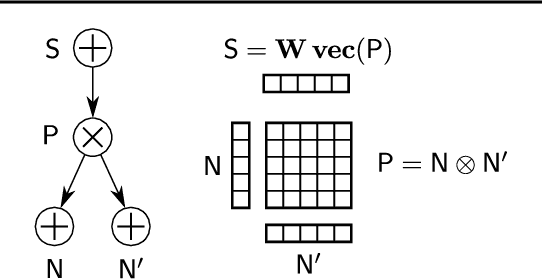

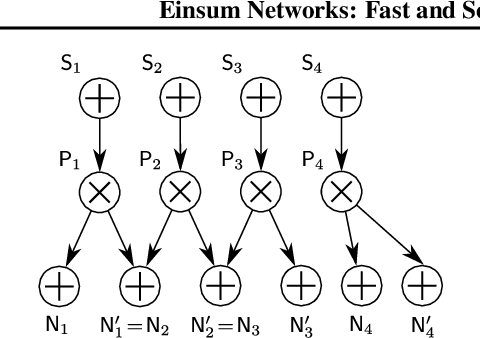
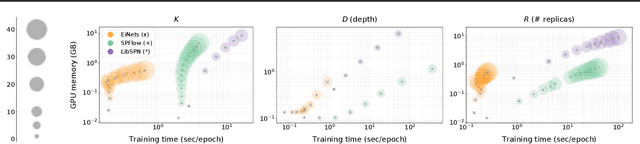
Probabilistic circuits (PCs) are a promising avenue for probabilistic modeling, as they permit a wide range of exact and efficient inference routines. Recent ``deep-learning-style'' implementations of PCs strive for a better scalability, but are still difficult to train on real-world data, due to their sparsely connected computational graphs. In this paper, we propose Einsum Networks (EiNets), a novel implementation design for PCs, improving prior art in several regards. At their core, EiNets combine a large number of arithmetic operations in a single monolithic einsum-operation, leading to speedups and memory savings of up to two orders of magnitude, in comparison to previous implementations. As an algorithmic contribution, we show that the implementation of Expectation-Maximization (EM) can be simplified for PCs, by leveraging automatic differentiation. Furthermore, we demonstrate that EiNets scale well to datasets which were previously out of reach, such as SVHN and CelebA, and that they can be used as faithful generative image models.
Structured Object-Aware Physics Prediction for Video Modeling and Planning
Oct 06, 2019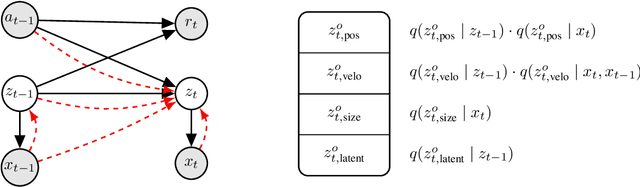



When humans observe a physical system, they can easily locate objects, understand their interactions, and anticipate future behavior, even in settings with complicated and previously unseen interactions. For computers, however, learning such models from videos in an unsupervised fashion is an unsolved research problem. In this paper, we present STOVE, a novel state-space model for videos, which explicitly reasons about objects and their positions, velocities, and interactions. It is constructed by combining an image model and a dynamics model in compositional manner and improves on previous work by reusing the dynamics model for inference, accelerating and regularizing training. STOVE predicts videos with convincing physical behavior over hundreds of timesteps, outperforms previous unsupervised models, and even approaches the performance of supervised baselines. We further demonstrate the strength of our model as a simulator for sample efficient model-based control in a task with heavily interacting objects.
Random Sum-Product Forests with Residual Links
Aug 08, 2019

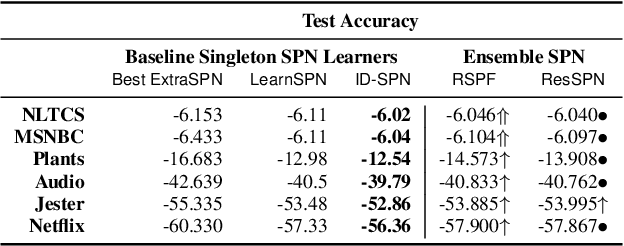
Tractable yet expressive density estimators are a key building block of probabilistic machine learning. While sum-product networks (SPNs) offer attractive inference capabilities, obtaining structures large enough to fit complex, high-dimensional data has proven challenging. In this paper, we present random sum-product forests (RSPFs), an ensemble approach for mixing multiple randomly generated SPNs. We also introduce residual links, which reference specialized substructures of other component SPNs in order to leverage the context-specific knowledge encoded within them. Our empirical evidence demonstrates that RSPFs provide better performance than their individual components. Adding residual links improves the models further, allowing the resulting ResSPNs to be competitive with commonly used structure learning methods.
Conditional Sum-Product Networks: Imposing Structure on Deep Probabilistic Architectures
May 21, 2019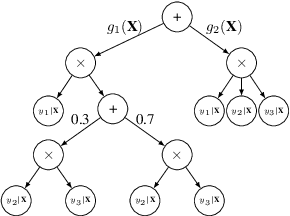
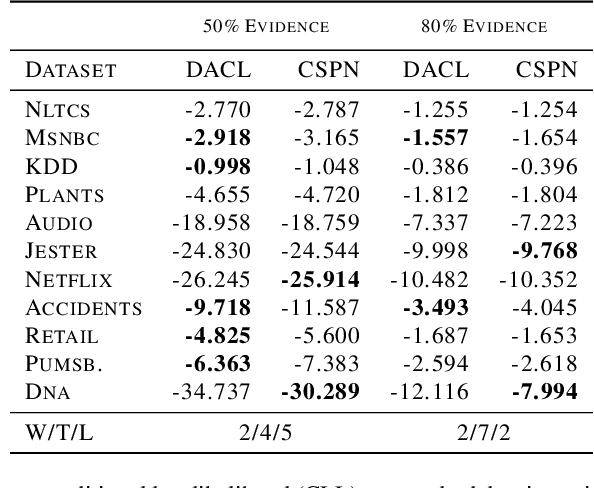
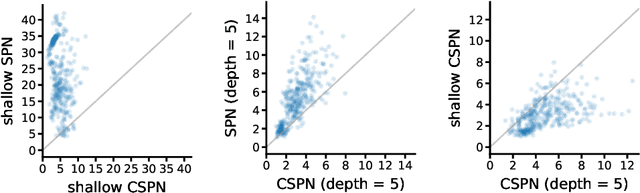

Bayesian networks are a central tool in machine learning and artificial intelligence, and make use of conditional independencies to impose structure on joint distributions. However, they are generally not as expressive as deep learning models and inference is hard and slow. In contrast, deep probabilistic models such as sum-product networks (SPNs) capture joint distributions in a tractable fashion, but use little interpretable structure. Here, we extend the notion of SPNs towards conditional distributions, which combine simple conditional models into high-dimensional ones. As shown in our experiments, the resulting conditional SPNs can be naturally used to impose structure on deep probabilistic models, allow for mixed data types, while maintaining fast and efficient inference.
SPFlow: An Easy and Extensible Library for Deep Probabilistic Learning using Sum-Product Networks
Jan 11, 2019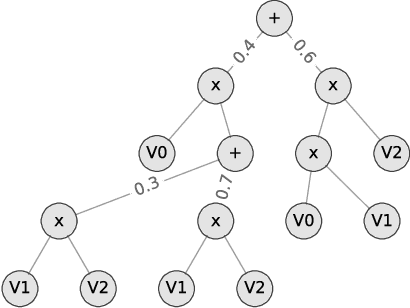
We introduce SPFlow, an open-source Python library providing a simple interface to inference, learning and manipulation routines for deep and tractable probabilistic models called Sum-Product Networks (SPNs). The library allows one to quickly create SPNs both from data and through a domain specific language (DSL). It efficiently implements several probabilistic inference routines like computing marginals, conditionals and (approximate) most probable explanations (MPEs) along with sampling as well as utilities for serializing, plotting and structure statistics on an SPN. Moreover, many of the algorithms proposed in the literature to learn the structure and parameters of SPNs are readily available in SPFlow. Furthermore, SPFlow is extremely extensible and customizable, allowing users to promptly distill new inference and learning routines by injecting custom code into a lightweight functional-oriented API framework. This is achieved in SPFlow by keeping an internal Python representation of the graph structure that also enables practical compilation of an SPN into a TensorFlow graph, C, CUDA or FPGA custom code, significantly speeding-up computations.
Probabilistic Deep Learning using Random Sum-Product Networks
Jun 22, 2018


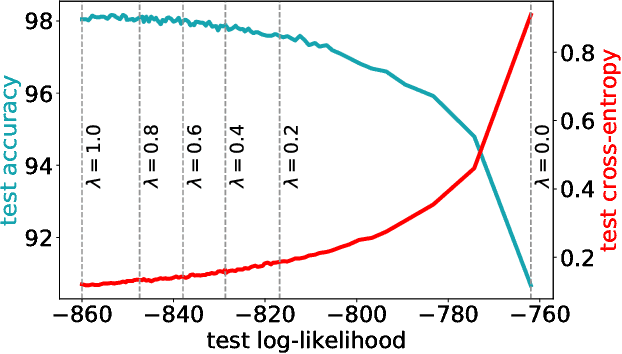
The need for consistent treatment of uncertainty has recently triggered increased interest in probabilistic deep learning methods. However, most current approaches have severe limitations when it comes to inference, since many of these models do not even permit to evaluate exact data likelihoods. Sum-product networks (SPNs), on the other hand, are an excellent architecture in that regard, as they allow to efficiently evaluate likelihoods, as well as arbitrary marginalization and conditioning tasks. Nevertheless, SPNs have not been fully explored as serious deep learning models, likely due to their special structural requirements, which complicate learning. In this paper, we make a drastic simplification and use random SPN structures which are trained in a "classical deep learning manner", i.e. employing automatic differentiation, SGD, and GPU support. The resulting models, called RAT-SPNs, yield prediction results comparable to deep neural networks, while still being interpretable as generative model and maintaining well-calibrated uncertainties. This property makes them highly robust under missing input features and enables them to naturally detect outliers and peculiar samples.