 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperparameter Optimization via Interacting with Probabilistic Circuits
May 23, 2025Despite the growing interest in designing truly interactive hyperparameter optimization (HPO) methods, to date, only a few allow to include human feedback. Existing interactive Bayesian optimization (BO) methods incorporate human beliefs by weighting the acquisition function with a user-defined prior distribution. However, in light of the non-trivial inner optimization of the acquisition function prevalent in BO, such weighting schemes do not always accurately reflect given user beliefs. We introduce a novel BO approach leveraging tractable probabilistic models named probabilistic circuits (PCs) as a surrogate model. PCs encode a tractable joint distribution over the hybrid hyperparameter space and evaluation scores. They enable exact conditional inference and sampling. Based on conditional sampling, we construct a novel selection policy that enables an acquisition function-free generation of candidate points (thereby eliminating the need for an additional inner-loop optimization) and ensures that user beliefs are reflected accurately in the selection policy. We provide a theoretical analysis and an extensive empirical evaluation, demonstrating that our method achieves state-of-the-art performance in standard HPO and outperforms interactive BO baselines in interactive HPO.
Probabilistic Circuits That Know What They Don't Know
Feb 17, 2023



Probabilistic circuits (PCs) are models that allow exact and tractable probabilistic inference. In contrast to neural networks, they are often assumed to be well-calibrated and robust to out-of-distribution (OOD) data. In this paper, we show that PCs are in fact not robust to OOD data, i.e., they don't know what they don't know. We then show how this challenge can be overcome by model uncertainty quantification. To this end, we propose tractable dropout inference (TDI), an inference procedure to estimate uncertainty by deriving an analytical solution to Monte Carlo dropout (MCD) through variance propagation. Unlike MCD in neural networks, which comes at the cost of multiple network evaluations, TDI provides tractable sampling-free uncertainty estimates in a single forward pass. TDI improves the robustness of PCs to distribution shift and OOD data, demonstrated through a series of experiments evaluating the classification confidence and uncertainty estimates on real-world data.
DAFNe: A One-Stage Anchor-Free Deep Model for Oriented Object Detection
Sep 22, 2021

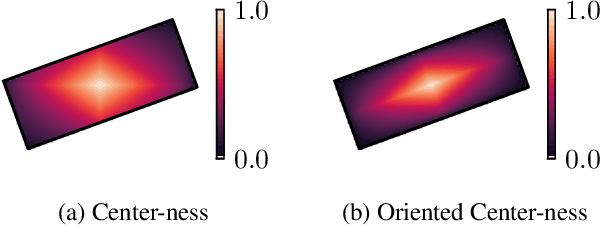

Object detection is a fundamental task in computer vision. While approaches for axis-aligned bounding box detection have made substantial progress in recent years, they perform poorly on oriented objects which are common in several real-world scenarios such as aerial view imagery and security camera footage. In these cases, a large part of a predicted bounding box will, undesirably, cover non-object related areas. Therefore, oriented object detection has emerged with the aim of generalizing object detection to arbitrary orientations. This enables a tighter fit to oriented objects, leading to a better separation of bounding boxes especially in case of dense object distributions. The vast majority of the work in this area has focused on complex two-stage anchor-based approaches. Anchors act as priors on the bounding box shape and require attentive hyper-parameter fine-tuning on a per-dataset basis, increased model size, and come with computational overhead. In this work, we present DAFNe: A Dense one-stage Anchor-Free deep Network for oriented object detection. As a one-stage model, DAFNe performs predictions on a dense grid over the input image, being architecturally simpler and faster, as well as easier to optimize than its two-stage counterparts. Furthermore, as an anchor-free model, DAFNe reduces the prediction complexity by refraining from employing bounding box anchors. Moreover, we introduce an orientation-aware generalization of the center-ness function for arbitrarily oriented bounding boxes to down-weight low-quality predictions and a center-to-corner bounding box prediction strategy that improves object localization performance. DAFNe improves the prediction accuracy over the previous best one-stage anchor-free model results on DOTA 1.0 by 4.65% mAP, setting the new state-of-the-art results by achieving 76.95% mAP.
RECOWNs: Probabilistic Circuits for Trustworthy Time Series Forecasting
Jun 08, 2021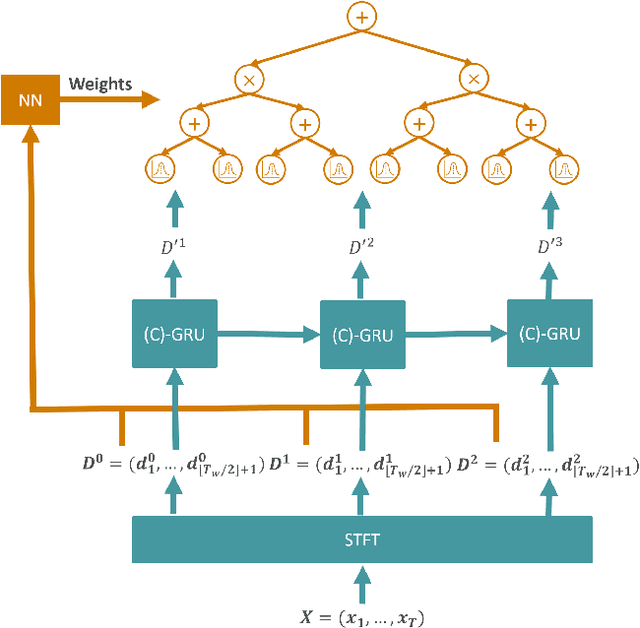


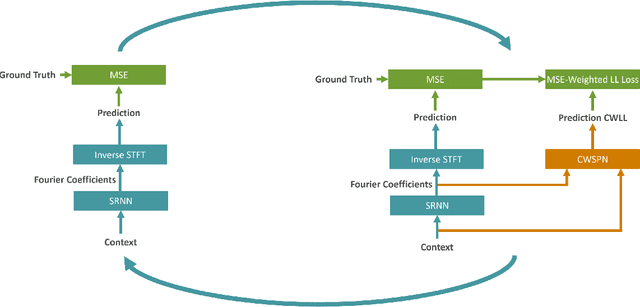
Time series forecasting is a relevant task that is performed in several real-world scenarios such as product sales analysis and prediction of energy demand. Given their accuracy performance, currently, Recurrent Neural Networks (RNNs) are the models of choice for this task. Despite their success in time series forecasting, less attention has been paid to make the RNNs trustworthy. For example, RNNs can not naturally provide an uncertainty measure to their predictions. This could be extremely useful in practice in several cases e.g. to detect when a prediction might be completely wrong due to an unusual pattern in the time series. Whittle Sum-Product Networks (WSPNs), prominent deep tractable probabilistic circuits (PCs) for time series, can assist an RNN with providing meaningful probabilities as uncertainty measure. With this aim, we propose RECOWN, a novel architecture that employs RNNs and a discriminant variant of WSPNs called Conditional WSPNs (CWSPNs). We also formulate a Log-Likelihood Ratio Score as better estimation of uncertainty that is tailored to time series and Whittle likelihoods. In our experiments, we show that RECOWNs are accurate and trustworthy time series predictors, able to "know when they do not know".
User Label Leakage from Gradients in Federated Learning
May 22, 2021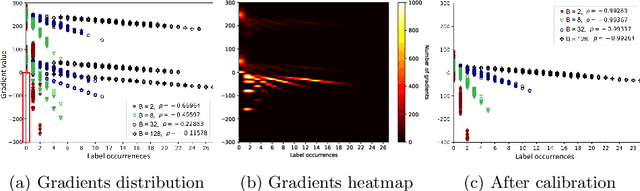

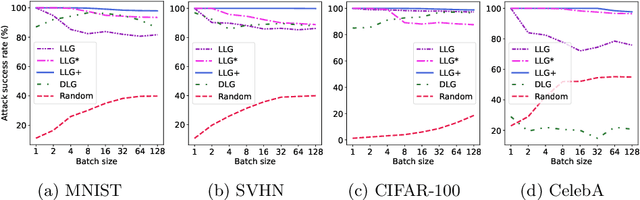

Federated learning enables multiple users to build a joint model by sharing their model updates (gradients), while their raw data remains local on their devices. In contrast to the common belief that this provides privacy benefits, we here add to the very recent results on privacy risks when sharing gradients. Specifically, we propose Label Leakage from Gradients (LLG), a novel attack to extract the labels of the users' training data from their shared gradients. The attack exploits the direction and magnitude of gradients to determine the presence or absence of any label. LLG is simple yet effective, capable of leaking potential sensitive information represented by labels, and scales well to arbitrary batch sizes and multiple classes. We empirically and mathematically demonstrate the validity of our attack under different settings. Moreover, empirical results show that LLG successfully extracts labels with high accuracy at the early stages of model training. We also discuss different defense mechanisms against such leakage. Our findings suggest that gradient compression is a practical technique to prevent our attack.
Random Sum-Product Forests with Residual Links
Aug 08, 2019
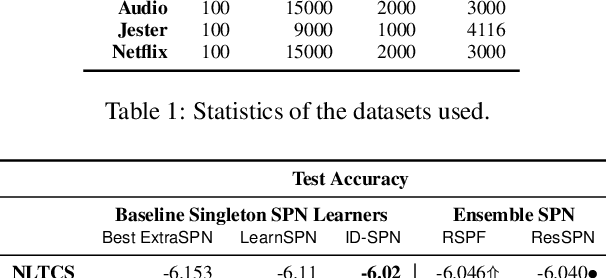

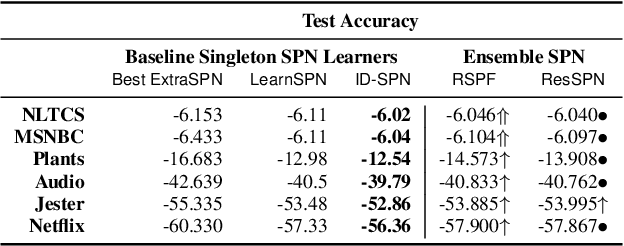
Tractable yet expressive density estimators are a key building block of probabilistic machine learning. While sum-product networks (SPNs) offer attractive inference capabilities, obtaining structures large enough to fit complex, high-dimensional data has proven challenging. In this paper, we present random sum-product forests (RSPFs), an ensemble approach for mixing multiple randomly generated SPNs. We also introduce residual links, which reference specialized substructures of other component SPNs in order to leverage the context-specific knowledge encoded within them. Our empirical evidence demonstrates that RSPFs provide better performance than their individual components. Adding residual links improves the models further, allowing the resulting ResSPNs to be competitive with commonly used structure learning methods.