 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperparameter Optimization via Interacting with Probabilistic Circuits
May 23, 2025Despite the growing interest in designing truly interactive hyperparameter optimization (HPO) methods, to date, only a few allow to include human feedback. Existing interactive Bayesian optimization (BO) methods incorporate human beliefs by weighting the acquisition function with a user-defined prior distribution. However, in light of the non-trivial inner optimization of the acquisition function prevalent in BO, such weighting schemes do not always accurately reflect given user beliefs. We introduce a novel BO approach leveraging tractable probabilistic models named probabilistic circuits (PCs) as a surrogate model. PCs encode a tractable joint distribution over the hybrid hyperparameter space and evaluation scores. They enable exact conditional inference and sampling. Based on conditional sampling, we construct a novel selection policy that enables an acquisition function-free generation of candidate points (thereby eliminating the need for an additional inner-loop optimization) and ensures that user beliefs are reflected accurately in the selection policy. We provide a theoretical analysis and an extensive empirical evaluation, demonstrating that our method achieves state-of-the-art performance in standard HPO and outperforms interactive BO baselines in interactive HPO.
Guidelines for the Quality Assessment of Energy-Aware NAS Benchmarks
May 21, 2025Neural Architecture Search (NAS) accelerates progress in deep learning through systematic refinement of model architectures. The downside is increasingly large energy consumption during the search process. Surrogate-based benchmarking mitigates the cost of full training by querying a pre-trained surrogate to obtain an estimate for the quality of the model. Specifically, energy-aware benchmarking aims to make it possible for NAS to favourably trade off model energy consumption against accuracy. Towards this end, we propose three design principles for such energy-aware benchmarks: (i) reliable power measurements, (ii) a wide range of GPU usage, and (iii) holistic cost reporting. We analyse EA-HAS-Bench based on these principles and find that the choice of GPU measurement API has a large impact on the quality of results. Using the Nvidia System Management Interface (SMI) on top of its underlying library influences the sampling rate during the initial data collection, returning faulty low-power estimations. This results in poor correlation with accurate measurements obtained from an external power meter. With this study, we bring to attention several key considerations when performing energy-aware surrogate-based benchmarking and derive first guidelines that can help design novel benchmarks. We show a narrow usage range of the four GPUs attached to our device, ranging from 146 W to 305 W in a single-GPU setting, and narrowing down even further when using all four GPUs. To improve holistic energy reporting, we propose calibration experiments over assumptions made in popular tools, such as Code Carbon, thus achieving reductions in the maximum inaccuracy from 10.3 % to 8.9 % without and to 6.6 % with prior estimation of the expected load on the device.
Scaling Probabilistic Circuits via Data Partitioning
Mar 11, 2025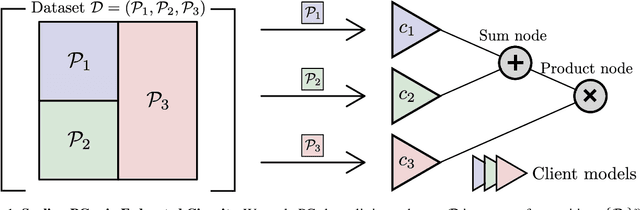

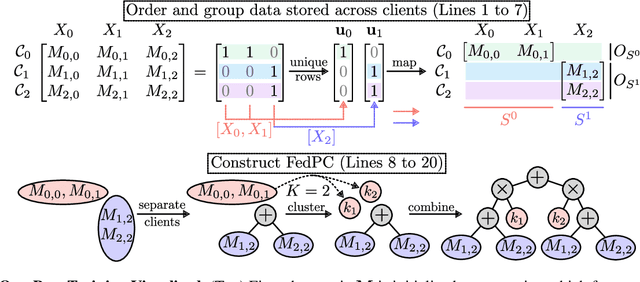

Probabilistic circuits (PCs) enable us to learn joint distributions over a set of random variables and to perform various probabilistic queries in a tractable fashion. Though the tractability property allows PCs to scale beyond non-tractable models such as Bayesian Networks, scaling training and inference of PCs to larger, real-world datasets remains challenging. To remedy the situation, we show how PCs can be learned across multiple machines by recursively partitioning a distributed dataset, thereby unveiling a deep connection between PCs and federated learning (FL). This leads to federated circuits (FCs) -- a novel and flexible federated learning (FL) framework that (1) allows one to scale PCs on distributed learning environments (2) train PCs faster and (3) unifies for the first time horizontal, vertical, and hybrid FL in one framework by re-framing FL as a density estimation problem over distributed datasets. We demonstrate FC's capability to scale PCs on various large-scale datasets. Also, we show FC's versatility in handling horizontal, vertical, and hybrid FL within a unified framework on multiple classification tasks.
Systems with Switching Causal Relations: A Meta-Causal Perspective
Oct 16, 2024
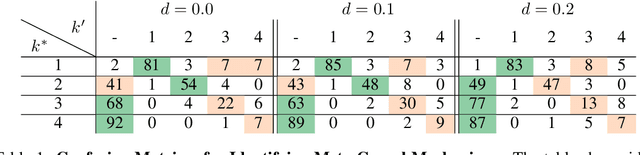
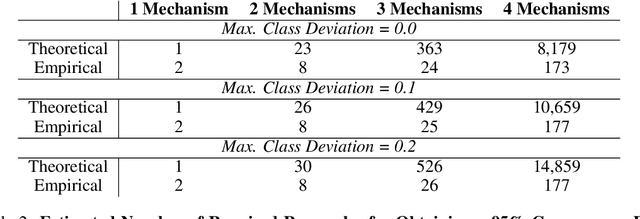

Most work on causality in machine learning assumes that causal relationships are driven by a constant underlying process. However, the flexibility of agents' actions or tipping points in the environmental process can change the qualitative dynamics of the system. As a result, new causal relationships may emerge, while existing ones change or disappear, resulting in an altered causal graph. To analyze these qualitative changes on the causal graph, we propose the concept of meta-causal states, which groups classical causal models into clusters based on equivalent qualitative behavior and consolidates specific mechanism parameterizations. We demonstrate how meta-causal states can be inferred from observed agent behavior, and discuss potential methods for disentangling these states from unlabeled data. Finally, we direct our analysis towards the application of a dynamical system, showing that meta-causal states can also emerge from inherent system dynamics, and thus constitute more than a context-dependent framework in which mechanisms emerge only as a result of external factors.
Continual Causal Abstractions
Jan 06, 2023
This short paper discusses continually updated causal abstractions as a potential direction of future research. The key idea is to revise the existing level of causal abstraction to a different level of detail that is both consistent with the history of observed data and more effective in solving a given task.
HANF: Hyperparameter And Neural Architecture Search in Federated Learning
Jun 24, 2022

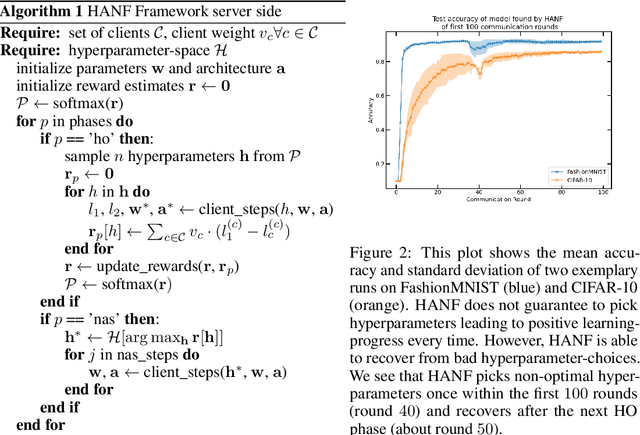

Automated machine learning (AutoML) is an important step to make machine learning models being widely applied to solve real world problems. Despite numerous research advancement, machine learning methods are not fully utilized by industries mainly due to their data privacy and security regulations, high cost involved in storing and computing increasing amount of data at central location and most importantly lack of expertise. Hence, we introduce a novel framework, HANF - $\textbf{H}$yperparameter $\textbf{A}$nd $\textbf{N}$eural architecture search in $\textbf{F}$ederated learning as a step towards building an AutoML framework for data distributed across several data owner servers without any need for bringing the data to a central location. HANF jointly optimizes a neural architecture and non-architectural hyperparameters of a learning algorithm using gradient-based neural architecture search and $n$-armed bandit approach respectively in data distributed setting. We show that HANF efficiently finds the optimized neural architecture and also tunes the hyperparameters on data owner servers. Additionally, HANF can be applied in both, federated and non-federated settings. Empirically, we show that HANF converges towards well-suited architectures and non-architectural hyperparameter-sets using image-classification tasks.
Tearing Apart NOTEARS: Controlling the Graph Prediction via Variance Manipulation
Jun 14, 2022



Simulations are ubiquitous in machine learning. Especially in graph learning, simulations of Directed Acyclic Graphs (DAG) are being deployed for evaluating new algorithms. In the literature, it was recently argued that continuous-optimization approaches to structure discovery such as NOTEARS might be exploiting the sortability of the variable's variances in the available data due to their use of least square losses. Specifically, since structure discovery is a key problem in science and beyond, we want to be invariant to the scale being used for measuring our data (e.g. meter versus centimeter should not affect the causal direction inferred by the algorithm). In this work, we further strengthen this initial, negative empirical suggestion by both proving key results in the multivariate case and corroborating with further empirical evidence. In particular, we show that we can control the resulting graph with our targeted variance attacks, even in the case where we can only partially manipulate the variances of the data.