 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReactive Knowledge Representation and Asynchronous Reasoning
Feb 05, 2026Exact inference in complex probabilistic models often incurs prohibitive computational costs. This challenge is particularly acute for autonomous agents in dynamic environments that require frequent, real-time belief updates. Existing methods are often inefficient for ongoing reasoning, as they re-evaluate the entire model upon any change, failing to exploit that real-world information streams have heterogeneous update rates. To address this, we approach the problem from a reactive, asynchronous, probabilistic reasoning perspective. We first introduce Resin (Reactive Signal Inference), a probabilistic programming language that merges probabilistic logic with reactive programming. Furthermore, to provide efficient and exact semantics for Resin, we propose Reactive Circuits (RCs). Formulated as a meta-structure over Algebraic Circuits and asynchronous data streams, RCs are time-dynamic Directed Acyclic Graphs that autonomously adapt themselves based on the volatility of input signals. In high-fidelity drone swarm simulations, our approach achieves several orders of magnitude of speedup over frequency-agnostic inference. We demonstrate that RCs' structural adaptations successfully capture environmental dynamics, significantly reducing latency and facilitating reactive real-time reasoning. By partitioning computations based on the estimated Frequency of Change in the asynchronous inputs, large inference tasks can be decomposed into individually memoized sub-problems. This ensures that only the specific components of a model affected by new information are re-evaluated, drastically reducing redundant computation in streaming contexts.
QuAnTS: Question Answering on Time Series
Nov 07, 2025Text offers intuitive access to information. This can, in particular, complement the density of numerical time series, thereby allowing improved interactions with time series models to enhance accessibility and decision-making. While the creation of question-answering datasets and models has recently seen remarkable growth, most research focuses on question answering (QA) on vision and text, with time series receiving minute attention. To bridge this gap, we propose a challenging novel time series QA (TSQA) dataset, QuAnTS, for Question Answering on Time Series data. Specifically, we pose a wide variety of questions and answers about human motion in the form of tracked skeleton trajectories. We verify that the large-scale QuAnTS dataset is well-formed and comprehensive through extensive experiments. Thoroughly evaluating existing and newly proposed baselines then lays the groundwork for a deeper exploration of TSQA using QuAnTS. Additionally, we provide human performances as a key reference for gauging the practical usability of such models. We hope to encourage future research on interacting with time series models through text, enabling better decision-making and more transparent systems.
Causal Abstractions, Categorically Unified
Oct 06, 2025We present a categorical framework for relating causal models that represent the same system at different levels of abstraction. We define a causal abstraction as natural transformations between appropriate Markov functors, which concisely consolidate desirable properties a causal abstraction should exhibit. Our approach unifies and generalizes previously considered causal abstractions, and we obtain categorical proofs and generalizations of existing results on causal abstractions. Using string diagrammatical tools, we can explicitly describe the graphs that serve as consistent abstractions of a low-level graph under interventions. We discuss how methods from mechanistic interpretability, such as circuit analysis and sparse autoencoders, fit within our categorical framework. We also show how applying do-calculus on a high-level graphical abstraction of an acyclic-directed mixed graph (ADMG), when unobserved confounders are present, gives valid results on the low-level graph, thus generalizing an earlier statement by Anand et al. (2023). We argue that our framework is more suitable for modeling causal abstractions compared to existing categorical frameworks. Finally, we discuss how notions such as $\tau$-consistency and constructive $\tau$-abstractions can be recovered with our framework.
Tagged for Direction: Pinning Down Causal Edge Directions with Precision
Jun 24, 2025Not every causal relation between variables is equal, and this can be leveraged for the task of causal discovery. Recent research shows that pairs of variables with particular type assignments induce a preference on the causal direction of other pairs of variables with the same type. Although useful, this assignment of a specific type to a variable can be tricky in practice. We propose a tag-based causal discovery approach where multiple tags are assigned to each variable in a causal graph. Existing causal discovery approaches are first applied to direct some edges, which are then used to determine edge relations between tags. Then, these edge relations are used to direct the undirected edges. Doing so improves upon purely type-based relations, where the assumption of type consistency lacks robustness and flexibility due to being restricted to single types for each variable. Our experimental evaluations show that this boosts causal discovery and that these high-level tag relations fit common knowledge.
Causal Explanations Over Time: Articulated Reasoning for Interactive Environments
Jun 04, 2025Structural Causal Explanations (SCEs) can be used to automatically generate explanations in natural language to questions about given data that are grounded in a (possibly learned) causal model. Unfortunately they work for small data only. In turn they are not attractive to offer reasons for events, e.g., tracking causal changes over multiple time steps, or a behavioral component that involves feedback loops through actions of an agent. To this end, we generalize SCEs to a (recursive) formulation of explanation trees to capture the temporal interactions between reasons. We show the benefits of this more general SCE algorithm on synthetic time-series data and a 2D grid game, and further compare it to the base SCE and other existing methods for causal explanations.
Scaling Probabilistic Circuits via Data Partitioning
Mar 11, 2025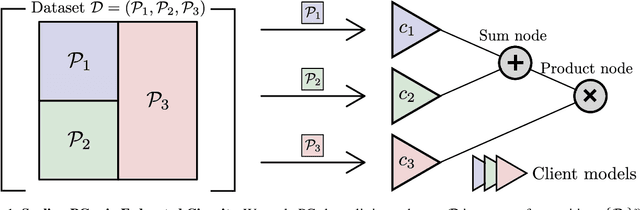

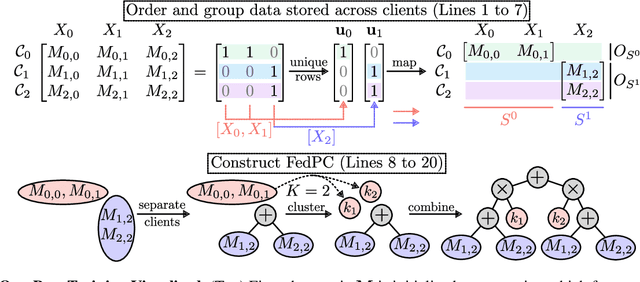

Probabilistic circuits (PCs) enable us to learn joint distributions over a set of random variables and to perform various probabilistic queries in a tractable fashion. Though the tractability property allows PCs to scale beyond non-tractable models such as Bayesian Networks, scaling training and inference of PCs to larger, real-world datasets remains challenging. To remedy the situation, we show how PCs can be learned across multiple machines by recursively partitioning a distributed dataset, thereby unveiling a deep connection between PCs and federated learning (FL). This leads to federated circuits (FCs) -- a novel and flexible federated learning (FL) framework that (1) allows one to scale PCs on distributed learning environments (2) train PCs faster and (3) unifies for the first time horizontal, vertical, and hybrid FL in one framework by re-framing FL as a density estimation problem over distributed datasets. We demonstrate FC's capability to scale PCs on various large-scale datasets. Also, we show FC's versatility in handling horizontal, vertical, and hybrid FL within a unified framework on multiple classification tasks.
Probabilistic Mission Design in Neuro-Symbolic Systems
Dec 25, 2024



Advanced Air Mobility (AAM) is a growing field that demands accurate modeling of legal concepts and restrictions in navigating intelligent vehicles. In addition, any implementation of AAM needs to face the challenges posed by inherently dynamic and uncertain human-inhabited spaces robustly. Nevertheless, the employment of Unmanned Aircraft Systems (UAS) beyond visual line of sight (BVLOS) is an endearing task that promises to enhance significantly today's logistics and emergency response capabilities. To tackle these challenges, we present a probabilistic and neuro-symbolic architecture to encode legal frameworks and expert knowledge over uncertain spatial relations and noisy perception in an interpretable and adaptable fashion. More specifically, we demonstrate Probabilistic Mission Design (ProMis), a system architecture that links geospatial and sensory data with declarative, Hybrid Probabilistic Logic Programs (HPLP) to reason over the agent's state space and its legality. As a result, ProMis generates Probabilistic Mission Landscapes (PML), which quantify the agent's belief that a set of mission conditions is satisfied across its navigation space. Extending prior work on ProMis' reasoning capabilities and computational characteristics, we show its integration with potent machine learning models such as Large Language Models (LLM) and Transformer-based vision models. Hence, our experiments underpin the application of ProMis with multi-modal input data and how our method applies to many important AAM scenarios.
Hybrid Many-Objective Optimization in Probabilistic Mission Design for Compliant and Effective UAV Routing
Dec 24, 2024Advanced Aerial Mobility encompasses many outstanding applications that promise to revolutionize modern logistics and pave the way for various public services and industry uses. However, throughout its history, the development of such systems has been impeded by the complexity of legal restrictions and physical constraints. While airspaces are often tightly shaped by various legal requirements, Unmanned Aerial Vehicles (UAV) must simultaneously consider, among others, energy demands, signal quality, and noise pollution. In this work, we address this challenge by presenting a novel architecture that integrates methods of Probabilistic Mission Design (ProMis) and Many-Objective Optimization for UAV routing. Hereby, our framework is able to comply with legal requirements under uncertainty while producing effective paths that minimize various physical costs a UAV needs to consider when traversing human-inhabited spaces. To this end, we combine hybrid probabilistic first-order logic for spatial reasoning with mixed deterministic-stochastic route optimization, incorporating physical objectives such as energy consumption and radio interference with a logical, probabilistic model of legal requirements. We demonstrate the versatility and advantages of our system in a large-scale empirical evaluation over real-world, crowd-sourced data from a map extract from the city of Paris, France, showing how a network of effective and compliant paths can be formed.
StaR Maps: Unveiling Uncertainty in Geospatial Relations
Dec 24, 2024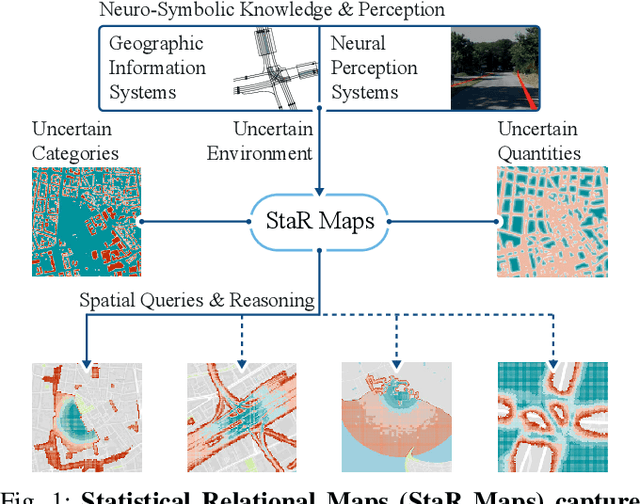


The growing complexity of intelligent transportation systems and their applications in public spaces has increased the demand for expressive and versatile knowledge representation. While various mapping efforts have achieved widespread coverage, including detailed annotation of features with semantic labels, it is essential to understand their inherent uncertainties, which are commonly underrepresented by the respective geographic information systems. Hence, it is critical to develop a representation that combines a statistical, probabilistic perspective with the relational nature of geospatial data. Further, such a representation should facilitate an honest view of the data's accuracy and provide an environment for high-level reasoning to obtain novel insights from task-dependent queries. Our work addresses this gap in two ways. First, we present Statistical Relational Maps (StaR Maps) as a representation of uncertain, semantic map data. Second, we demonstrate efficient computation of StaR Maps to scale the approach to wide urban spaces. Through experiments on real-world, crowd-sourced data, we underpin the application and utility of StaR Maps in terms of representing uncertain knowledge and reasoning for complex geospatial information.
The Constitutional Filter
Dec 24, 2024



Predictions in environments where a mix of legal policies, physical limitations, and operational preferences impacts an agent's motion are inherently difficult. Since Neuro-Symbolic systems allow for differentiable information flow between deep learning and symbolic building blocks, they present a promising avenue for expressing such high-level constraints. While prior work has demonstrated how to establish novel planning setups, e.g., in advanced aerial mobility tasks, their application in prediction tasks has been underdeveloped. We present the Constitutional Filter (CoFi), a novel filter architecture leveraging a Neuro-Symbolic representation of an agent's rules, i.e., its constitution, to (i) improve filter accuracy, (ii) leverage expert knowledge, (iii) incorporate deep learning architectures, and (iv) account for uncertainties in the environments through probabilistic spatial relations. CoFi follows a general, recursive Bayesian estimation setting, making it compatible with a vast landscape of estimation techniques such as Particle Filters. To underpin the advantages of CoFi, we validate its performance on real-world marine data from the Automatic Identification System and official Electronic Navigational Charts.