 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTORM: Segment, Track, and Object Re-Localization from a Single 3D Model
Nov 12, 2025Accurate 6D pose estimation and tracking are fundamental capabilities for physical AI systems such as robots. However, existing approaches typically rely on a manually annotated segmentation mask of the target in the first frame, which is labor-intensive and leads to reduced performance when faced with occlusions or rapid movement. To address these limi- tations, we propose STORM (Segment, Track, and Object Re-localization from a single 3D Model), an open-source robust real-time 6D pose estimation system that requires no manual annotation. STORM employs a novel three-stage pipeline combining vision-language understanding with self-supervised feature matching: contextual object descriptions guide localization, self-cross-attention mechanisms identify candidate regions, and a segmentation model produces precise masks for accurate pose estimation. Another key innovation is our automatic re-registration mechanism that detects tracking failures through feature similarity monitoring and recovers from severe occlusions or rapid motion. STORM achieves state-of-the-art accuracy on challenging industrial datasets featuring multi-object occlusions, high-speed motion, and varying illumination, while operating at real-time speeds without additional training. This annotation-free approach significantly reduces deployment overhead, providing a practical solution for modern applications, such as flexible manufacturing and intelligent quality control.
Deep Reinforcement Learning Agents are not even close to Human Intelligence
May 27, 2025Deep reinforcement learning (RL) agents achieve impressive results in a wide variety of tasks, but they lack zero-shot adaptation capabilities. While most robustness evaluations focus on tasks complexifications, for which human also struggle to maintain performances, no evaluation has been performed on tasks simplifications. To tackle this issue, we introduce HackAtari, a set of task variations of the Arcade Learning Environments. We use it to demonstrate that, contrary to humans, RL agents systematically exhibit huge performance drops on simpler versions of their training tasks, uncovering agents' consistent reliance on shortcuts. Our analysis across multiple algorithms and architectures highlights the persistent gap between RL agents and human behavioral intelligence, underscoring the need for new benchmarks and methodologies that enforce systematic generalization testing beyond static evaluation protocols. Training and testing in the same environment is not enough to obtain agents equipped with human-like intelligence.
Better Decisions through the Right Causal World Model
Apr 09, 2025Reinforcement learning (RL) agents have shown remarkable performances in various environments, where they can discover effective policies directly from sensory inputs. However, these agents often exploit spurious correlations in the training data, resulting in brittle behaviours that fail to generalize to new or slightly modified environments. To address this, we introduce the Causal Object-centric Model Extraction Tool (COMET), a novel algorithm designed to learn the exact interpretable causal world models (CWMs). COMET first extracts object-centric state descriptions from observations and identifies the environment's internal states related to the depicted objects' properties. Using symbolic regression, it models object-centric transitions and derives causal relationships governing object dynamics. COMET further incorporates large language models (LLMs) for semantic inference, annotating causal variables to enhance interpretability. By leveraging these capabilities, COMET constructs CWMs that align with the true causal structure of the environment, enabling agents to focus on task-relevant features. The extracted CWMs mitigate the danger of shortcuts, permitting the development of RL systems capable of better planning and decision-making across dynamic scenarios. Our results, validated in Atari environments such as Pong and Freeway, demonstrate the accuracy and robustness of COMET, highlighting its potential to bridge the gap between object-centric reasoning and causal inference in reinforcement learning.
Evaluating Interpretable Reinforcement Learning by Distilling Policies into Programs
Mar 11, 2025There exist applications of reinforcement learning like medicine where policies need to be ''interpretable'' by humans. User studies have shown that some policy classes might be more interpretable than others. However, it is costly to conduct human studies of policy interpretability. Furthermore, there is no clear definition of policy interpretabiliy, i.e., no clear metrics for interpretability and thus claims depend on the chosen definition. We tackle the problem of empirically evaluating policies interpretability without humans. Despite this lack of clear definition, researchers agree on the notions of ''simulatability'': policy interpretability should relate to how humans understand policy actions given states. To advance research in interpretable reinforcement learning, we contribute a new methodology to evaluate policy interpretability. This new methodology relies on proxies for simulatability that we use to conduct a large-scale empirical evaluation of policy interpretability. We use imitation learning to compute baseline policies by distilling expert neural networks into small programs. We then show that using our methodology to evaluate the baselines interpretability leads to similar conclusions as user studies. We show that increasing interpretability does not necessarily reduce performances and can sometimes increase them. We also show that there is no policy class that better trades off interpretability and performance across tasks making it necessary for researcher to have methodologies for comparing policies interpretability.
Interpretable end-to-end Neurosymbolic Reinforcement Learning agents
Oct 18, 2024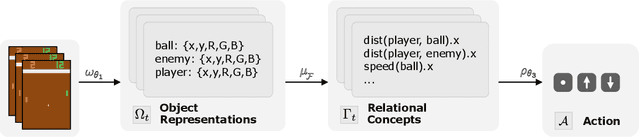
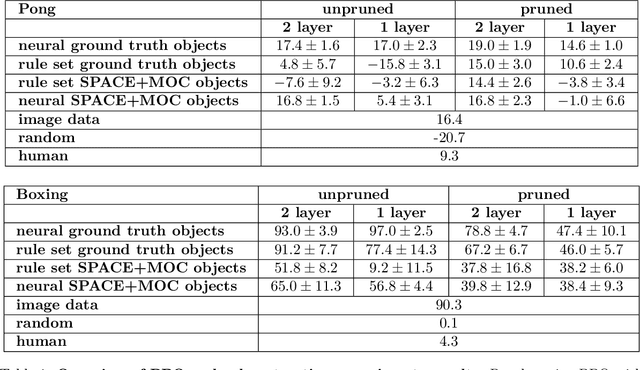

Deep reinforcement learning (RL) agents rely on shortcut learning, preventing them from generalizing to slightly different environments. To address this problem, symbolic method, that use object-centric states, have been developed. However, comparing these methods to deep agents is not fair, as these last operate from raw pixel-based states. In this work, we instantiate the symbolic SCoBots framework. SCoBots decompose RL tasks into intermediate, interpretable representations, culminating in action decisions based on a comprehensible set of object-centric relational concepts. This architecture aids in demystifying agent decisions. By explicitly learning to extract object-centric representations from raw states, object-centric RL, and policy distillation via rule extraction, this work places itself within the neurosymbolic AI paradigm, blending the strengths of neural networks with symbolic AI. We present the first implementation of an end-to-end trained SCoBot, separately evaluate of its components, on different Atari games. The results demonstrate the framework's potential to create interpretable and performing RL systems, and pave the way for future research directions in obtaining end-to-end interpretable RL agents.
BlendRL: A Framework for Merging Symbolic and Neural Policy Learning
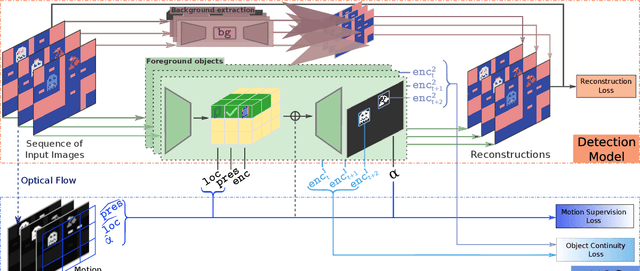
Oct 15, 2024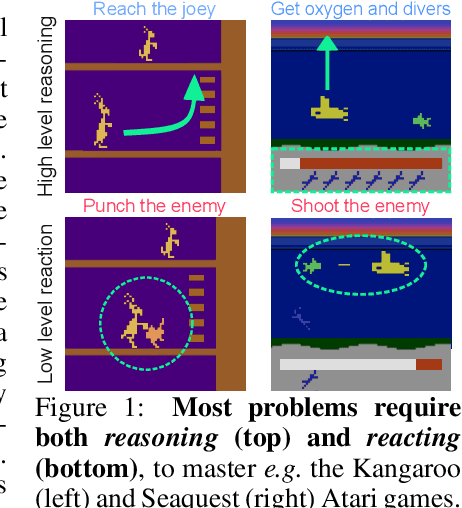
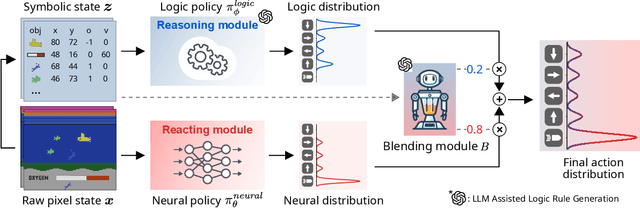

Humans can leverage both symbolic reasoning and intuitive reactions. In contrast, reinforcement learning policies are typically encoded in either opaque systems like neural networks or symbolic systems that rely on predefined symbols and rules. This disjointed approach severely limits the agents' capabilities, as they often lack either the flexible low-level reaction characteristic of neural agents or the interpretable reasoning of symbolic agents. To overcome this challenge, we introduce BlendRL, a neuro-symbolic RL framework that harmoniously integrates both paradigms within RL agents that use mixtures of both logic and neural policies. We empirically demonstrate that BlendRL agents outperform both neural and symbolic baselines in standard Atari environments, and showcase their robustness to environmental changes. Additionally, we analyze the interaction between neural and symbolic policies, illustrating how their hybrid use helps agents overcome each other's limitations.
OCALM: Object-Centric Assessment with Language Models
Jun 24, 2024



Properly defining a reward signal to efficiently train a reinforcement learning (RL) agent is a challenging task. Designing balanced objective functions from which a desired behavior can emerge requires expert knowledge, especially for complex environments. Learning rewards from human feedback or using large language models (LLMs) to directly provide rewards are promising alternatives, allowing non-experts to specify goals for the agent. However, black-box reward models make it difficult to debug the reward. In this work, we propose Object-Centric Assessment with Language Models (OCALM) to derive inherently interpretable reward functions for RL agents from natural language task descriptions. OCALM uses the extensive world-knowledge of LLMs while leveraging the object-centric nature common to many environments to derive reward functions focused on relational concepts, providing RL agents with the ability to derive policies from task descriptions.
EXPIL: Explanatory Predicate Invention for Learning in Games
Jun 10, 2024Reinforcement learning (RL) has proven to be a powerful tool for training agents that excel in various games. However, the black-box nature of neural network models often hinders our ability to understand the reasoning behind the agent's actions. Recent research has attempted to address this issue by using the guidance of pretrained neural agents to encode logic-based policies, allowing for interpretable decisions. A drawback of such approaches is the requirement of large amounts of predefined background knowledge in the form of predicates, limiting its applicability and scalability. In this work, we propose a novel approach, Explanatory Predicate Invention for Learning in Games (EXPIL), that identifies and extracts predicates from a pretrained neural agent, later used in the logic-based agents, reducing the dependency on predefined background knowledge. Our experimental evaluation on various games demonstrate the effectiveness of EXPIL in achieving explainable behavior in logic agents while requiring less background knowledge.
HackAtari: Atari Learning Environments for Robust and Continual Reinforcement Learning
Jun 06, 2024



Artificial agents' adaptability to novelty and alignment with intended behavior is crucial for their effective deployment. Reinforcement learning (RL) leverages novelty as a means of exploration, yet agents often struggle to handle novel situations, hindering generalization. To address these issues, we propose HackAtari, a framework introducing controlled novelty to the most common RL benchmark, the Atari Learning Environment. HackAtari allows us to create novel game scenarios (including simplification for curriculum learning), to swap the game elements' colors, as well as to introduce different reward signals for the agent. We demonstrate that current agents trained on the original environments include robustness failures, and evaluate HackAtari's efficacy in enhancing RL agents' robustness and aligning behavior through experiments using C51 and PPO. Overall, HackAtari can be used to improve the robustness of current and future RL algorithms, allowing Neuro-Symbolic RL, curriculum RL, causal RL, as well as LLM-driven RL. Our work underscores the significance of developing interpretable in RL agents.
Interpretable and Editable Programmatic Tree Policies for Reinforcement Learning
May 23, 2024



Deep reinforcement learning agents are prone to goal misalignments. The black-box nature of their policies hinders the detection and correction of such misalignments, and the trust necessary for real-world deployment. So far, solutions learning interpretable policies are inefficient or require many human priors. We propose INTERPRETER, a fast distillation method producing INTerpretable Editable tRee Programs for ReinforcEmenT lEaRning. We empirically demonstrate that INTERPRETER compact tree programs match oracles across a diverse set of sequential decision tasks and evaluate the impact of our design choices on interpretability and performances. We show that our policies can be interpreted and edited to correct misalignments on Atari games and to explain real farming strategies.