 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject Centric Concept Bottlenecks
May 30, 2025Developing high-performing, yet interpretable models remains a critical challenge in modern AI. Concept-based models (CBMs) attempt to address this by extracting human-understandable concepts from a global encoding (e.g., image encoding) and then applying a linear classifier on the resulting concept activations, enabling transparent decision-making. However, their reliance on holistic image encodings limits their expressiveness in object-centric real-world settings and thus hinders their ability to solve complex vision tasks beyond single-label classification. To tackle these challenges, we introduce Object-Centric Concept Bottlenecks (OCB), a framework that combines the strengths of CBMs and pre-trained object-centric foundation models, boosting performance and interpretability. We evaluate OCB on complex image datasets and conduct a comprehensive ablation study to analyze key components of the framework, such as strategies for aggregating object-concept encodings. The results show that OCB outperforms traditional CBMs and allows one to make interpretable decisions for complex visual tasks.
Navigating Shortcuts, Spurious Correlations, and Confounders: From Origins via Detection to Mitigation
Dec 06, 2024



Shortcuts, also described as Clever Hans behavior, spurious correlations, or confounders, present a significant challenge in machine learning and AI, critically affecting model generalization and robustness. Research in this area, however, remains fragmented across various terminologies, hindering the progress of the field as a whole. Consequently, we introduce a unifying taxonomy of shortcut learning by providing a formal definition of shortcuts and bridging the diverse terms used in the literature. In doing so, we further establish important connections between shortcuts and related fields, including bias, causality, and security, where parallels exist but are rarely discussed. Our taxonomy organizes existing approaches for shortcut detection and mitigation, providing a comprehensive overview of the current state of the field and revealing underexplored areas and open challenges. Moreover, we compile and classify datasets tailored to study shortcut learning. Altogether, this work provides a holistic perspective to deepen understanding and drive the development of more effective strategies for addressing shortcuts in machine learning.
Bongard in Wonderland: Visual Puzzles that Still Make AI Go Mad?
Oct 25, 2024



Recently, newly developed Vision-Language Models (VLMs), such as OpenAI's GPT-4o, have emerged, seemingly demonstrating advanced reasoning capabilities across text and image modalities. Yet, the depth of these advances in language-guided perception and abstract reasoning remains underexplored, and it is unclear whether these models can truly live up to their ambitious promises. To assess the progress and identify shortcomings, we enter the wonderland of Bongard problems, a set of classical visual reasoning puzzles that require human-like abilities of pattern recognition and abstract reasoning. While VLMs occasionally succeed in identifying discriminative concepts and solving some of the problems, they frequently falter, failing to understand and reason about visual concepts. Surprisingly, even elementary concepts that may seem trivial to humans, such as simple spirals, pose significant challenges. Moreover, even when asked to explicitly focus on and analyze these concepts, they continue to falter, suggesting not only a lack of understanding of these elementary visual concepts but also an inability to generalize to unseen concepts. These observations underscore the current limitations of VLMs, emphasize that a significant gap remains between human-like visual reasoning and machine cognition, and highlight the ongoing need for innovation in this area.
OCALM: Object-Centric Assessment with Language Models
Jun 24, 2024



Properly defining a reward signal to efficiently train a reinforcement learning (RL) agent is a challenging task. Designing balanced objective functions from which a desired behavior can emerge requires expert knowledge, especially for complex environments. Learning rewards from human feedback or using large language models (LLMs) to directly provide rewards are promising alternatives, allowing non-experts to specify goals for the agent. However, black-box reward models make it difficult to debug the reward. In this work, we propose Object-Centric Assessment with Language Models (OCALM) to derive inherently interpretable reward functions for RL agents from natural language task descriptions. OCALM uses the extensive world-knowledge of LLMs while leveraging the object-centric nature common to many environments to derive reward functions focused on relational concepts, providing RL agents with the ability to derive policies from task descriptions.
Neural Concept Binder
Jun 14, 2024



The challenge in object-based visual reasoning lies in generating descriptive yet distinct concept representations. Moreover, doing this in an unsupervised fashion requires human users to understand a model's learned concepts and potentially revise false concepts. In addressing this challenge, we introduce the Neural Concept Binder, a new framework for deriving discrete concept representations resulting in what we term "concept-slot encodings". These encodings leverage both "soft binding" via object-centric block-slot encodings and "hard binding" via retrieval-based inference. The Neural Concept Binder facilitates straightforward concept inspection and direct integration of external knowledge, such as human input or insights from other AI models like GPT-4. Additionally, we demonstrate that incorporating the hard binding mechanism does not compromise performance; instead, it enables seamless integration into both neural and symbolic modules for intricate reasoning tasks, as evidenced by evaluations on our newly introduced CLEVR-Sudoku dataset.
Right on Time: Revising Time Series Models by Constraining their Explanations
Feb 28, 2024



The reliability of deep time series models is often compromised by their tendency to rely on confounding factors, which may lead to misleading results. Our newly recorded, naturally confounded dataset named P2S from a real mechanical production line emphasizes this. To tackle the challenging problem of mitigating confounders in time series data, we introduce Right on Time (RioT). Our method enables interactions with model explanations across both the time and frequency domain. Feedback on explanations in both domains is then used to constrain the model, steering it away from the annotated confounding factors. The dual-domain interaction strategy is crucial for effectively addressing confounders in time series datasets. We empirically demonstrate that RioT can effectively guide models away from the wrong reasons in P2S as well as popular time series classification and forecasting datasets.
Pix2Code: Learning to Compose Neural Visual Concepts as Programs
Feb 13, 2024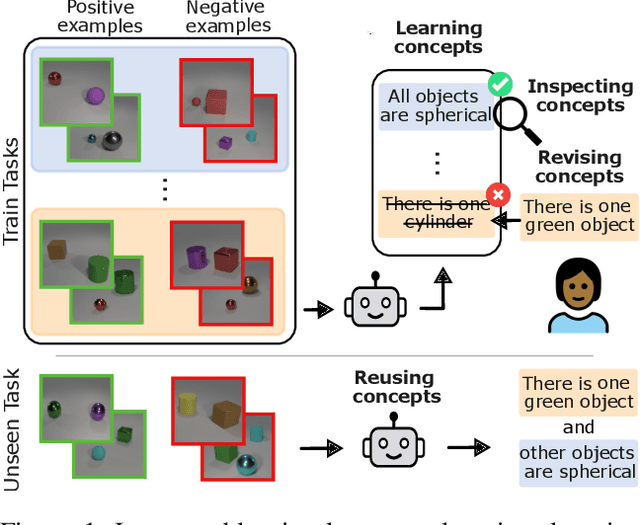

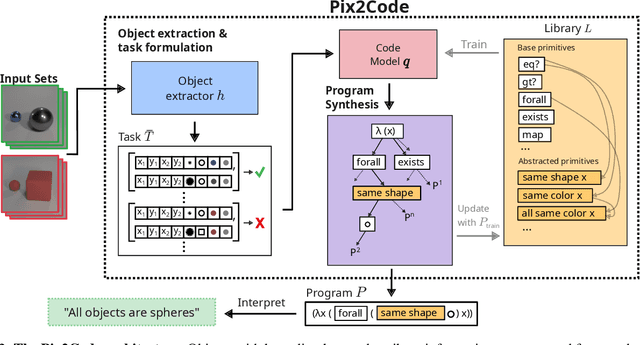
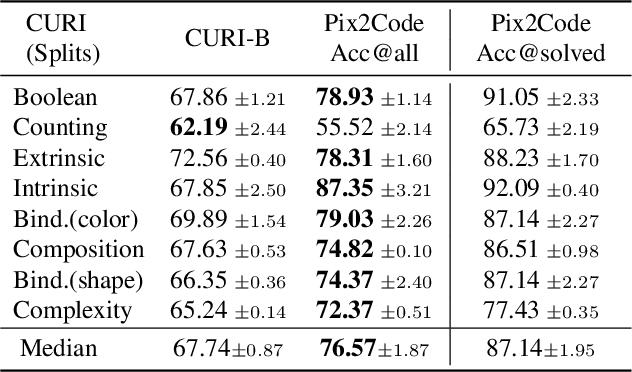
The challenge in learning abstract concepts from images in an unsupervised fashion lies in the required integration of visual perception and generalizable relational reasoning. Moreover, the unsupervised nature of this task makes it necessary for human users to be able to understand a model's learnt concepts and potentially revise false behaviours. To tackle both the generalizability and interpretability constraints of visual concept learning, we propose Pix2Code, a framework that extends program synthesis to visual relational reasoning by utilizing the abilities of both explicit, compositional symbolic and implicit neural representations. This is achieved by retrieving object representations from images and synthesizing relational concepts as lambda-calculus programs. We evaluate the diverse properties of Pix2Code on the challenging reasoning domains, Kandinsky Patterns and CURI, thereby testing its ability to identify compositional visual concepts that generalize to novel data and concept configurations. Particularly, in stark contrast to neural approaches, we show that Pix2Code's representations remain human interpretable and can be easily revised for improved performance.