 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning Agents are not even close to Human Intelligence
May 27, 2025Deep reinforcement learning (RL) agents achieve impressive results in a wide variety of tasks, but they lack zero-shot adaptation capabilities. While most robustness evaluations focus on tasks complexifications, for which human also struggle to maintain performances, no evaluation has been performed on tasks simplifications. To tackle this issue, we introduce HackAtari, a set of task variations of the Arcade Learning Environments. We use it to demonstrate that, contrary to humans, RL agents systematically exhibit huge performance drops on simpler versions of their training tasks, uncovering agents' consistent reliance on shortcuts. Our analysis across multiple algorithms and architectures highlights the persistent gap between RL agents and human behavioral intelligence, underscoring the need for new benchmarks and methodologies that enforce systematic generalization testing beyond static evaluation protocols. Training and testing in the same environment is not enough to obtain agents equipped with human-like intelligence.
Better Decisions through the Right Causal World Model
Apr 09, 2025Reinforcement learning (RL) agents have shown remarkable performances in various environments, where they can discover effective policies directly from sensory inputs. However, these agents often exploit spurious correlations in the training data, resulting in brittle behaviours that fail to generalize to new or slightly modified environments. To address this, we introduce the Causal Object-centric Model Extraction Tool (COMET), a novel algorithm designed to learn the exact interpretable causal world models (CWMs). COMET first extracts object-centric state descriptions from observations and identifies the environment's internal states related to the depicted objects' properties. Using symbolic regression, it models object-centric transitions and derives causal relationships governing object dynamics. COMET further incorporates large language models (LLMs) for semantic inference, annotating causal variables to enhance interpretability. By leveraging these capabilities, COMET constructs CWMs that align with the true causal structure of the environment, enabling agents to focus on task-relevant features. The extracted CWMs mitigate the danger of shortcuts, permitting the development of RL systems capable of better planning and decision-making across dynamic scenarios. Our results, validated in Atari environments such as Pong and Freeway, demonstrate the accuracy and robustness of COMET, highlighting its potential to bridge the gap between object-centric reasoning and causal inference in reinforcement learning.
Polynomial Regret Concentration of UCB for Non-Deterministic State Transitions
Feb 09, 2025Monte Carlo Tree Search (MCTS) has proven effective in solving decision-making problems in perfect information settings. However, its application to stochastic and imperfect information domains remains limited. This paper extends the theoretical framework of MCTS to stochastic domains by addressing non-deterministic state transitions, where actions lead to probabilistic outcomes. Specifically, building on the work of Shah et al. (2020), we derive polynomial regret concentration bounds for the Upper Confidence Bound algorithm in multi-armed bandit problems with stochastic transitions, offering improved theoretical guarantees. Our primary contribution is proving that these bounds also apply to non-deterministic environments, ensuring robust performance in stochastic settings. This broadens the applicability of MCTS to real-world decision-making problems with probabilistic outcomes, such as in autonomous systems and financial decision-making.
OCALM: Object-Centric Assessment with Language Models
Jun 24, 2024



Properly defining a reward signal to efficiently train a reinforcement learning (RL) agent is a challenging task. Designing balanced objective functions from which a desired behavior can emerge requires expert knowledge, especially for complex environments. Learning rewards from human feedback or using large language models (LLMs) to directly provide rewards are promising alternatives, allowing non-experts to specify goals for the agent. However, black-box reward models make it difficult to debug the reward. In this work, we propose Object-Centric Assessment with Language Models (OCALM) to derive inherently interpretable reward functions for RL agents from natural language task descriptions. OCALM uses the extensive world-knowledge of LLMs while leveraging the object-centric nature common to many environments to derive reward functions focused on relational concepts, providing RL agents with the ability to derive policies from task descriptions.
HackAtari: Atari Learning Environments for Robust and Continual Reinforcement Learning
Jun 06, 2024



Artificial agents' adaptability to novelty and alignment with intended behavior is crucial for their effective deployment. Reinforcement learning (RL) leverages novelty as a means of exploration, yet agents often struggle to handle novel situations, hindering generalization. To address these issues, we propose HackAtari, a framework introducing controlled novelty to the most common RL benchmark, the Atari Learning Environment. HackAtari allows us to create novel game scenarios (including simplification for curriculum learning), to swap the game elements' colors, as well as to introduce different reward signals for the agent. We demonstrate that current agents trained on the original environments include robustness failures, and evaluate HackAtari's efficacy in enhancing RL agents' robustness and aligning behavior through experiments using C51 and PPO. Overall, HackAtari can be used to improve the robustness of current and future RL algorithms, allowing Neuro-Symbolic RL, curriculum RL, causal RL, as well as LLM-driven RL. Our work underscores the significance of developing interpretable in RL agents.
Amplifying Exploration in Monte-Carlo Tree Search by Focusing on the Unknown
Feb 13, 2024



Monte-Carlo tree search (MCTS) is an effective anytime algorithm with a vast amount of applications. It strategically allocates computational resources to focus on promising segments of the search tree, making it a very attractive search algorithm in large search spaces. However, it often expends its limited resources on reevaluating previously explored regions when they remain the most promising path. Our proposed methodology, denoted as AmEx-MCTS, solves this problem by introducing a novel MCTS formulation. Central to AmEx-MCTS is the decoupling of value updates, visit count updates, and the selected path during the tree search, thereby enabling the exclusion of already explored subtrees or leaves. This segregation preserves the utility of visit counts for both exploration-exploitation balancing and quality metrics within MCTS. The resultant augmentation facilitates in a considerably broader search using identical computational resources, preserving the essential characteristics of MCTS. The expanded coverage not only yields more precise estimations but also proves instrumental in larger and more complex problems. Our empirical evaluation demonstrates the superior performance of AmEx-MCTS, surpassing classical MCTS and related approaches by a substantial margin.
Checkmating One, by Using Many: Combining Mixture of Experts with MCTS to Improve in Chess
Jan 30, 2024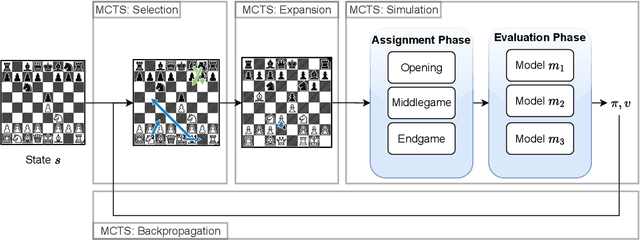

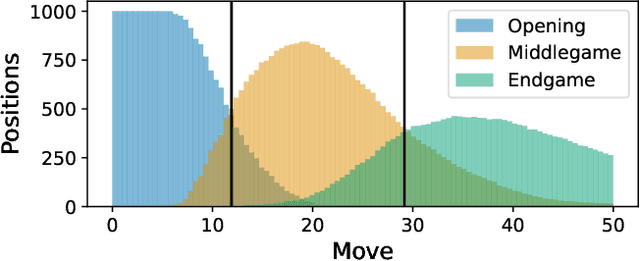

This paper presents a new approach that integrates deep learning with computational chess, using both the Mixture of Experts (MoE) method and Monte-Carlo Tree Search (MCTS). Our methodology employs a suite of specialized models, each designed to respond to specific changes in the game's input data. This results in a framework with sparsely activated models, which provides significant computational benefits. Our framework combines the MoE method with MCTS, in order to align it with the strategic phases of chess, thus departing from the conventional ``one-for-all'' model. Instead, we utilize distinct game phase definitions to effectively distribute computational tasks across multiple expert neural networks. Our empirical research shows a substantial improvement in playing strength, surpassing the traditional single-model framework. This validates the efficacy of our integrated approach and highlights the potential of incorporating expert knowledge and strategic principles into neural network design. The fusion of MoE and MCTS offers a promising avenue for advancing machine learning architectures.
From Images to Connections: Can DQN with GNNs learn the Strategic Game of Hex?
Nov 22, 2023



The gameplay of strategic board games such as chess, Go and Hex is often characterized by combinatorial, relational structures -- capturing distinct interactions and non-local patterns -- and not just images. Nonetheless, most common self-play reinforcement learning (RL) approaches simply approximate policy and value functions using convolutional neural networks (CNN). A key feature of CNNs is their relational inductive bias towards locality and translational invariance. In contrast, graph neural networks (GNN) can encode more complicated and distinct relational structures. Hence, we investigate the crucial question: Can GNNs, with their ability to encode complex connections, replace CNNs in self-play reinforcement learning? To this end, we do a comparison with Hex -- an abstract yet strategically rich board game -- serving as our experimental platform. Our findings reveal that GNNs excel at dealing with long range dependency situations in game states and are less prone to overfitting, but also showing a reduced proficiency in discerning local patterns. This suggests a potential paradigm shift, signaling the use of game-specific structures to reshape self-play reinforcement learning.
OCAtari: Object-Centric Atari 2600 Reinforcement Learning Environments
Jun 14, 2023



Cognitive science and psychology suggest that object-centric representations of complex scenes are a promising step towards enabling efficient abstract reasoning from low-level perceptual features. Yet, most deep reinforcement learning approaches rely on only pixel-based representations that do not capture the compositional properties of natural scenes. For this, we need environments and datasets that allow us to work and evaluate object-centric approaches. We present OCAtari, a set of environment that provides object-centric state representations of Atari games, the most-used evaluation framework for deep RL approaches. OCAtari also allows for RAM state manipulations of the games to change and create specific or even novel situations. The code base for this work is available at github.com/k4ntz/OC_Atari.
Representation Matters: The Game of Chess Poses a Challenge to Vision Transformers
Apr 28, 2023While transformers have gained the reputation as the "Swiss army knife of AI", no one has challenged them to master the game of chess, one of the classical AI benchmarks. Simply using vision transformers (ViTs) within AlphaZero does not master the game of chess, mainly because ViTs are too slow. Even making them more efficient using a combination of MobileNet and NextViT does not beat what actually matters: a simple change of the input representation and value loss, resulting in a greater boost of up to 180 Elo points over AlphaZero.