 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheckmating One, by Using Many: Combining Mixture of Experts with MCTS to Improve in Chess
Jan 30, 2024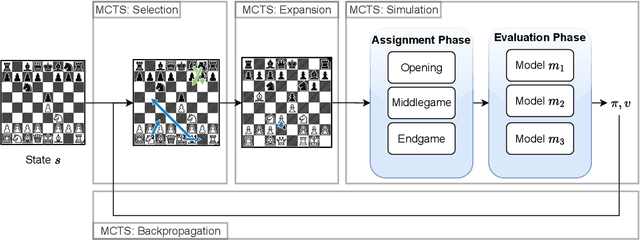

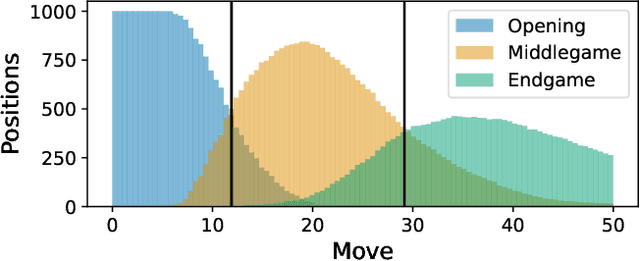

This paper presents a new approach that integrates deep learning with computational chess, using both the Mixture of Experts (MoE) method and Monte-Carlo Tree Search (MCTS). Our methodology employs a suite of specialized models, each designed to respond to specific changes in the game's input data. This results in a framework with sparsely activated models, which provides significant computational benefits. Our framework combines the MoE method with MCTS, in order to align it with the strategic phases of chess, thus departing from the conventional ``one-for-all'' model. Instead, we utilize distinct game phase definitions to effectively distribute computational tasks across multiple expert neural networks. Our empirical research shows a substantial improvement in playing strength, surpassing the traditional single-model framework. This validates the efficacy of our integrated approach and highlights the potential of incorporating expert knowledge and strategic principles into neural network design. The fusion of MoE and MCTS offers a promising avenue for advancing machine learning architectures.
Know your Enemy: Investigating Monte-Carlo Tree Search with Opponent Models in Pommerman
May 22, 2023


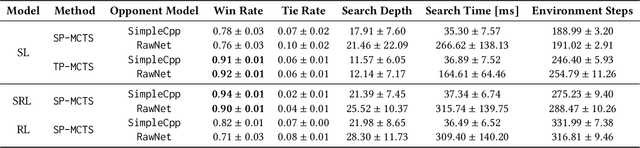
In combination with Reinforcement Learning, Monte-Carlo Tree Search has shown to outperform human grandmasters in games such as Chess, Shogi and Go with little to no prior domain knowledge. However, most classical use cases only feature up to two players. Scaling the search to an arbitrary number of players presents a computational challenge, especially if decisions have to be planned over a longer time horizon. In this work, we investigate techniques that transform general-sum multiplayer games into single-player and two-player games that consider other agents to act according to given opponent models. For our evaluation, we focus on the challenging Pommerman environment which involves partial observability, a long time horizon and sparse rewards. In combination with our search methods, we investigate the phenomena of opponent modeling using heuristics and self-play. Overall, we demonstrate the effectiveness of our multiplayer search variants both in a supervised learning and reinforcement learning setting.
Representation Matters: The Game of Chess Poses a Challenge to Vision Transformers
Apr 28, 2023While transformers have gained the reputation as the "Swiss army knife of AI", no one has challenged them to master the game of chess, one of the classical AI benchmarks. Simply using vision transformers (ViTs) within AlphaZero does not master the game of chess, mainly because ViTs are too slow. Even making them more efficient using a combination of MobileNet and NextViT does not beat what actually matters: a simple change of the input representation and value loss, resulting in a greater boost of up to 180 Elo points over AlphaZero.
Generative Adversarial Neural Cellular Automata
Jul 19, 2021
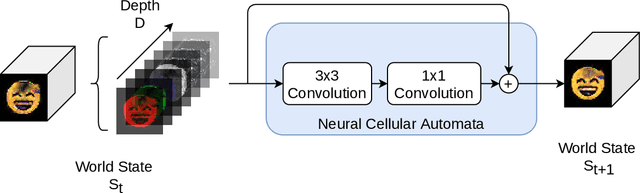


Motivated by the interaction between cells, the recently introduced concept of Neural Cellular Automata shows promising results in a variety of tasks. So far, this concept was mostly used to generate images for a single scenario. As each scenario requires a new model, this type of generation seems contradictory to the adaptability of cells in nature. To address this contradiction, we introduce a concept using different initial environments as input while using a single Neural Cellular Automata to produce several outputs. Additionally, we introduce GANCA, a novel algorithm that combines Neural Cellular Automata with Generative Adversarial Networks, allowing for more generalization through adversarial training. The experiments show that a single model is capable of learning several images when presented with different inputs, and that the adversarially trained model improves drastically on out-of-distribution data compared to a supervised trained model.
Monte-Carlo Graph Search for AlphaZero
Dec 20, 2020
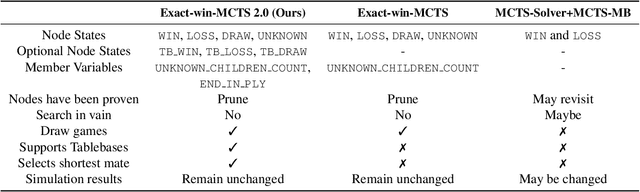
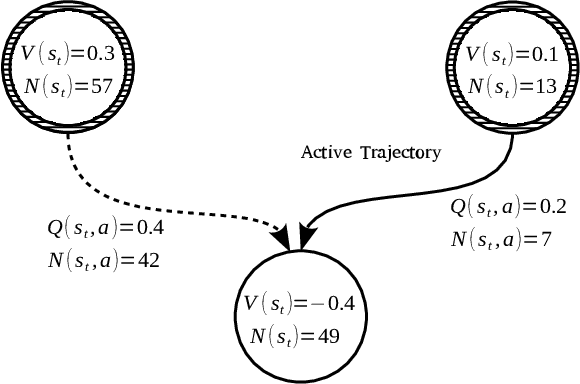
The AlphaZero algorithm has been successfully applied in a range of discrete domains, most notably board games. It utilizes a neural network, that learns a value and policy function to guide the exploration in a Monte-Carlo Tree Search. Although many search improvements have been proposed for Monte-Carlo Tree Search in the past, most of them refer to an older variant of the Upper Confidence bounds for Trees algorithm that does not use a policy for planning. We introduce a new, improved search algorithm for AlphaZero which generalizes the search tree to a directed acyclic graph. This enables information flow across different subtrees and greatly reduces memory consumption. Along with Monte-Carlo Graph Search, we propose a number of further extensions, such as the inclusion of Epsilon-greedy exploration, a revised terminal solver and the integration of domain knowledge as constraints. In our evaluations, we use the CrazyAra engine on chess and crazyhouse as examples to show that these changes bring significant improvements to AlphaZero.
Learning to play the Chess Variant Crazyhouse above World Champion Level with Deep Neural Networks and Human Data
Aug 22, 2019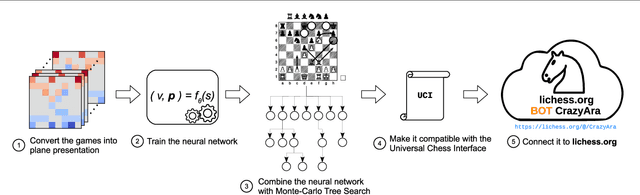
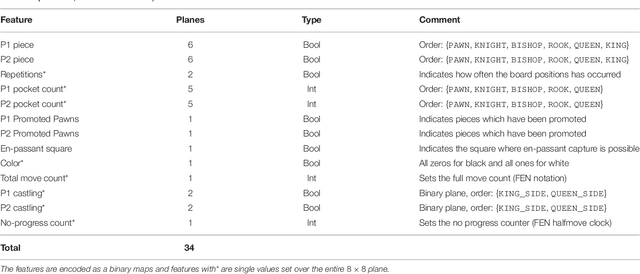

Deep neural networks have been successfully applied in learning the board games Go, chess and shogi without prior knowledge by making use of reinforcement learning. Although starting from zero knowledge has been shown to yield impressive results, it is associated with high computationally costs especially for complex games. With this paper, we present CrazyAra which is a neural network based engine solely trained in supervised manner for the chess variant crazyhouse. Crazyhouse is a game with a higher branching factor than chess and there is only limited data of lower quality available compared to AlphaGo. Therefore, we focus on improving efficiency in multiple aspects while relying on low computational resources. These improvements include modifications in the neural network design and training configuration, the introduction of a data normalization step and a more sample efficient Monte-Carlo tree search which has a lower chance to blunder. After training on 569,537 human games for 1.5 days we achieve a move prediction accuracy of 60.4%. During development, versions of CrazyAra played professional human players. Most notably, CrazyAra achieved a four to one win over 2017 crazyhouse world champion Justin Tan (aka LM Jann Lee) who is more than 400 Elo higher rated compared to the average player in our training set. Furthermore, we test the playing strength of CrazyAra on CPU against all participants of the second Crazyhouse Computer Championships 2017, winning against twelve of the thirteen participants. Finally, for CrazyAraFish we continue training our model on generated engine games. In ten long-time control matches playing Stockfish 10, CrazyAraFish wins three games and draws one out of ten matches.