 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTagged for Direction: Pinning Down Causal Edge Directions with Precision
Jun 24, 2025Not every causal relation between variables is equal, and this can be leveraged for the task of causal discovery. Recent research shows that pairs of variables with particular type assignments induce a preference on the causal direction of other pairs of variables with the same type. Although useful, this assignment of a specific type to a variable can be tricky in practice. We propose a tag-based causal discovery approach where multiple tags are assigned to each variable in a causal graph. Existing causal discovery approaches are first applied to direct some edges, which are then used to determine edge relations between tags. Then, these edge relations are used to direct the undirected edges. Doing so improves upon purely type-based relations, where the assumption of type consistency lacks robustness and flexibility due to being restricted to single types for each variable. Our experimental evaluations show that this boosts causal discovery and that these high-level tag relations fit common knowledge.
CausalMan: A physics-based simulator for large-scale causality
Feb 18, 2025A comprehensive understanding of causality is critical for navigating and operating within today's complex real-world systems. The absence of realistic causal models with known data generating processes complicates fair benchmarking. In this paper, we present the CausalMan simulator, modeled after a real-world production line. The simulator features a diverse range of linear and non-linear mechanisms and challenging-to-predict behaviors, such as discrete mode changes. We demonstrate the inadequacy of many state-of-the-art approaches and analyze the significant differences in their performance and tractability, both in terms of runtime and memory complexity. As a contribution, we will release the CausalMan large-scale simulator. We present two derived datasets, and perform an extensive evaluation of both.
Systems with Switching Causal Relations: A Meta-Causal Perspective
Oct 16, 2024
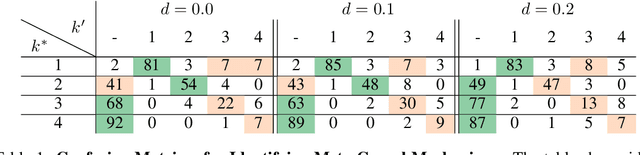
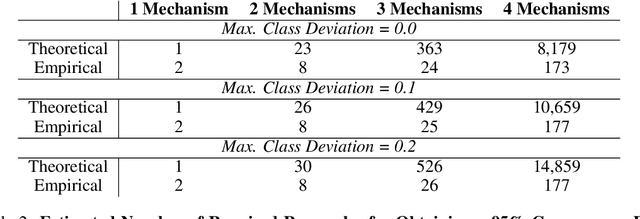

Most work on causality in machine learning assumes that causal relationships are driven by a constant underlying process. However, the flexibility of agents' actions or tipping points in the environmental process can change the qualitative dynamics of the system. As a result, new causal relationships may emerge, while existing ones change or disappear, resulting in an altered causal graph. To analyze these qualitative changes on the causal graph, we propose the concept of meta-causal states, which groups classical causal models into clusters based on equivalent qualitative behavior and consolidates specific mechanism parameterizations. We demonstrate how meta-causal states can be inferred from observed agent behavior, and discuss potential methods for disentangling these states from unlabeled data. Finally, we direct our analysis towards the application of a dynamical system, showing that meta-causal states can also emerge from inherent system dynamics, and thus constitute more than a context-dependent framework in which mechanisms emerge only as a result of external factors.
$χ$SPN: Characteristic Interventional Sum-Product Networks for Causal Inference in Hybrid Domains
Aug 14, 2024



Causal inference in hybrid domains, characterized by a mixture of discrete and continuous variables, presents a formidable challenge. We take a step towards this direction and propose Characteristic Interventional Sum-Product Network ($\chi$SPN) that is capable of estimating interventional distributions in presence of random variables drawn from mixed distributions. $\chi$SPN uses characteristic functions in the leaves of an interventional SPN (iSPN) thereby providing a unified view for discrete and continuous random variables through the Fourier-Stieltjes transform of the probability measures. A neural network is used to estimate the parameters of the learned iSPN using the intervened data. Our experiments on 3 synthetic heterogeneous datasets suggest that $\chi$SPN can effectively capture the interventional distributions for both discrete and continuous variables while being expressive and causally adequate. We also show that $\chi$SPN generalize to multiple interventions while being trained only on a single intervention data.
Do Not Marginalize Mechanisms, Rather Consolidate!
Oct 12, 2023



Structural causal models (SCMs) are a powerful tool for understanding the complex causal relationships that underlie many real-world systems. As these systems grow in size, the number of variables and complexity of interactions between them does, too. Thus, becoming convoluted and difficult to analyze. This is particularly true in the context of machine learning and artificial intelligence, where an ever increasing amount of data demands for new methods to simplify and compress large scale SCM. While methods for marginalizing and abstracting SCM already exist today, they may destroy the causality of the marginalized model. To alleviate this, we introduce the concept of consolidating causal mechanisms to transform large-scale SCM while preserving consistent interventional behaviour. We show consolidation is a powerful method for simplifying SCM, discuss reduction of computational complexity and give a perspective on generalizing abilities of consolidated SCM.
Causal Parrots: Large Language Models May Talk Causality But Are Not Causal
Aug 24, 2023



Some argue scale is all what is needed to achieve AI, covering even causal models. We make it clear that large language models (LLMs) cannot be causal and give reason onto why sometimes we might feel otherwise. To this end, we define and exemplify a new subgroup of Structural Causal Model (SCM) that we call meta SCM which encode causal facts about other SCM within their variables. We conjecture that in the cases where LLM succeed in doing causal inference, underlying was a respective meta SCM that exposed correlations between causal facts in natural language on whose data the LLM was ultimately trained. If our hypothesis holds true, then this would imply that LLMs are like parrots in that they simply recite the causal knowledge embedded in the data. Our empirical analysis provides favoring evidence that current LLMs are even weak `causal parrots.'
* Published in Transactions in Machine Learning Research (TMLR) (08/2023). Main paper: 17 pages, References: 3 pages, Appendix: 7 pages. Figures: 5 main, 3 appendix. Tables: 3 main
Continual Causal Abstractions
Jan 06, 2023
This short paper discusses continually updated causal abstractions as a potential direction of future research. The key idea is to revise the existing level of causal abstraction to a different level of detail that is both consistent with the history of observed data and more effective in solving a given task.
Pearl Causal Hierarchy on Image Data: Intricacies & Challenges
Dec 23, 2022Many researchers have voiced their support towards Pearl's counterfactual theory of causation as a stepping stone for AI/ML research's ultimate goal of intelligent systems. As in any other growing subfield, patience seems to be a virtue since significant progress on integrating notions from both fields takes time, yet, major challenges such as the lack of ground truth benchmarks or a unified perspective on classical problems such as computer vision seem to hinder the momentum of the research movement. This present work exemplifies how the Pearl Causal Hierarchy (PCH) can be understood on image data by providing insights on several intricacies but also challenges that naturally arise when applying key concepts from Pearlian causality to the study of image data.
Can Foundation Models Talk Causality?
Jun 14, 2022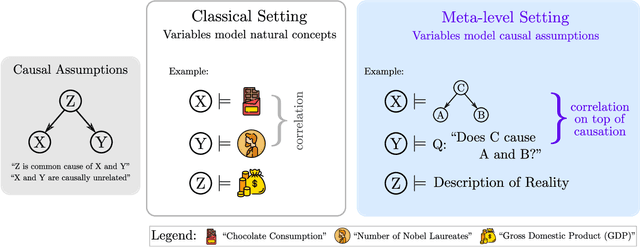
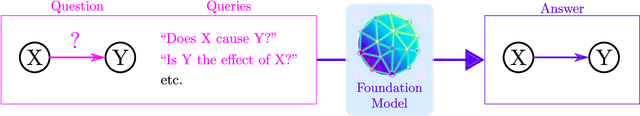
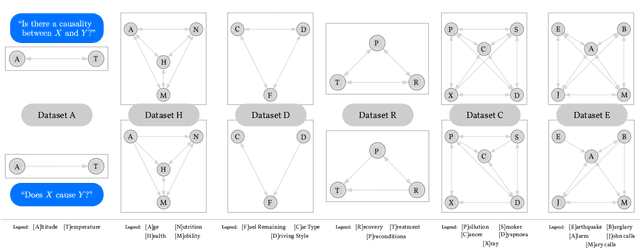
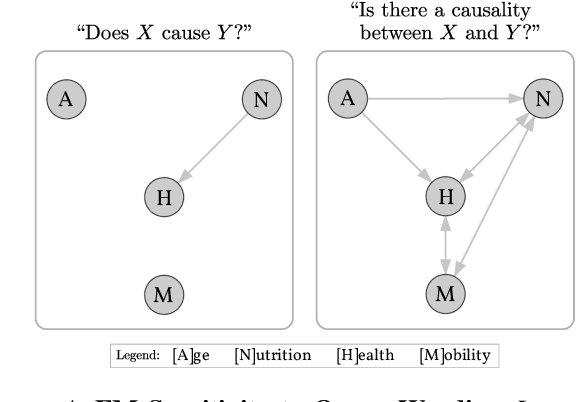
Foundation models are subject to an ongoing heated debate, leaving open the question of progress towards AGI and dividing the community into two camps: the ones who see the arguably impressive results as evidence to the scaling hypothesis, and the others who are worried about the lack of interpretability and reasoning capabilities. By investigating to which extent causal representations might be captured by these large scale language models, we make a humble efforts towards resolving the ongoing philosophical conflicts.
The Causal Loss: Driving Correlation to Imply Causation
Oct 22, 2021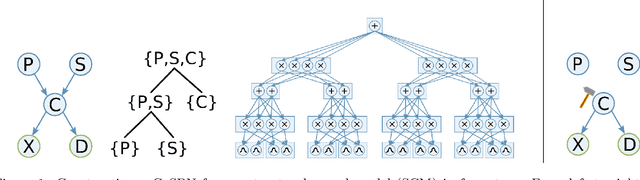
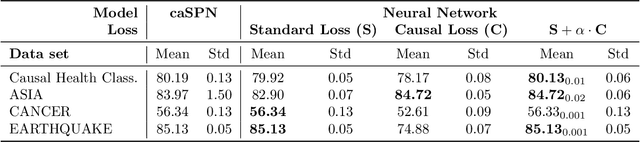
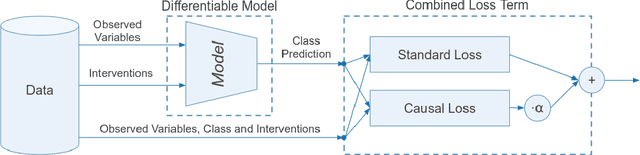
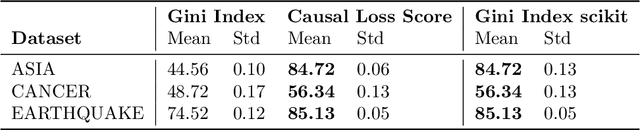
Most algorithms in classical and contemporary machine learning focus on correlation-based dependence between features to drive performance. Although success has been observed in many relevant problems, these algorithms fail when the underlying causality is inconsistent with the assumed relations. We propose a novel model-agnostic loss function called Causal Loss that improves the interventional quality of the prediction using an intervened neural-causal regularizer. In support of our theoretical results, our experimental illustration shows how causal loss bestows a non-causal associative model (like a standard neural net or decision tree) with interventional capabilities.