 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperparameter Optimization via Interacting with Probabilistic Circuits
May 23, 2025Despite the growing interest in designing truly interactive hyperparameter optimization (HPO) methods, to date, only a few allow to include human feedback. Existing interactive Bayesian optimization (BO) methods incorporate human beliefs by weighting the acquisition function with a user-defined prior distribution. However, in light of the non-trivial inner optimization of the acquisition function prevalent in BO, such weighting schemes do not always accurately reflect given user beliefs. We introduce a novel BO approach leveraging tractable probabilistic models named probabilistic circuits (PCs) as a surrogate model. PCs encode a tractable joint distribution over the hybrid hyperparameter space and evaluation scores. They enable exact conditional inference and sampling. Based on conditional sampling, we construct a novel selection policy that enables an acquisition function-free generation of candidate points (thereby eliminating the need for an additional inner-loop optimization) and ensures that user beliefs are reflected accurately in the selection policy. We provide a theoretical analysis and an extensive empirical evaluation, demonstrating that our method achieves state-of-the-art performance in standard HPO and outperforms interactive BO baselines in interactive HPO.
$χ$SPN: Characteristic Interventional Sum-Product Networks for Causal Inference in Hybrid Domains
Aug 14, 2024



Causal inference in hybrid domains, characterized by a mixture of discrete and continuous variables, presents a formidable challenge. We take a step towards this direction and propose Characteristic Interventional Sum-Product Network ($\chi$SPN) that is capable of estimating interventional distributions in presence of random variables drawn from mixed distributions. $\chi$SPN uses characteristic functions in the leaves of an interventional SPN (iSPN) thereby providing a unified view for discrete and continuous random variables through the Fourier-Stieltjes transform of the probability measures. A neural network is used to estimate the parameters of the learned iSPN using the intervened data. Our experiments on 3 synthetic heterogeneous datasets suggest that $\chi$SPN can effectively capture the interventional distributions for both discrete and continuous variables while being expressive and causally adequate. We also show that $\chi$SPN generalize to multiple interventions while being trained only on a single intervention data.
Characteristic Circuits
Dec 12, 2023



In many real-world scenarios, it is crucial to be able to reliably and efficiently reason under uncertainty while capturing complex relationships in data. Probabilistic circuits (PCs), a prominent family of tractable probabilistic models, offer a remedy to this challenge by composing simple, tractable distributions into a high-dimensional probability distribution. However, learning PCs on heterogeneous data is challenging and densities of some parametric distributions are not available in closed form, limiting their potential use. We introduce characteristic circuits (CCs), a family of tractable probabilistic models providing a unified formalization of distributions over heterogeneous data in the spectral domain. The one-to-one relationship between characteristic functions and probability measures enables us to learn high-dimensional distributions on heterogeneous data domains and facilitates efficient probabilistic inference even when no closed-form density function is available. We show that the structure and parameters of CCs can be learned efficiently from the data and find that CCs outperform state-of-the-art density estimators for heterogeneous data domains on common benchmark data sets.
HalluAudio: Hallucinating Frequency as Concepts for Few-Shot Audio Classification
Feb 27, 2023



Few-shot audio classification is an emerging topic that attracts more and more attention from the research community. Most existing work ignores the specificity of the form of the audio spectrogram and focuses largely on the embedding space borrowed from image tasks, while in this work, we aim to take advantage of this special audio format and propose a new method by hallucinating high-frequency and low-frequency parts as structured concepts. Extensive experiments on ESC-50 and our curated balanced Kaggle18 dataset show the proposed method outperforms the baseline by a notable margin. The way that our method hallucinates high-frequency and low-frequency parts also enables its interpretability and opens up new potentials for the few-shot audio classification.
Probabilistic Circuits That Know What They Don't Know
Feb 17, 2023



Probabilistic circuits (PCs) are models that allow exact and tractable probabilistic inference. In contrast to neural networks, they are often assumed to be well-calibrated and robust to out-of-distribution (OOD) data. In this paper, we show that PCs are in fact not robust to OOD data, i.e., they don't know what they don't know. We then show how this challenge can be overcome by model uncertainty quantification. To this end, we propose tractable dropout inference (TDI), an inference procedure to estimate uncertainty by deriving an analytical solution to Monte Carlo dropout (MCD) through variance propagation. Unlike MCD in neural networks, which comes at the cost of multiple network evaluations, TDI provides tractable sampling-free uncertainty estimates in a single forward pass. TDI improves the robustness of PCs to distribution shift and OOD data, demonstrated through a series of experiments evaluating the classification confidence and uncertainty estimates on real-world data.
Sum-Product-Attention Networks: Leveraging Self-Attention in Probabilistic Circuits
Sep 14, 2021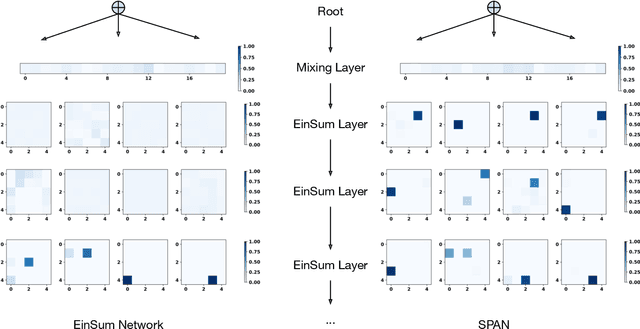
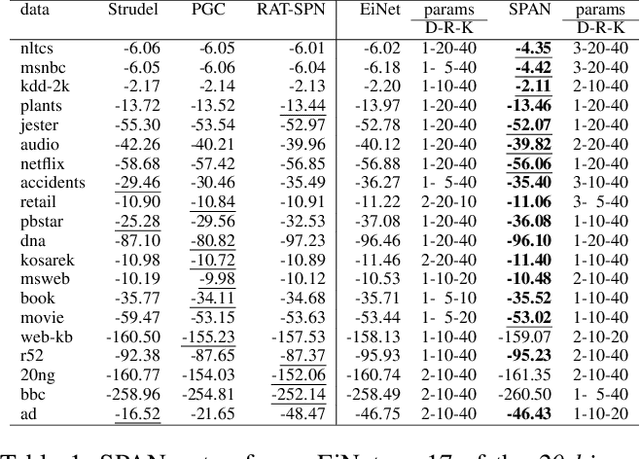
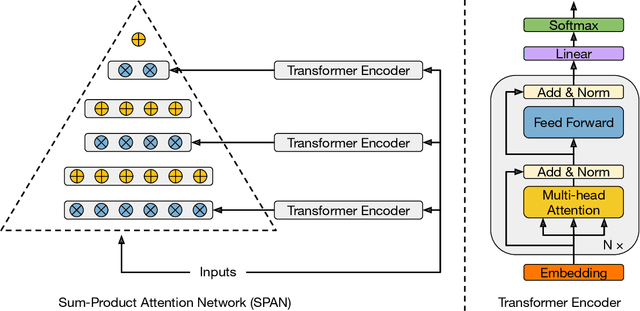
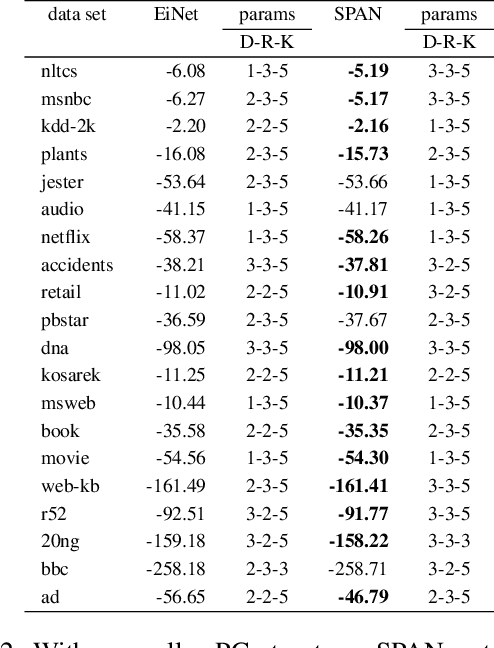
Probabilistic circuits (PCs) have become the de-facto standard for learning and inference in probabilistic modeling. We introduce Sum-Product-Attention Networks (SPAN), a new generative model that integrates probabilistic circuits with Transformers. SPAN uses self-attention to select the most relevant parts of a probabilistic circuit, here sum-product networks, to improve the modeling capability of the underlying sum-product network. We show that while modeling, SPAN focuses on a specific set of independent assumptions in every product layer of the sum-product network. Our empirical evaluations show that SPAN outperforms state-of-the-art probabilistic generative models on various benchmark data sets as well is an efficient generative image model.
Leveraging Probabilistic Circuits for Nonparametric Multi-Output Regression
Jun 16, 2021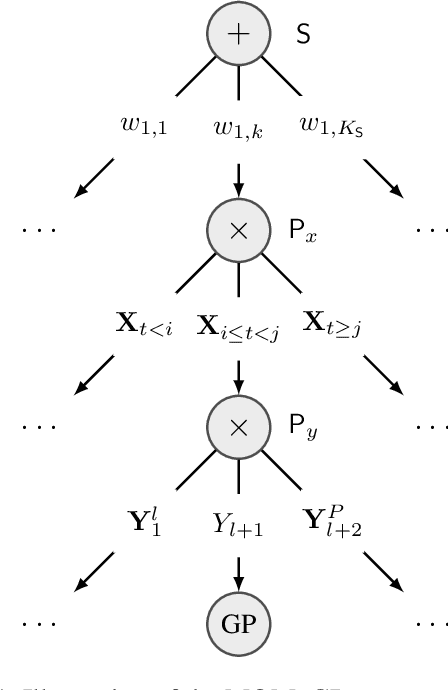
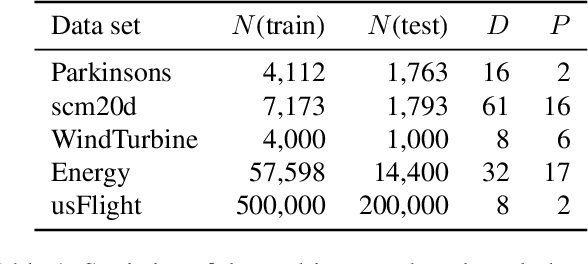
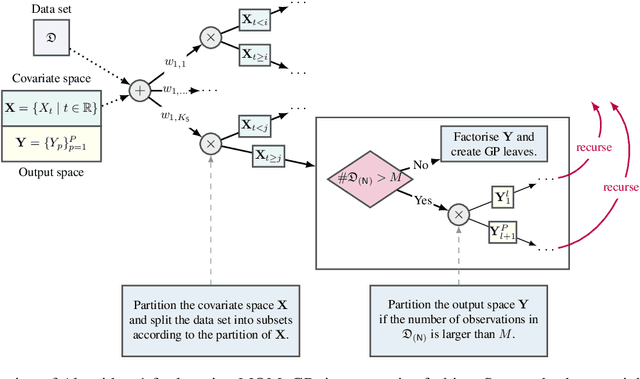
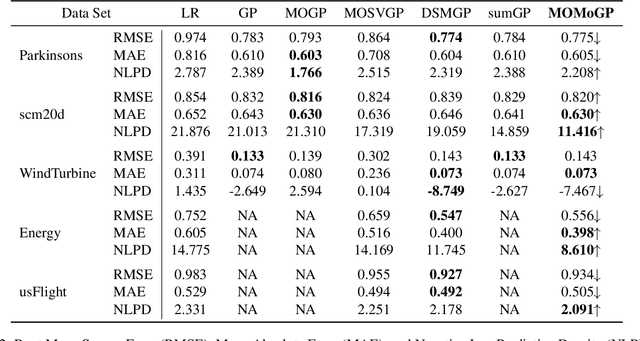
Inspired by recent advances in the field of expert-based approximations of Gaussian processes (GPs), we present an expert-based approach to large-scale multi-output regression using single-output GP experts. Employing a deeply structured mixture of single-output GPs encoded via a probabilistic circuit allows us to capture correlations between multiple output dimensions accurately. By recursively partitioning the covariate space and the output space, posterior inference in our model reduces to inference on single-output GP experts, which only need to be conditioned on a small subset of the observations. We show that inference can be performed exactly and efficiently in our model, that it can capture correlations between output dimensions and, hence, often outperforms approaches that do not incorporate inter-output correlations, as demonstrated on several data sets in terms of the negative log predictive density.
RECOWNs: Probabilistic Circuits for Trustworthy Time Series Forecasting
Jun 08, 2021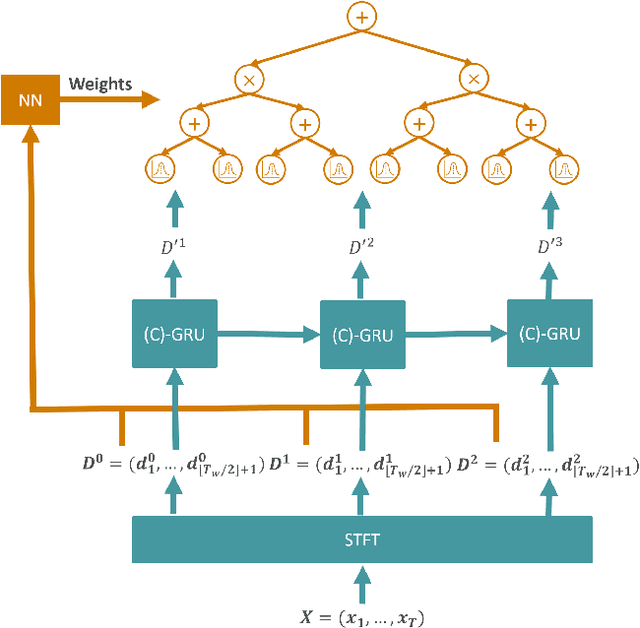


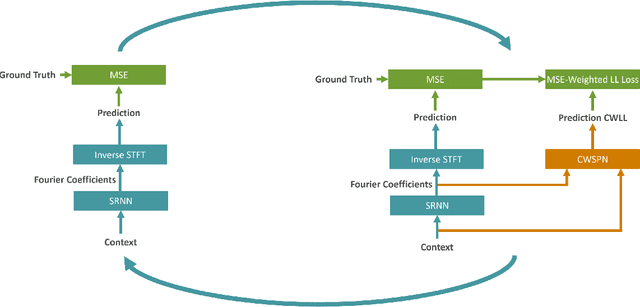
Time series forecasting is a relevant task that is performed in several real-world scenarios such as product sales analysis and prediction of energy demand. Given their accuracy performance, currently, Recurrent Neural Networks (RNNs) are the models of choice for this task. Despite their success in time series forecasting, less attention has been paid to make the RNNs trustworthy. For example, RNNs can not naturally provide an uncertainty measure to their predictions. This could be extremely useful in practice in several cases e.g. to detect when a prediction might be completely wrong due to an unusual pattern in the time series. Whittle Sum-Product Networks (WSPNs), prominent deep tractable probabilistic circuits (PCs) for time series, can assist an RNN with providing meaningful probabilities as uncertainty measure. With this aim, we propose RECOWN, a novel architecture that employs RNNs and a discriminant variant of WSPNs called Conditional WSPNs (CWSPNs). We also formulate a Log-Likelihood Ratio Score as better estimation of uncertainty that is tailored to time series and Whittle likelihoods. In our experiments, we show that RECOWNs are accurate and trustworthy time series predictors, able to "know when they do not know".
Few-Shot Learning for Video Object Detection in a Transfer-Learning Scheme
Mar 30, 2021
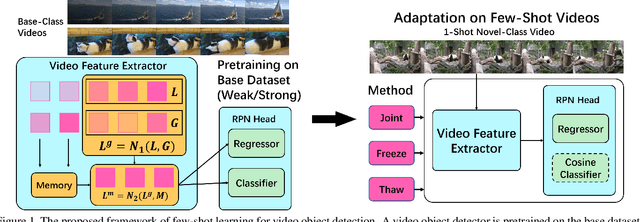
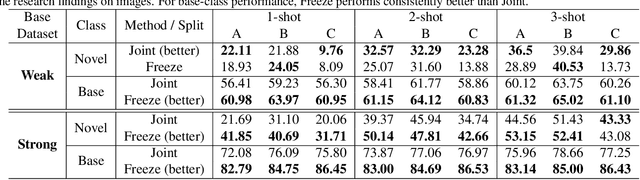
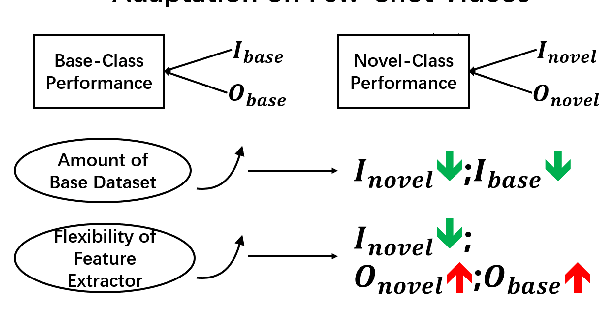
Different from static images, videos contain additional temporal and spatial information for better object detection. However, it is costly to obtain a large number of videos with bounding box annotations that are required for supervised deep learning. Although humans can easily learn to recognize new objects by watching only a few video clips, deep learning usually suffers from overfitting. This leads to an important question: how to effectively learn a video object detector from only a few labeled video clips? In this paper, we study the new problem of few-shot learning for video object detection. We first define the few-shot setting and create a new benchmark dataset for few-shot video object detection derived from the widely used ImageNet VID dataset. We employ a transfer-learning framework to effectively train the video object detector on a large number of base-class objects and a few video clips of novel-class objects. By analyzing the results of two methods under this framework (Joint and Freeze) on our designed weak and strong base datasets, we reveal insufficiency and overfitting problems. A simple but effective method, called Thaw, is naturally developed to trade off the two problems and validate our analysis. Extensive experiments on our proposed benchmark datasets with different scenarios demonstrate the effectiveness of our novel analysis in this new few-shot video object detection problem.
Looking back to lower-level information in few-shot learning
May 27, 2020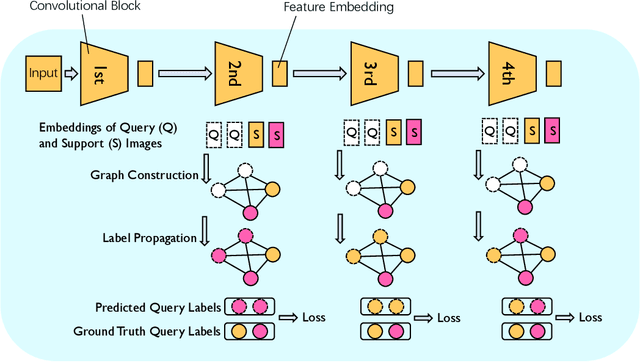
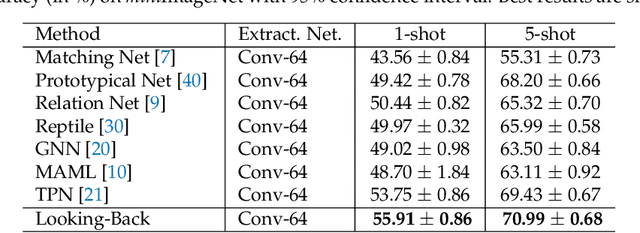

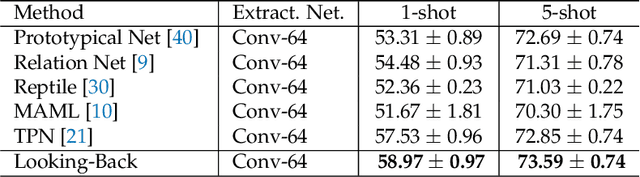
Humans are capable of learning new concepts from small numbers of examples. In contrast, supervised deep learning models usually lack the ability to extract reliable predictive rules from limited data scenarios when attempting to classify new examples. This challenging scenario is commonly known as few-shot learning. Few-shot learning has garnered increased attention in recent years due to its significance for many real-world problems. Recently, new methods relying on meta-learning paradigms combined with graph-based structures, which model the relationship between examples, have shown promising results on a variety of few-shot classification tasks. However, existing work on few-shot learning is only focused on the feature embeddings produced by the last layer of the neural network. In this work, we propose the utilization of lower-level, supporting information, namely the feature embeddings of the hidden neural network layers, to improve classifier accuracy. Based on a graph-based meta-learning framework, we develop a method called Looking-Back, where such lower-level information is used to construct additional graphs for label propagation in limited data settings. Our experiments on two popular few-shot learning datasets, miniImageNet and tieredImageNet, show that our method can utilize the lower-level information in the network to improve state-of-the-art classification performance.