 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGarments2Look: A Multi-Reference Dataset for High-Fidelity Outfit-Level Virtual Try-On with Clothing and Accessories
Mar 14, 2026Virtual try-on (VTON) has advanced single-garment visualization, yet real-world fashion centers on full outfits with multiple garments, accessories, fine-grained categories, layering, and diverse styling, remaining beyond current VTON systems. Existing datasets are category-limited and lack outfit diversity. We introduce Garments2Look, the first large-scale multimodal dataset for outfit-level VTON, comprising 80K many-garments-to-one-look pairs across 40 major categories and 300+ fine-grained subcategories. Each pair includes an outfit with 3-12 reference garment images (Average 4.48), a model image wearing the outfit, and detailed item and try-on textual annotations. To balance authenticity and diversity, we propose a synthesis pipeline. It involves heuristically constructing outfit lists before generating try-on results, with the entire process subjected to strict automated filtering and human validation to ensure data quality. To probe task difficulty, we adapt SOTA VTON methods and general-purpose image editing models to establish baselines. Results show current methods struggle to try on complete outfits seamlessly and to infer correct layering and styling, leading to misalignment and artifacts.
ECCENTRIC: Edge-Cloud Collaboration Framework for Distributed Inference Using Knowledge Adaptation
Nov 12, 2025The massive growth in the utilization of edge AI has made the applications of machine learning models ubiquitous in different domains. Despite the computation and communication efficiency of these systems, due to limited computation resources on edge devices, relying on more computationally rich systems on the cloud side is inevitable in most cases. Cloud inference systems can achieve the best performance while the computation and communication cost is dramatically increasing by the expansion of a number of edge devices relying on these systems. Hence, there is a trade-off between the computation, communication, and performance of these systems. In this paper, we propose a novel framework, dubbed as Eccentric that learns models with different levels of trade-offs between these conflicting objectives. This framework, based on an adaptation of knowledge from the edge model to the cloud one, reduces the computation and communication costs of the system during inference while achieving the best performance possible. The Eccentric framework can be considered as a new form of compression method suited for edge-cloud inference systems to reduce both computation and communication costs. Empirical studies on classification and object detection tasks corroborate the efficacy of this framework.
Data Efficient Training with Imbalanced Label Sample Distribution for Fashion Detection
May 15, 2023



Multi-label classification models have a wide range of applications in E-commerce, including visual-based label predictions and language-based sentiment classifications. A major challenge in achieving satisfactory performance for these tasks in the real world is the notable imbalance in data distribution. For instance, in fashion attribute detection, there may be only six 'puff sleeve' clothes among 1000 products in most E-commerce fashion catalogs. To address this issue, we explore more data-efficient model training techniques rather than acquiring a huge amount of annotations to collect sufficient samples, which is neither economic nor scalable. In this paper, we propose a state-of-the-art weighted objective function to boost the performance of deep neural networks (DNNs) for multi-label classification with long-tailed data distribution. Our experiments involve image-based attribute classification of fashion apparels, and the results demonstrate favorable performance for the new weighting method compared to non-weighted and inverse-frequency-based weighting mechanisms. We further evaluate the robustness of the new weighting mechanism using two popular fashion attribute types in today's fashion industry: sleevetype and archetype.
HalluAudio: Hallucinating Frequency as Concepts for Few-Shot Audio Classification
Feb 27, 2023



Few-shot audio classification is an emerging topic that attracts more and more attention from the research community. Most existing work ignores the specificity of the form of the audio spectrogram and focuses largely on the embedding space borrowed from image tasks, while in this work, we aim to take advantage of this special audio format and propose a new method by hallucinating high-frequency and low-frequency parts as structured concepts. Extensive experiments on ESC-50 and our curated balanced Kaggle18 dataset show the proposed method outperforms the baseline by a notable margin. The way that our method hallucinates high-frequency and low-frequency parts also enables its interpretability and opens up new potentials for the few-shot audio classification.
FedRule: Federated Rule Recommendation System with Graph Neural Networks
Nov 13, 2022



Much of the value that IoT (Internet-of-Things) devices bring to ``smart'' homes lies in their ability to automatically trigger other devices' actions: for example, a smart camera triggering a smart lock to unlock a door. Manually setting up these rules for smart devices or applications, however, is time-consuming and inefficient. Rule recommendation systems can automatically suggest rules for users by learning which rules are popular based on those previously deployed (e.g., in others' smart homes). Conventional recommendation formulations require a central server to record the rules used in many users' homes, which compromises their privacy and leaves them vulnerable to attacks on the central server's database of rules. Moreover, these solutions typically leverage generic user-item matrix methods that do not fully exploit the structure of the rule recommendation problem. In this paper, we propose a new rule recommendation system, dubbed as FedRule, to address these challenges. One graph is constructed per user upon the rules s/he is using, and the rule recommendation is formulated as a link prediction task in these graphs. This formulation enables us to design a federated training algorithm that is able to keep users' data private. Extensive experiments corroborate our claims by demonstrating that FedRule has comparable performance as the centralized setting and outperforms conventional solutions.
Package Theft Detection from Smart Home Security Cameras
May 24, 2022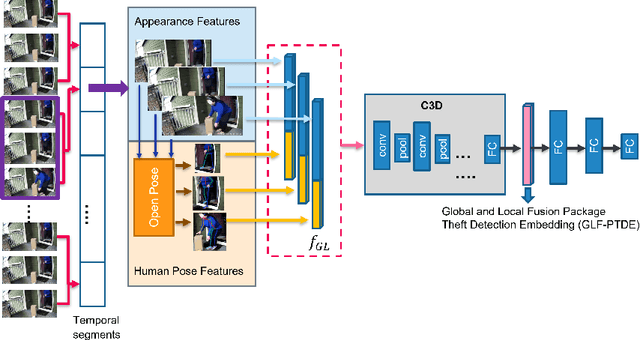

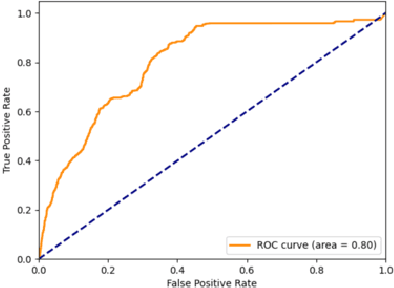

Package theft detection has been a challenging task mainly due to lack of training data and a wide variety of package theft cases in reality. In this paper, we propose a new Global and Local Fusion Package Theft Detection Embedding (GLF-PTDE) framework to generate package theft scores for each segment within a video to fulfill the real-world requirements on package theft detection. Moreover, we construct a novel Package Theft Detection dataset to facilitate the research on this task. Our method achieves 80% AUC performance on the newly proposed dataset, showing the effectiveness of the proposed GLF-PTDE framework and its robustness in different real scenes for package theft detection.
Adaptive Distillation: Aggregating Knowledge from Multiple Paths for Efficient Distillation
Oct 24, 2021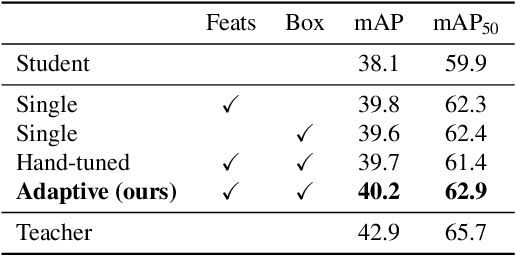
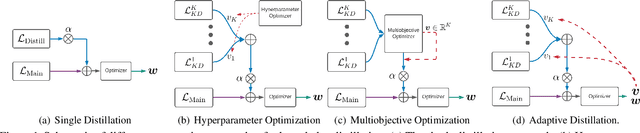
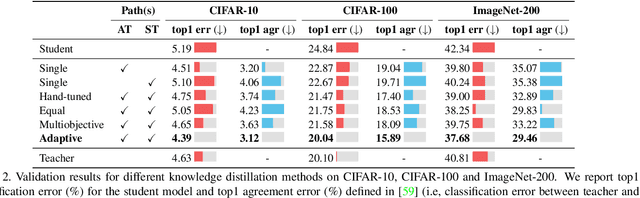
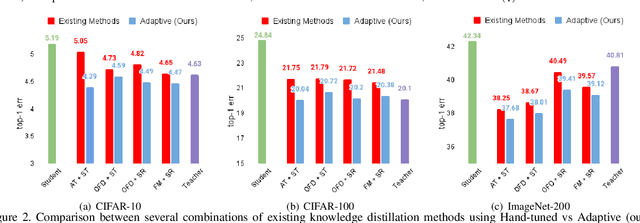
Knowledge Distillation is becoming one of the primary trends among neural network compression algorithms to improve the generalization performance of a smaller student model with guidance from a larger teacher model. This momentous rise in applications of knowledge distillation is accompanied by the introduction of numerous algorithms for distilling the knowledge such as soft targets and hint layers. Despite this advancement in different techniques for distilling the knowledge, the aggregation of different paths for distillation has not been studied comprehensively. This is of particular significance, not only because different paths have different importance, but also due to the fact that some paths might have negative effects on the generalization performance of the student model. Hence, we need to adaptively adjust the importance of each path to maximize the impact of distillation on the student model. In this paper, we explore different approaches for aggregating these different paths and introduce our proposed adaptive approach based on multitask learning methods. We empirically demonstrate the effectiveness of the proposed approach over other baselines on the applications of knowledge distillation in classification, semantic segmentation, and object detection tasks.
TransMatch: A Transfer-Learning Scheme for Semi-Supervised Few-Shot Learning
Dec 19, 2019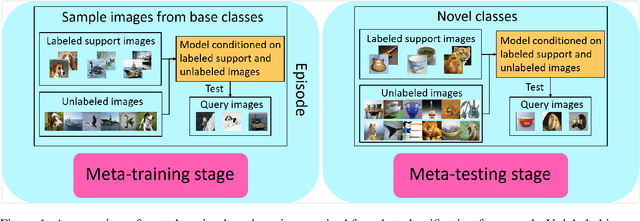
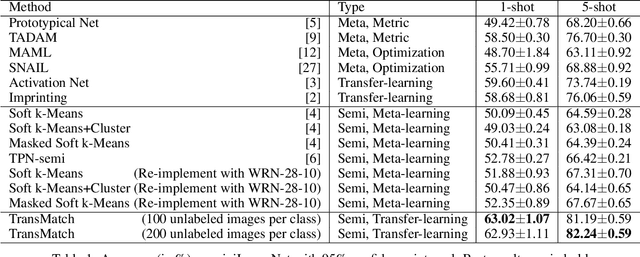
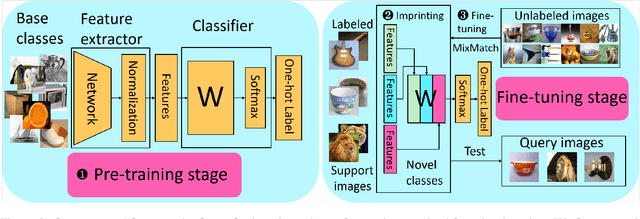
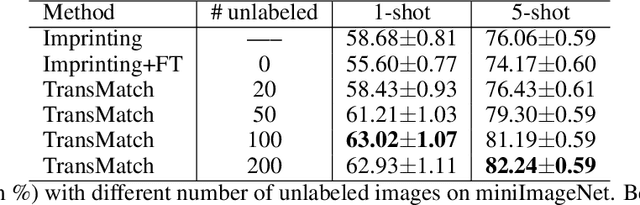
The successful application of deep learning to many visual recognition tasks relies heavily on the availability of a large amount of labeled data which is usually expensive to obtain. The few-shot learning problem has attracted increasing attention from researchers for building a robust model upon only a few labeled samples. Most existing works tackle this problem under the meta-learning framework by mimicking the few-shot learning task with an episodic training strategy. In this paper, we propose a new transfer-learning framework for semi-supervised few-shot learning to fully utilize the auxiliary information from labeled base-class data and unlabeled novel-class data. The framework consists of three components: 1) pre-training a feature extractor on base-class data; 2) using the feature extractor to initialize the classifier weights for the novel classes; and 3) further updating the model with a semi-supervised learning method. Under the proposed framework, we develop a novel method for semi-supervised few-shot learning called TransMatch by instantiating the three components with Imprinting and MixMatch. Extensive experiments on two popular benchmark datasets for few-shot learning, CUB-200-2011 and miniImageNet, demonstrate that our proposed method can effectively utilize the auxiliary information from labeled base-class data and unlabeled novel-class data to significantly improve the accuracy of few-shot learning task.
Open-Ended Visual Question Answering by Multi-Modal Domain Adaptation
Nov 11, 2019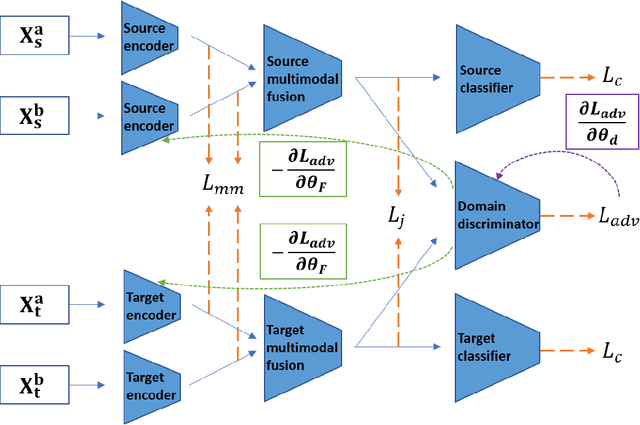


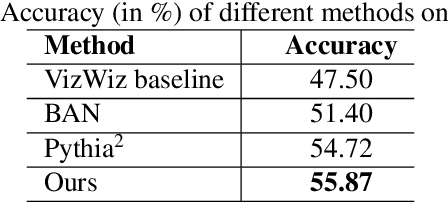
We study the problem of visual question answering (VQA) in images by exploiting supervised domain adaptation, where there is a large amount of labeled data in the source domain but only limited labeled data in the target domain with the goal to train a good target model. A straightforward solution is to fine-tune a pre-trained source model by using those limited labeled target data, but it usually cannot work well due to the considerable difference between the data distributions of the source and target domains. Moreover, the availability of multiple modalities (i.e., images, questions and answers) in VQA poses further challenges to model the transferability between those different modalities. In this paper, we tackle the above issues by proposing a novel supervised multi-modal domain adaptation method for VQA to learn joint feature embeddings across different domains and modalities. Specifically, we align the data distributions of the source and target domains by considering all modalities together as well as separately for each individual modality. Based on the extensive experiments on the benchmark VQA 2.0 and VizWiz datasets for the realistic open-ended VQA task, we demonstrate that our proposed method outperforms the existing state-of-the-art approaches in this challenging domain adaptation setting for VQA.
AI for Earth: Rainforest Conservation by Acoustic Surveillance
Aug 20, 2019
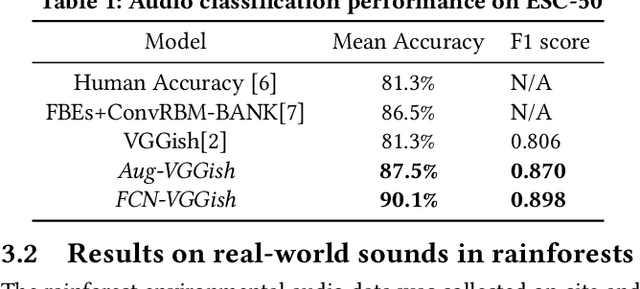
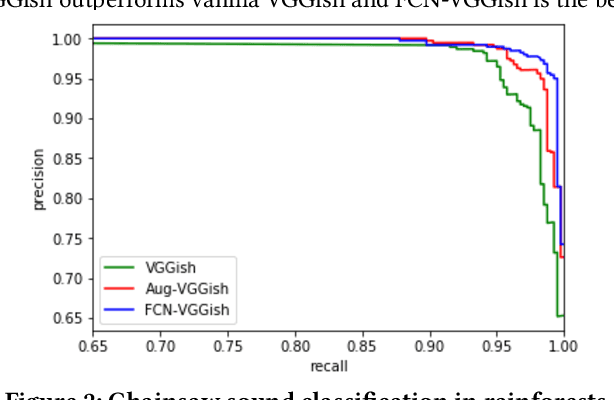
Saving rainforests is a key to halting adverse climate changes. In this paper, we introduce an innovative solution built on acoustic surveillance and machine learning technologies to help rainforest conservation. In particular, We propose new convolutional neural network (CNN) models for environmental sound classification and achieved promising preliminary results on two datasets, including a public audio dataset and our real rainforest sound dataset. The proposed audio classification models can be easily extended in an automated machine learning paradigm and integrated in cloud-based services for real world deployment.