 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Ended Visual Question Answering by Multi-Modal Domain Adaptation
Paper and Code
Nov 11, 2019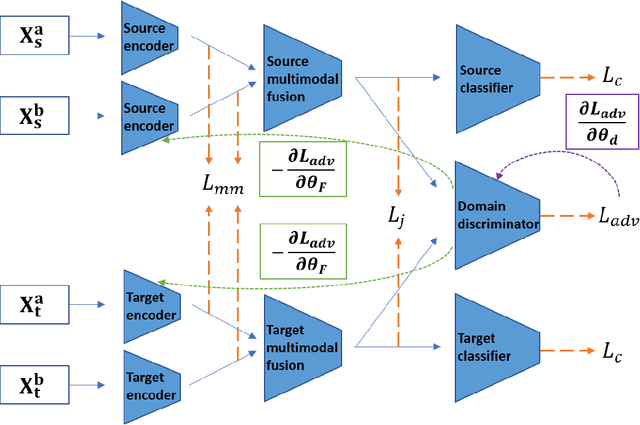


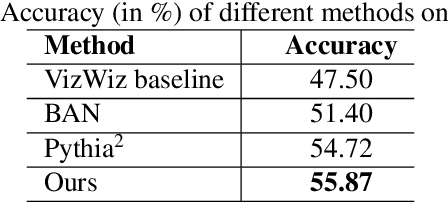
We study the problem of visual question answering (VQA) in images by exploiting supervised domain adaptation, where there is a large amount of labeled data in the source domain but only limited labeled data in the target domain with the goal to train a good target model. A straightforward solution is to fine-tune a pre-trained source model by using those limited labeled target data, but it usually cannot work well due to the considerable difference between the data distributions of the source and target domains. Moreover, the availability of multiple modalities (i.e., images, questions and answers) in VQA poses further challenges to model the transferability between those different modalities. In this paper, we tackle the above issues by proposing a novel supervised multi-modal domain adaptation method for VQA to learn joint feature embeddings across different domains and modalities. Specifically, we align the data distributions of the source and target domains by considering all modalities together as well as separately for each individual modality. Based on the extensive experiments on the benchmark VQA 2.0 and VizWiz datasets for the realistic open-ended VQA task, we demonstrate that our proposed method outperforms the existing state-of-the-art approaches in this challenging domain adaptation setting for VQA.