 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniSurg: A Video-Native Foundation Model for Universal Understanding of Surgical Videos
Feb 05, 2026While foundation models have advanced surgical video analysis, current approaches rely predominantly on pixel-level reconstruction objectives that waste model capacity on low-level visual details - such as smoke, specular reflections, and fluid motion - rather than semantic structures essential for surgical understanding. We present UniSurg, a video-native foundation model that shifts the learning paradigm from pixel-level reconstruction to latent motion prediction. Built on the Video Joint Embedding Predictive Architecture (V-JEPA), UniSurg introduces three key technical innovations tailored to surgical videos: 1) motion-guided latent prediction to prioritize semantically meaningful regions, 2) spatiotemporal affinity self-distillation to enforce relational consistency, and 3) feature diversity regularization to prevent representation collapse in texture-sparse surgical scenes. To enable large-scale pretraining, we curate UniSurg-15M, the largest surgical video dataset to date, comprising 3,658 hours of video from 50 sources across 13 anatomical regions. Extensive experiments across 17 benchmarks demonstrate that UniSurg significantly outperforms state-of-the-art methods on surgical workflow recognition (+14.6% F1 on EgoSurgery, +10.3% on PitVis), action triplet recognition (39.54% mAP-IVT on CholecT50), skill assessment, polyp segmentation, and depth estimation. These results establish UniSurg as a new standard for universal, motion-oriented surgical video understanding.
StreamSense: Streaming Social Task Detection with Selective Vision-Language Model Routing
Jan 30, 2026Live streaming platforms require real-time monitoring and reaction to social signals, utilizing partial and asynchronous evidence from video, text, and audio. We propose StreamSense, a streaming detector that couples a lightweight streaming encoder with selective routing to a Vision-Language Model (VLM) expert. StreamSense handles most timestamps with the lightweight streaming encoder, escalates hard/ambiguous cases to the VLM, and defers decisions when context is insufficient. The encoder is trained using (i) a cross-modal contrastive term to align visual/audio cues with textual signals, and (ii) an IoU-weighted loss that down-weights poorly overlapping target segments, mitigating label interference across segment boundaries. We evaluate StreamSense on multiple social streaming detection tasks (e.g., sentiment classification and hate content moderation), and the results show that StreamSense achieves higher accuracy than VLM-only streaming while only occasionally invoking the VLM, thereby reducing average latency and compute. Our results indicate that selective escalation and deferral are effective primitives for understanding streaming social tasks. Code is publicly available on GitHub.
Sphinx: Benchmarking and Modeling for LLM-Driven Pull Request Review
Jan 06, 2026Pull request (PR) review is essential for ensuring software quality, yet automating this task remains challenging due to noisy supervision, limited contextual understanding, and inadequate evaluation metrics. We present Sphinx, a unified framework for LLM-based PR review that addresses these limitations through three key components: (1) a structured data generation pipeline that produces context-rich, semantically grounded review comments by comparing pseudo-modified and merged code; (2) a checklist-based evaluation benchmark that assesses review quality based on structured coverage of actionable verification points, moving beyond surface-level metrics like BLEU; and (3) Checklist Reward Policy Optimization (CRPO), a novel training paradigm that uses rule-based, interpretable rewards to align model behavior with real-world review practices. Extensive experiments show that models trained with Sphinx achieve state-of-the-art performance on review completeness and precision, outperforming both proprietary and open-source baselines by up to 40\% in checklist coverage. Together, Sphinx enables the development of PR review models that are not only fluent but also context-aware, technically precise, and practically deployable in real-world development workflows. The data will be released after review.
A Versatile Multimodal Agent for Multimedia Content Generation
Jan 06, 2026With the advancement of AIGC (AI-generated content) technologies, an increasing number of generative models are revolutionizing fields such as video editing, music generation, and even film production. However, due to the limitations of current AIGC models, most models can only serve as individual components within specific application scenarios and are not capable of completing tasks end-to-end in real-world applications. In real-world applications, editing experts often work with a wide variety of images and video inputs, producing multimodal outputs -- a video typically includes audio, text, and other elements. This level of integration across multiple modalities is something current models are unable to achieve effectively. However, the rise of agent-based systems has made it possible to use AI tools to tackle complex content generation tasks. To deal with the complex scenarios, in this paper, we propose a MultiMedia-Agent designed to automate complex content creation. Our agent system includes a data generation pipeline, a tool library for content creation, and a set of metrics for evaluating preference alignment. Notably, we introduce the skill acquisition theory to model the training data curation and agent training. We designed a two-stage correlation strategy for plan optimization, including self-correlation and model preference correlation. Additionally, we utilized the generated plans to train the MultiMedia-Agent via a three stage approach including base/success plan finetune and preference optimization. The comparison results demonstrate that the our approaches are effective and the MultiMedia-Agent can generate better multimedia content compared to novel models.
LibContinual: A Comprehensive Library towards Realistic Continual Learning
Dec 26, 2025A fundamental challenge in Continual Learning (CL) is catastrophic forgetting, where adapting to new tasks degrades the performance on previous ones. While the field has evolved with diverse methods, this rapid surge in diverse methodologies has culminated in a fragmented research landscape. The lack of a unified framework, including inconsistent implementations, conflicting dependencies, and varying evaluation protocols, makes fair comparison and reproducible research increasingly difficult. To address this challenge, we propose LibContinual, a comprehensive and reproducible library designed to serve as a foundational platform for realistic CL. Built upon a high-cohesion, low-coupling modular architecture, LibContinual integrates 19 representative algorithms across five major methodological categories, providing a standardized execution environment. Meanwhile, leveraging this unified framework, we systematically identify and investigate three implicit assumptions prevalent in mainstream evaluation: (1) offline data accessibility, (2) unregulated memory resources, and (3) intra-task semantic homogeneity. We argue that these assumptions often overestimate the real-world applicability of CL methods. Through our comprehensive analysis using strict online CL settings, a novel unified memory budget protocol, and a proposed category-randomized setting, we reveal significant performance drops in many representative CL methods when subjected to these real-world constraints. Our study underscores the necessity of resource-aware and semantically robust CL strategies, and offers LibContinual as a foundational toolkit for future research in realistic continual learning. The source code is available from \href{https://github.com/RL-VIG/LibContinual}{https://github.com/RL-VIG/LibContinual}.
Anatomy-R1: Enhancing Anatomy Reasoning in Multimodal Large Language Models via Anatomical Similarity Curriculum and Group Diversity Augmentation
Dec 24, 2025Multimodal Large Language Models (MLLMs) have achieved impressive progress in natural image reasoning, yet their potential in medical imaging remains underexplored, especially in clinical anatomical surgical images. Anatomy understanding tasks demand precise understanding and clinically coherent answers, which are difficult to achieve due to the complexity of medical data and the scarcity of high-quality expert annotations. These challenges limit the effectiveness of conventional Supervised Fine-Tuning (SFT) strategies. While recent work has demonstrated that Group Relative Policy Optimization (GRPO) can enhance reasoning in MLLMs without relying on large amounts of data, we find two weaknesses that hinder GRPO's reasoning performance in anatomy recognition: 1) knowledge cannot be effectively shared between different anatomical structures, resulting in uneven information gain and preventing the model from converging, and 2) the model quickly converges to a single reasoning path, suppressing the exploration of diverse strategies. To overcome these challenges, we propose two novel methods. First, we implement a progressive learning strategy called Anatomical Similarity Curriculum Learning by controlling question difficulty via the similarity of answer choices, enabling the model to master complex problems incrementally. Second, we utilize question augmentation referred to as Group Diversity Question Augmentation to expand the model's search space for difficult queries, mitigating the tendency to produce uniform responses. Comprehensive experiments on the SGG-VQA and OmniMedVQA benchmarks show our method achieves a significant improvement across the two benchmarks, demonstrating its effectiveness in enhancing the medical reasoning capabilities of MLLMs. The code can be found in https://github.com/tomato996/Anatomy-R1
VisualActBench: Can VLMs See and Act like a Human?
Dec 10, 2025Vision-Language Models (VLMs) have achieved impressive progress in perceiving and describing visual environments. However, their ability to proactively reason and act based solely on visual inputs, without explicit textual prompts, remains underexplored. We introduce a new task, Visual Action Reasoning, and propose VisualActBench, a large-scale benchmark comprising 1,074 videos and 3,733 human-annotated actions across four real-world scenarios. Each action is labeled with an Action Prioritization Level (APL) and a proactive-reactive type to assess models' human-aligned reasoning and value sensitivity. We evaluate 29 VLMs on VisualActBench and find that while frontier models like GPT4o demonstrate relatively strong performance, a significant gap remains compared to human-level reasoning, particularly in generating proactive, high-priority actions. Our results highlight limitations in current VLMs' ability to interpret complex context, anticipate outcomes, and align with human decision-making frameworks. VisualActBench establishes a comprehensive foundation for assessing and improving the real-world readiness of proactive, vision-centric AI agents.
UniVA: Universal Video Agent towards Open-Source Next-Generation Video Generalist
Nov 11, 2025While specialized AI models excel at isolated video tasks like generation or understanding, real-world applications demand complex, iterative workflows that combine these capabilities. To bridge this gap, we introduce UniVA, an open-source, omni-capable multi-agent framework for next-generation video generalists that unifies video understanding, segmentation, editing, and generation into cohesive workflows. UniVA employs a Plan-and-Act dual-agent architecture that drives a highly automated and proactive workflow: a planner agent interprets user intentions and decomposes them into structured video-processing steps, while executor agents execute these through modular, MCP-based tool servers (for analysis, generation, editing, tracking, etc.). Through a hierarchical multi-level memory (global knowledge, task context, and user-specific preferences), UniVA sustains long-horizon reasoning, contextual continuity, and inter-agent communication, enabling interactive and self-reflective video creation with full traceability. This design enables iterative and any-conditioned video workflows (e.g., text/image/video-conditioned generation $\rightarrow$ multi-round editing $\rightarrow$ object segmentation $\rightarrow$ compositional synthesis) that were previously cumbersome to achieve with single-purpose models or monolithic video-language models. We also introduce UniVA-Bench, a benchmark suite of multi-step video tasks spanning understanding, editing, segmentation, and generation, to rigorously evaluate such agentic video systems. Both UniVA and UniVA-Bench are fully open-sourced, aiming to catalyze research on interactive, agentic, and general-purpose video intelligence for the next generation of multimodal AI systems. (https://univa.online/)
Video-LMM Post-Training: A Deep Dive into Video Reasoning with Large Multimodal Models
Oct 06, 2025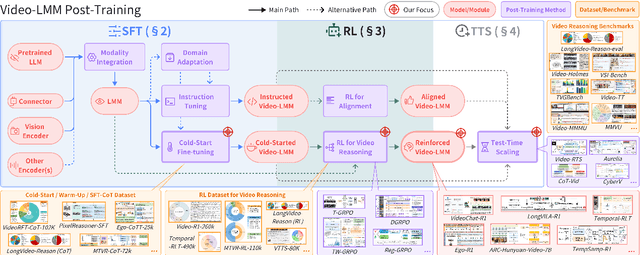
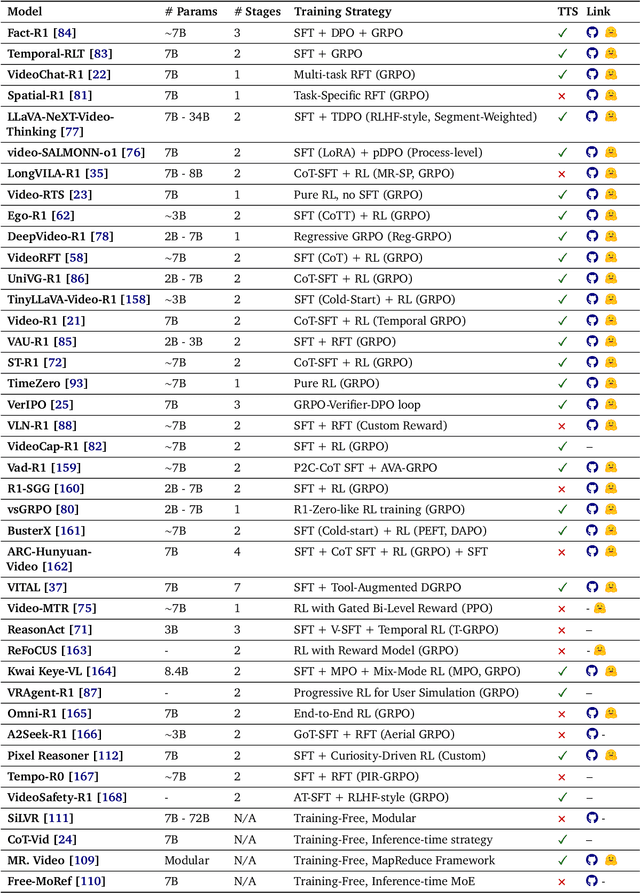
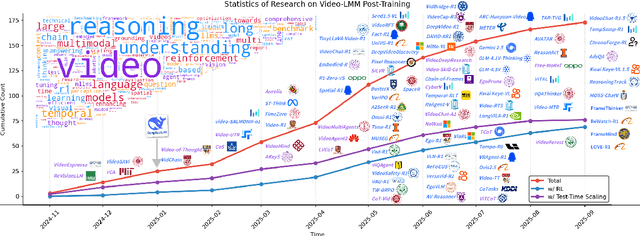
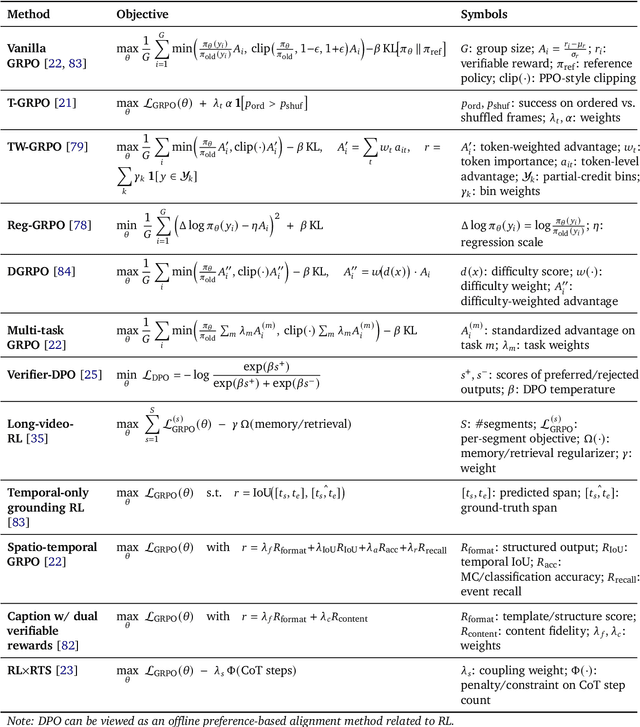
Video understanding represents the most challenging frontier in computer vision, requiring models to reason about complex spatiotemporal relationships, long-term dependencies, and multimodal evidence. The recent emergence of Video-Large Multimodal Models (Video-LMMs), which integrate visual encoders with powerful decoder-based language models, has demonstrated remarkable capabilities in video understanding tasks. However, the critical phase that transforms these models from basic perception systems into sophisticated reasoning engines, post-training, remains fragmented across the literature. This survey provides the first comprehensive examination of post-training methodologies for Video-LMMs, encompassing three fundamental pillars: supervised fine-tuning (SFT) with chain-of-thought, reinforcement learning (RL) from verifiable objectives, and test-time scaling (TTS) through enhanced inference computation. We present a structured taxonomy that clarifies the roles, interconnections, and video-specific adaptations of these techniques, addressing unique challenges such as temporal localization, spatiotemporal grounding, long video efficiency, and multimodal evidence integration. Through systematic analysis of representative methods, we synthesize key design principles, insights, and evaluation protocols while identifying critical open challenges in reward design, scalability, and cost-performance optimization. We further curate essential benchmarks, datasets, and metrics to facilitate rigorous assessment of post-training effectiveness. This survey aims to provide researchers and practitioners with a unified framework for advancing Video-LMM capabilities. Additional resources and updates are maintained at: https://github.com/yunlong10/Awesome-Video-LMM-Post-Training
Assessing Historical Structural Oppression Worldwide via Rule-Guided Prompting of Large Language Models
Sep 18, 2025



Traditional efforts to measure historical structural oppression struggle with cross-national validity due to the unique, locally specified histories of exclusion, colonization, and social status in each country, and often have relied on structured indices that privilege material resources while overlooking lived, identity-based exclusion. We introduce a novel framework for oppression measurement that leverages Large Language Models (LLMs) to generate context-sensitive scores of lived historical disadvantage across diverse geopolitical settings. Using unstructured self-identified ethnicity utterances from a multilingual COVID-19 global study, we design rule-guided prompting strategies that encourage models to produce interpretable, theoretically grounded estimations of oppression. We systematically evaluate these strategies across multiple state-of-the-art LLMs. Our results demonstrate that LLMs, when guided by explicit rules, can capture nuanced forms of identity-based historical oppression within nations. This approach provides a complementary measurement tool that highlights dimensions of systemic exclusion, offering a scalable, cross-cultural lens for understanding how oppression manifests in data-driven research and public health contexts. To support reproducible evaluation, we release an open-sourced benchmark dataset for assessing LLMs on oppression measurement (https://github.com/chattergpt/llm-oppression-benchmark).