 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKunlun: Establishing Scaling Laws for Massive-Scale Recommendation Systems through Unified Architecture Design
Feb 13, 2026Deriving predictable scaling laws that govern the relationship between model performance and computational investment is crucial for designing and allocating resources in massive-scale recommendation systems. While such laws are established for large language models, they remain challenging for recommendation systems, especially those processing both user history and context features. We identify poor scaling efficiency as the main barrier to predictable power-law scaling, stemming from inefficient modules with low Model FLOPs Utilization (MFU) and suboptimal resource allocation. We introduce Kunlun, a scalable architecture that systematically improves model efficiency and resource allocation. Our low-level optimizations include Generalized Dot-Product Attention (GDPA), Hierarchical Seed Pooling (HSP), and Sliding Window Attention. Our high-level innovations feature Computation Skip (CompSkip) and Event-level Personalization. These advances increase MFU from 17% to 37% on NVIDIA B200 GPUs and double scaling efficiency over state-of-the-art methods. Kunlun is now deployed in major Meta Ads models, delivering significant production impact.
Cross-attention Secretly Performs Orthogonal Alignment in Recommendation Models
Oct 10, 2025Cross-domain sequential recommendation (CDSR) aims to align heterogeneous user behavior sequences collected from different domains. While cross-attention is widely used to enhance alignment and improve recommendation performance, its underlying mechanism is not fully understood. Most researchers interpret cross-attention as residual alignment, where the output is generated by removing redundant and preserving non-redundant information from the query input by referencing another domain data which is input key and value. Beyond the prevailing view, we introduce Orthogonal Alignment, a phenomenon in which cross-attention discovers novel information that is not present in the query input, and further argue that those two contrasting alignment mechanisms can co-exist in recommendation models We find that when the query input and output of cross-attention are orthogonal, model performance improves over 300 experiments. Notably, Orthogonal Alignment emerges naturally, without any explicit orthogonality constraints. Our key insight is that Orthogonal Alignment emerges naturally because it improves scaling law. We show that baselines additionally incorporating cross-attention module outperform parameter-matched baselines, achieving a superior accuracy-per-model parameter. We hope these findings offer new directions for parameter-efficient scaling in multi-modal research.
Cabbage: A Differential Growth Framework for Open Surfaces
Apr 25, 2025



We propose Cabbage, a differential growth framework to model buckling behavior in 3D open surfaces found in nature-like the curling of flower petals. Cabbage creates high-quality triangular meshes free of self-intersection. Cabbage-Shell is driven by edge subdivision which differentially increases discretization resolution. Shell forces expands the surface, generating buckling over time. Feature-aware smoothing and remeshing ensures mesh quality. Corrective collision effectively prevents self-collision even in tight spaces. We additionally provide Cabbage-Collision, and approximate alternative, followed by CAD-ready surface generation. Cabbage is the first open-source effort with this calibre and robustness, outperforming SOTA methods in its morphological expressiveness, mesh quality, and stably generates large, complex patterns over hundreds of simulation steps. It is a source not only of computational modeling, digital fabrication, education, but also high-quality, annotated data for geometry processing and shape analysis.
DocAgent: A Multi-Agent System for Automated Code Documentation Generation
Apr 11, 2025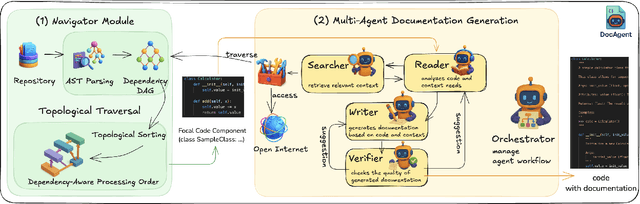
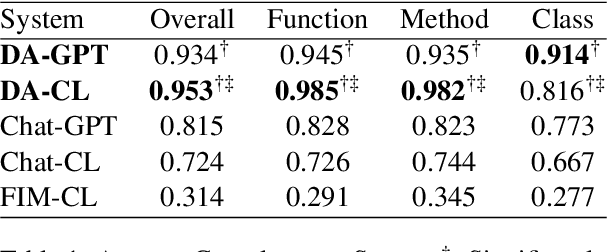
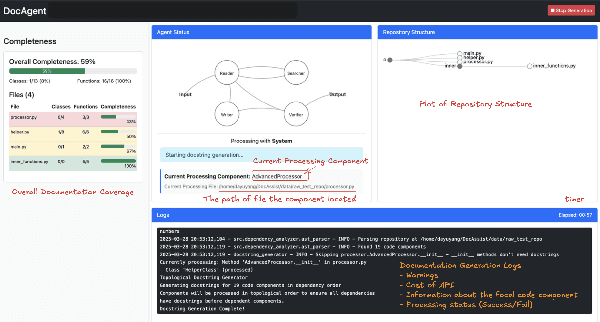

High-quality code documentation is crucial for software development especially in the era of AI. However, generating it automatically using Large Language Models (LLMs) remains challenging, as existing approaches often produce incomplete, unhelpful, or factually incorrect outputs. We introduce DocAgent, a novel multi-agent collaborative system using topological code processing for incremental context building. Specialized agents (Reader, Searcher, Writer, Verifier, Orchestrator) then collaboratively generate documentation. We also propose a multi-faceted evaluation framework assessing Completeness, Helpfulness, and Truthfulness. Comprehensive experiments show DocAgent significantly outperforms baselines consistently. Our ablation study confirms the vital role of the topological processing order. DocAgent offers a robust approach for reliable code documentation generation in complex and proprietary repositories.
Code to Think, Think to Code: A Survey on Code-Enhanced Reasoning and Reasoning-Driven Code Intelligence in LLMs
Feb 26, 2025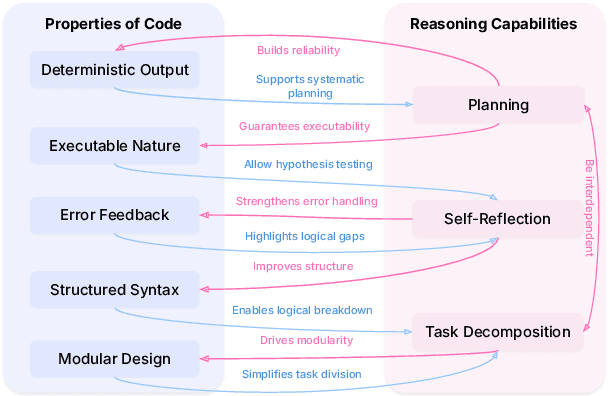
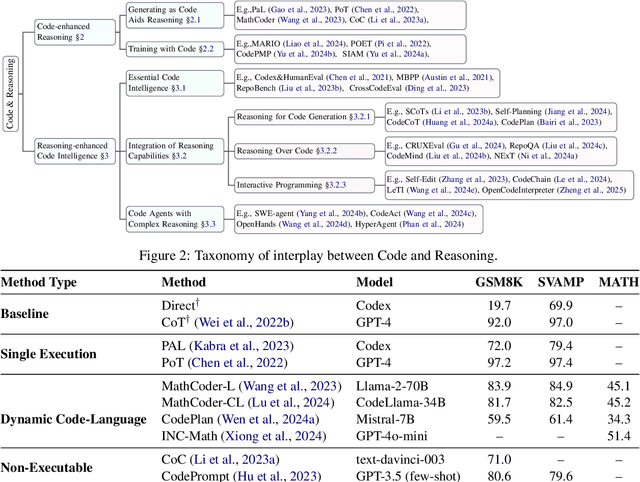


In large language models (LLMs), code and reasoning reinforce each other: code offers an abstract, modular, and logic-driven structure that supports reasoning, while reasoning translates high-level goals into smaller, executable steps that drive more advanced code intelligence. In this study, we examine how code serves as a structured medium for enhancing reasoning: it provides verifiable execution paths, enforces logical decomposition, and enables runtime validation. We also explore how improvements in reasoning have transformed code intelligence from basic completion to advanced capabilities, enabling models to address complex software engineering tasks through planning and debugging. Finally, we identify key challenges and propose future research directions to strengthen this synergy, ultimately improving LLM's performance in both areas.
External Large Foundation Model: How to Efficiently Serve Trillions of Parameters for Online Ads Recommendation
Feb 26, 2025



Ads recommendation is a prominent service of online advertising systems and has been actively studied. Recent studies indicate that scaling-up and advanced design of the recommendation model can bring significant performance improvement. However, with a larger model scale, such prior studies have a significantly increasing gap from industry as they often neglect two fundamental challenges in industrial-scale applications. First, training and inference budgets are restricted for the model to be served, exceeding which may incur latency and impair user experience. Second, large-volume data arrive in a streaming mode with data distributions dynamically shifting, as new users/ads join and existing users/ads leave the system. We propose the External Large Foundation Model (ExFM) framework to address the overlooked challenges. Specifically, we develop external distillation and a data augmentation system (DAS) to control the computational cost of training/inference while maintaining high performance. We design the teacher in a way like a foundation model (FM) that can serve multiple students as vertical models (VMs) to amortize its building cost. We propose Auxiliary Head and Student Adapter to mitigate the data distribution gap between FM and VMs caused by the streaming data issue. Comprehensive experiments on internal industrial-scale applications and public datasets demonstrate significant performance gain by ExFM.
Memory-Efficient Fine-Tuning of Transformers via Token Selection
Jan 31, 2025



Fine-tuning provides an effective means to specialize pre-trained models for various downstream tasks. However, fine-tuning often incurs high memory overhead, especially for large transformer-based models, such as LLMs. While existing methods may reduce certain parts of the memory required for fine-tuning, they still require caching all intermediate activations computed in the forward pass to update weights during the backward pass. In this work, we develop TokenTune, a method to reduce memory usage, specifically the memory to store intermediate activations, in the fine-tuning of transformer-based models. During the backward pass, TokenTune approximates the gradient computation by backpropagating through just a subset of input tokens. Thus, with TokenTune, only a subset of intermediate activations are cached during the forward pass. Also, TokenTune can be easily combined with existing methods like LoRA, further reducing the memory cost. We evaluate our approach on pre-trained transformer models with up to billions of parameters, considering the performance on multiple downstream tasks such as text classification and question answering in a few-shot learning setup. Overall, TokenTune achieves performance on par with full fine-tuning or representative memory-efficient fine-tuning methods, while greatly reducing the memory footprint, especially when combined with other methods with complementary memory reduction mechanisms. We hope that our approach will facilitate the fine-tuning of large transformers, in specializing them for specific domains or co-training them with other neural components from a larger system. Our code is available at https://github.com/facebookresearch/tokentune.
An Improved Dung Beetle Optimizer for Random Forest Optimization
Nov 24, 2024



To improve the convergence speed and optimization accuracy of the Dung Beetle Optimizer (DBO), this paper proposes an improved algorithm based on circle mapping and longitudinal-horizontal crossover strategy (CICRDBO). First, the Circle method is used to map the initial population to increase diversity. Second, the longitudinal-horizontal crossover strategy is applied to enhance the global search ability by ensuring the position updates of the dung beetle. Simulations were conducted on 10 benchmark test functions, and the results demonstrate that the improved algorithm performs well in both convergence speed and optimization accuracy. The improved algorithm is further applied to the hyperparameter selection of the Random Forest classification algorithm for binary classification prediction in the retail industry. Various combination comparisons prove the practicality of the improved algorithm, followed by SHapley Additive exPlanations (SHAP) analysis.
A Collaborative Ensemble Framework for CTR Prediction
Nov 20, 2024



Recent advances in foundation models have established scaling laws that enable the development of larger models to achieve enhanced performance, motivating extensive research into large-scale recommendation models. However, simply increasing the model size in recommendation systems, even with large amounts of data, does not always result in the expected performance improvements. In this paper, we propose a novel framework, Collaborative Ensemble Training Network (CETNet), to leverage multiple distinct models, each with its own embedding table, to capture unique feature interaction patterns. Unlike naive model scaling, our approach emphasizes diversity and collaboration through collaborative learning, where models iteratively refine their predictions. To dynamically balance contributions from each model, we introduce a confidence-based fusion mechanism using general softmax, where model confidence is computed via negation entropy. This design ensures that more confident models have a greater influence on the final prediction while benefiting from the complementary strengths of other models. We validate our framework on three public datasets (AmazonElectronics, TaobaoAds, and KuaiVideo) as well as a large-scale industrial dataset from Meta, demonstrating its superior performance over individual models and state-of-the-art baselines. Additionally, we conduct further experiments on the Criteo and Avazu datasets to compare our method with the multi-embedding paradigm. Our results show that our framework achieves comparable or better performance with smaller embedding sizes, offering a scalable and efficient solution for CTR prediction tasks.
DiffFNO: Diffusion Fourier Neural Operator
Nov 15, 2024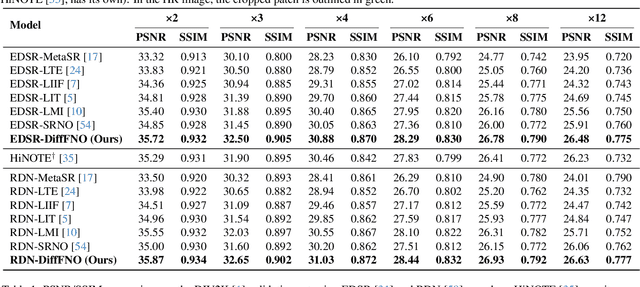
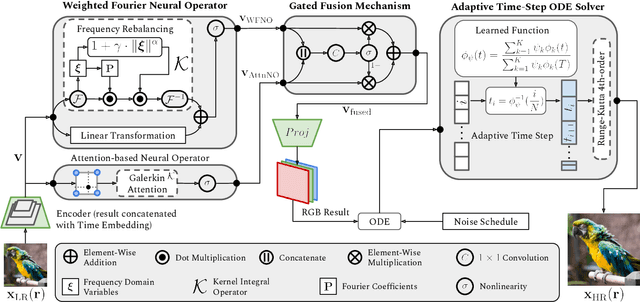
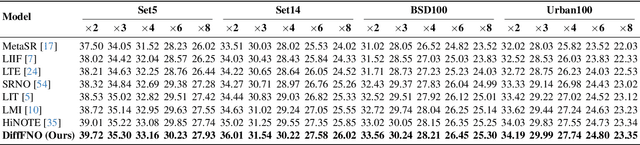

We introduce DiffFNO, a novel diffusion framework for arbitrary-scale super-resolution strengthened by a Weighted Fourier Neural Operator (WFNO). Mode Re-balancing in WFNO effectively captures critical frequency components, significantly improving the reconstruction of high-frequency image details that are crucial for super-resolution tasks. Gated Fusion Mechanism (GFM) adaptively complements WFNO's spectral features with spatial features from an Attention-based Neural Operator (AttnNO). This enhances the network's capability to capture both global structures and local details. Adaptive Time-Step (ATS) ODE solver, a deterministic sampling strategy, accelerates inference without sacrificing output quality by dynamically adjusting integration step sizes ATS. Extensive experiments demonstrate that DiffFNO achieves state-of-the-art (SOTA) results, outperforming existing methods across various scaling factors by a margin of 2 to 4 dB in PSNR, including those beyond the training distribution. It also achieves this at lower inference time. Our approach sets a new standard in super-resolution, delivering both superior accuracy and computational efficiency.