 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterFormer: Towards Effective Heterogeneous Interaction Learning for Click-Through Rate Prediction
Nov 15, 2024
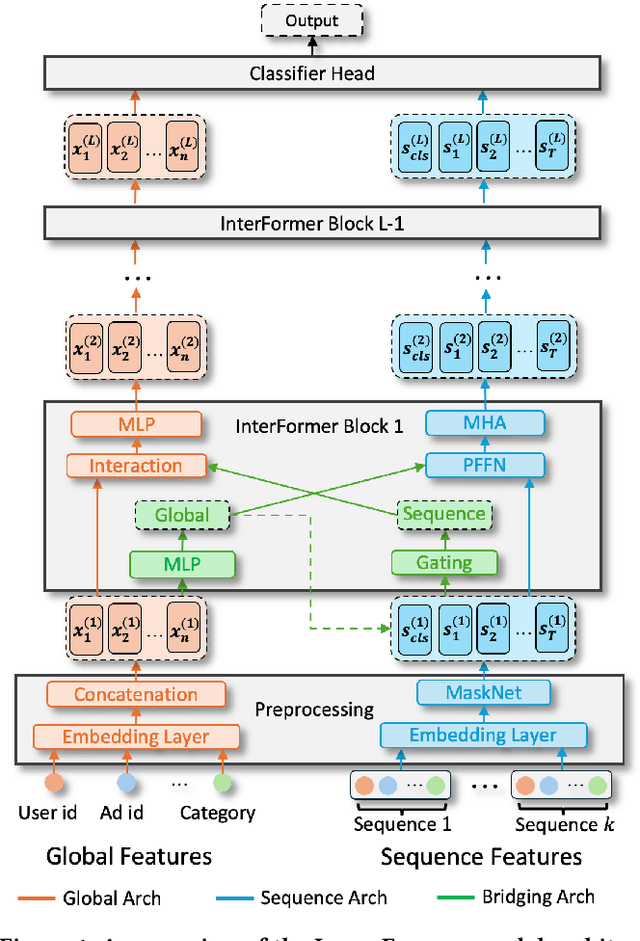
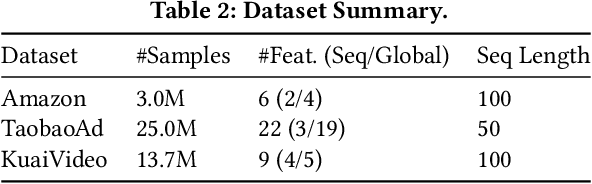
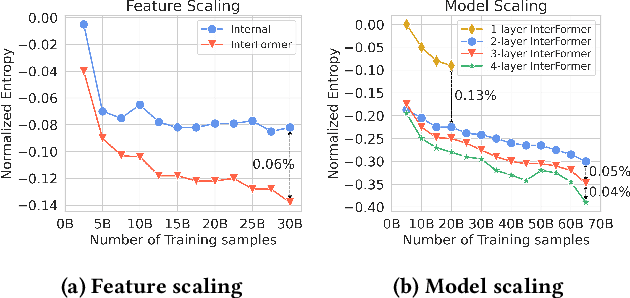
Click-through rate (CTR) prediction, which predicts the probability of a user clicking an ad, is a fundamental task in recommender systems. The emergence of heterogeneous information, such as user profile and behavior sequences, depicts user interests from different aspects. A mutually beneficial integration of heterogeneous information is the cornerstone towards the success of CTR prediction. However, most of the existing methods suffer from two fundamental limitations, including (1) insufficient inter-mode interaction due to the unidirectional information flow between modes, and (2) aggressive information aggregation caused by early summarization, resulting in excessive information loss. To address the above limitations, we propose a novel module named InterFormer to learn heterogeneous information interaction in an interleaving style. To achieve better interaction learning, InterFormer enables bidirectional information flow for mutually beneficial learning across different modes. To avoid aggressive information aggregation, we retain complete information in each data mode and use a separate bridging arch for effective information selection and summarization. Our proposed InterFormer achieves state-of-the-art performance on three public datasets and a large-scale industrial dataset.
Fair Concurrent Training of Multiple Models in Federated Learning
Apr 22, 2024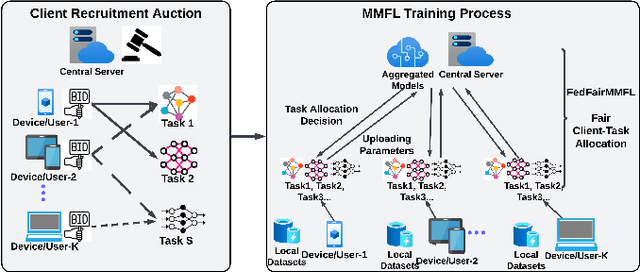
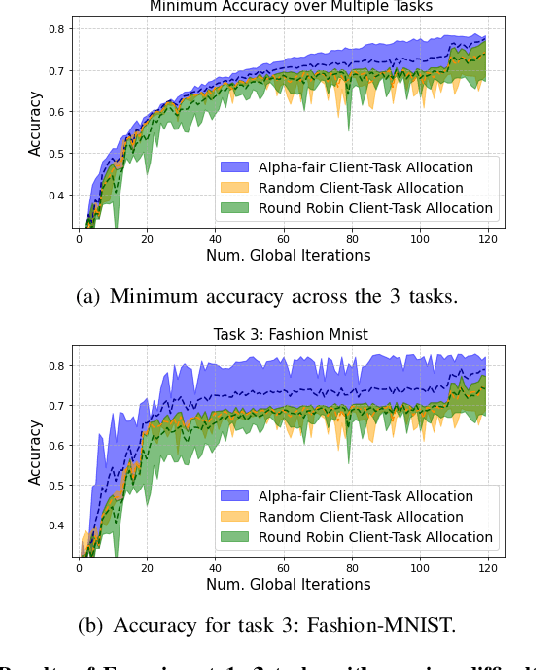
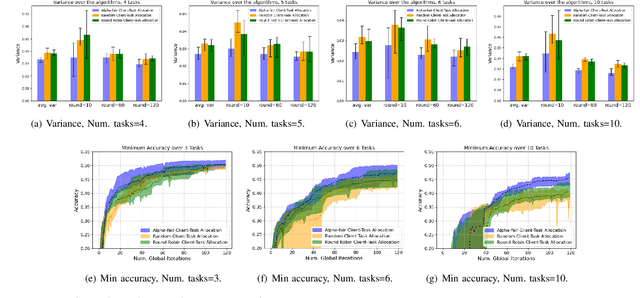
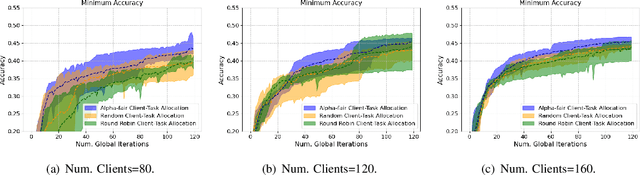
Federated learning (FL) enables collaborative learning across multiple clients. In most FL work, all clients train a single learning task. However, the recent proliferation of FL applications may increasingly require multiple FL tasks to be trained simultaneously, sharing clients' computing and communication resources, which we call Multiple-Model Federated Learning (MMFL). Current MMFL algorithms use naive average-based client-task allocation schemes that can lead to unfair performance when FL tasks have heterogeneous difficulty levels, e.g., tasks with larger models may need more rounds and data to train. Just as naively allocating resources to generic computing jobs with heterogeneous resource needs can lead to unfair outcomes, naive allocation of clients to FL tasks can lead to unfairness, with some tasks having excessively long training times, or lower converged accuracies. Furthermore, in the FL setting, since clients are typically not paid for their training effort, we face a further challenge that some clients may not even be willing to train some tasks, e.g., due to high computational costs, which may exacerbate unfairness in training outcomes across tasks. We address both challenges by firstly designing FedFairMMFL, a difficulty-aware algorithm that dynamically allocates clients to tasks in each training round. We provide guarantees on airness and FedFairMMFL's convergence rate. We then propose a novel auction design that incentivizes clients to train multiple tasks, so as to fairly distribute clients' training efforts across the tasks. We show how our fairness-based learning and incentive mechanisms impact training convergence and finally evaluate our algorithm with multiple sets of learning tasks on real world datasets.
FedSoft: Soft Clustered Federated Learning with Proximal Local Updating
Dec 11, 2021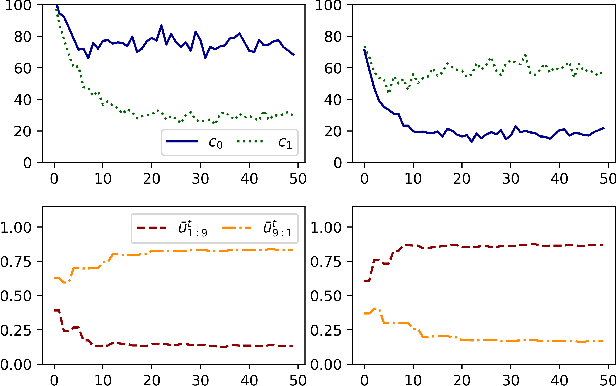
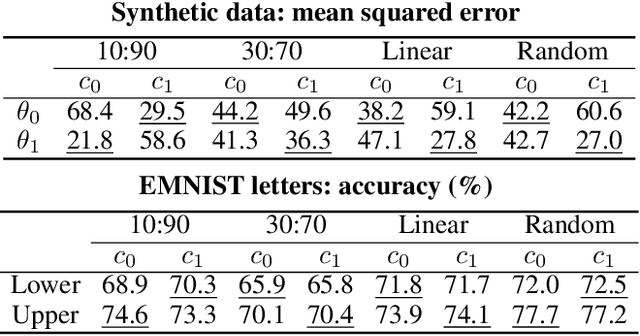
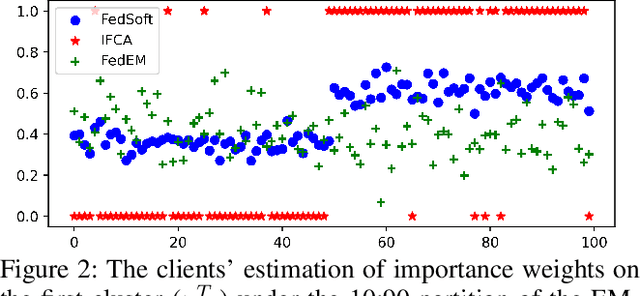
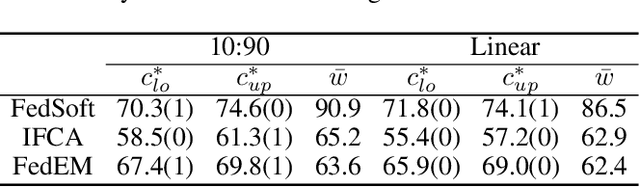
Traditionally, clustered federated learning groups clients with the same data distribution into a cluster, so that every client is uniquely associated with one data distribution and helps train a model for this distribution. We relax this hard association assumption to soft clustered federated learning, which allows every local dataset to follow a mixture of multiple source distributions. We propose FedSoft, which trains both locally personalized models and high-quality cluster models in this setting. FedSoft limits client workload by using proximal updates to require the completion of only one optimization task from a subset of clients in every communication round. We show, analytically and empirically, that FedSoft effectively exploits similarities between the source distributions to learn personalized and cluster models that perform well.
Towards Flexible Device Participation in Federated Learning for Non-IID Data
Jun 12, 2020
Traditional federated learning algorithms impose strict requirements on the participation rates of devices, which limit the potential reach of federated learning. In this paper, we extend the current learning paradigm and consider devices that may become inactive, compute incomplete updates, and leave or join in the middle of training. We derive analytical results to illustrate how the flexible participation of devices could affect the convergence when data is not independently and identically distributed (IID), and when devices are heterogeneous. This paper proposes a new federated aggregation scheme that converges even when devices may be inactive or return incomplete updates. We finally discuss practical research questions an operator would encounter during the training, and provide answers based on our convergence analysis.