 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSplain: Sparse and Smooth Explainer for Retinopathy of Prematurity Classification
Dec 08, 2025Neural networks are frequently used in medical diagnosis. However, due to their black-box nature, model explainers are used to help clinicians understand better and trust model outputs. This paper introduces an explainer method for classifying Retinopathy of Prematurity (ROP) from fundus images. Previous methods fail to generate explanations that preserve input image structures such as smoothness and sparsity. We introduce Sparse and Smooth Explainer (SSplain), a method that generates pixel-wise explanations while preserving image structures by enforcing smoothness and sparsity. This results in realistic explanations to enhance the understanding of the given black-box model. To achieve this goal, we define an optimization problem with combinatorial constraints and solve it using the Alternating Direction Method of Multipliers (ADMM). Experimental results show that SSplain outperforms commonly used explainers in terms of both post-hoc accuracy and smoothness analyses. Additionally, SSplain identifies features that are consistent with domain-understandable features that clinicians consider as discriminative factors for ROP. We also show SSplain's generalization by applying it to additional publicly available datasets. Code is available at https://github.com/neu-spiral/SSplain.
H-SPLID: HSIC-based Saliency Preserving Latent Information Decomposition
Oct 23, 2025We introduce H-SPLID, a novel algorithm for learning salient feature representations through the explicit decomposition of salient and non-salient features into separate spaces. We show that H-SPLID promotes learning low-dimensional, task-relevant features. We prove that the expected prediction deviation under input perturbations is upper-bounded by the dimension of the salient subspace and the Hilbert-Schmidt Independence Criterion (HSIC) between inputs and representations. This establishes a link between robustness and latent representation compression in terms of the dimensionality and information preserved. Empirical evaluations on image classification tasks show that models trained with H-SPLID primarily rely on salient input components, as indicated by reduced sensitivity to perturbations affecting non-salient features, such as image backgrounds. Our code is available at https://github.com/neu-spiral/H-SPLID.
Enabling Flexible Multi-LLM Integration for Scalable Knowledge Aggregation
May 28, 2025



Large language models (LLMs) have shown remarkable promise but remain challenging to continually improve through traditional finetuning, particularly when integrating capabilities from other specialized LLMs. Popular methods like ensemble and weight merging require substantial memory and struggle to adapt to changing data environments. Recent efforts have transferred knowledge from multiple LLMs into a single target model; however, they suffer from interference and degraded performance among tasks, largely due to limited flexibility in candidate selection and training pipelines. To address these issues, we propose a framework that adaptively selects and aggregates knowledge from diverse LLMs to build a single, stronger model, avoiding the high memory overhead of ensemble and inflexible weight merging. Specifically, we design an adaptive selection network that identifies the most relevant source LLMs based on their scores, thereby reducing knowledge interference. We further propose a dynamic weighted fusion strategy that accounts for the inherent strengths of candidate LLMs, along with a feedback-driven loss function that prevents the selector from converging on a single subset of sources. Experimental results demonstrate that our method can enable a more stable and scalable knowledge aggregation process while reducing knowledge interference by up to 50% compared to existing approaches. Code is avaliable at https://github.com/ZLKong/LLM_Integration
Spectral Survival Analysis
May 28, 2025Survival analysis is widely deployed in a diverse set of fields, including healthcare, business, ecology, etc. The Cox Proportional Hazard (CoxPH) model is a semi-parametric model often encountered in the literature. Despite its popularity, wide deployment, and numerous variants, scaling CoxPH to large datasets and deep architectures poses a challenge, especially in the high-dimensional regime. We identify a fundamental connection between rank regression and the CoxPH model: this allows us to adapt and extend the so-called spectral method for rank regression to survival analysis. Our approach is versatile, naturally generalizing to several CoxPH variants, including deep models. We empirically verify our method's scalability on multiple real-world high-dimensional datasets; our method outperforms legacy methods w.r.t. predictive performance and efficiency.
Dependency-aware Maximum Likelihood Estimation for Active Learning
Mar 07, 2025Active learning aims to efficiently build a labeled training set by strategically selecting samples to query labels from annotators. In this sequential process, each sample acquisition influences subsequent selections, causing dependencies among samples in the labeled set. However, these dependencies are overlooked during the model parameter estimation stage when updating the model using Maximum Likelihood Estimation (MLE), a conventional method that assumes independent and identically distributed (i.i.d.) data. We propose Dependency-aware MLE (DMLE), which corrects MLE within the active learning framework by addressing sample dependencies typically neglected due to the i.i.d. assumption, ensuring consistency with active learning principles in the model parameter estimation process. This improved method achieves superior performance across multiple benchmark datasets, reaching higher performance in earlier cycles compared to conventional MLE. Specifically, we observe average accuracy improvements of 6\%, 8.6\%, and 10.5\% for $k=1$, $k=5$, and $k=10$ respectively, after collecting the first 100 samples, where entropy is the acquisition function and $k$ is the query batch size acquired at every active learning cycle.
Learning Set Functions with Implicit Differentiation
Dec 17, 2024



Ou et al. (2022) introduce the problem of learning set functions from data generated by a so-called optimal subset oracle. Their approach approximates the underlying utility function with an energy-based model, whose parameters are estimated via mean-field variational inference. Ou et al. (2022) show this reduces to fixed point iterations; however, as the number of iterations increases, automatic differentiation quickly becomes computationally prohibitive due to the size of the Jacobians that are stacked during backpropagation. We address this challenge with implicit differentiation and examine the convergence conditions for the fixed-point iterations. We empirically demonstrate the efficiency of our method on synthetic and real-world subset selection applications including product recommendation, set anomaly detection and compound selection tasks.
Exploring Token Pruning in Vision State Space Models
Sep 27, 2024



State Space Models (SSMs) have the advantage of keeping linear computational complexity compared to attention modules in transformers, and have been applied to vision tasks as a new type of powerful vision foundation model. Inspired by the observations that the final prediction in vision transformers (ViTs) is only based on a subset of most informative tokens, we take the novel step of enhancing the efficiency of SSM-based vision models through token-based pruning. However, direct applications of existing token pruning techniques designed for ViTs fail to deliver good performance, even with extensive fine-tuning. To address this issue, we revisit the unique computational characteristics of SSMs and discover that naive application disrupts the sequential token positions. This insight motivates us to design a novel and general token pruning method specifically for SSM-based vision models. We first introduce a pruning-aware hidden state alignment method to stabilize the neighborhood of remaining tokens for performance enhancement. Besides, based on our detailed analysis, we propose a token importance evaluation method adapted for SSM models, to guide the token pruning. With efficient implementation and practical acceleration methods, our method brings actual speedup. Extensive experiments demonstrate that our approach can achieve significant computation reduction with minimal impact on performance across different tasks. Notably, we achieve 81.7\% accuracy on ImageNet with a 41.6\% reduction in the FLOPs for pruned PlainMamba-L3. Furthermore, our work provides deeper insights into understanding the behavior of SSM-based vision models for future research.
Efficient Federated Learning against Heterogeneous and Non-stationary Client Unavailability
Sep 26, 2024
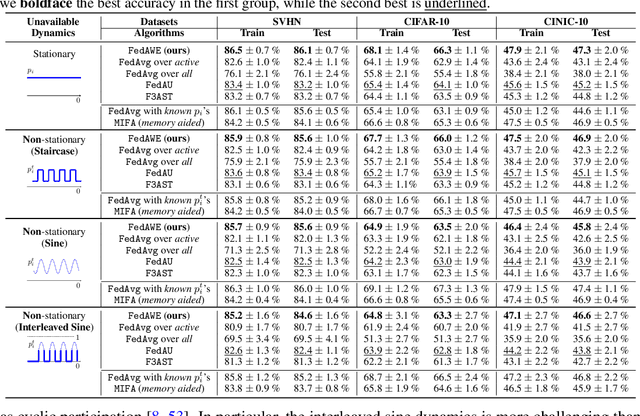
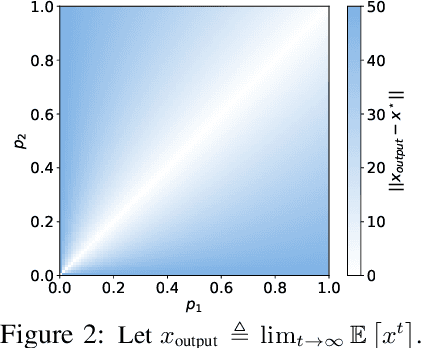

Addressing intermittent client availability is critical for the real-world deployment of federated learning algorithms. Most prior work either overlooks the potential non-stationarity in the dynamics of client unavailability or requires substantial memory/computation overhead. We study federated learning in the presence of heterogeneous and non-stationary client availability, which may occur when the deployment environments are uncertain or the clients are mobile. The impacts of the heterogeneity and non-stationarity in client unavailability can be significant, as we illustrate using FedAvg, the most widely adopted federated learning algorithm. We propose FedAPM, which includes novel algorithmic structures that (i) compensate for missed computations due to unavailability with only $O(1)$ additional memory and computation with respect to standard FedAvg, and (ii) evenly diffuse local updates within the federated learning system through implicit gossiping, despite being agnostic to non-stationary dynamics. We show that FedAPM converges to a stationary point of even non-convex objectives while achieving the desired linear speedup property. We corroborate our analysis with numerical experiments over diversified client unavailability dynamics on real-world data sets.
Harm Mitigation in Recommender Systems under User Preference Dynamics
Jun 14, 2024
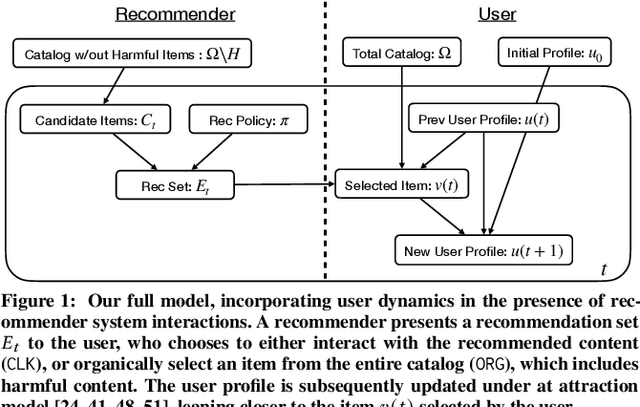
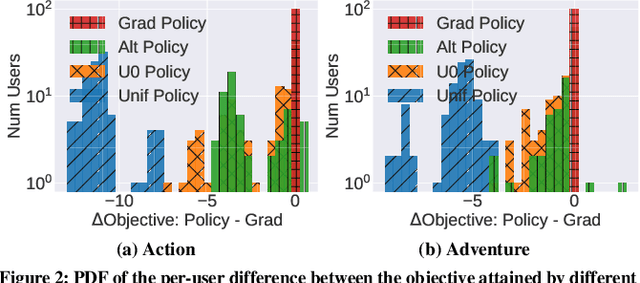
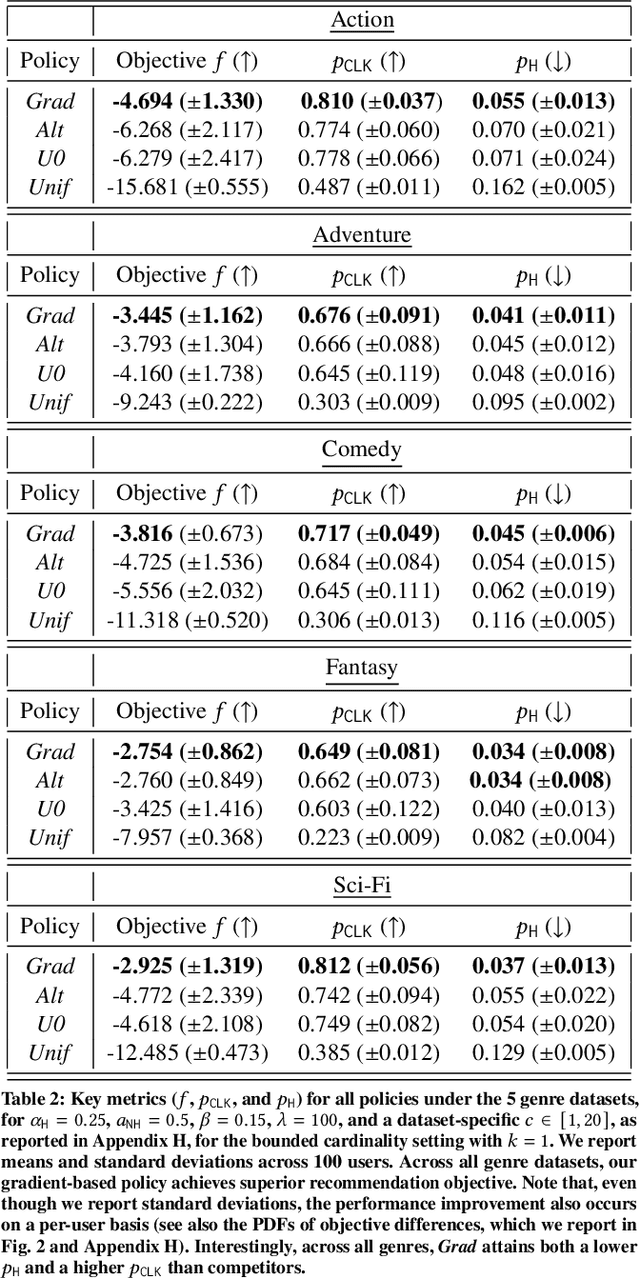
We consider a recommender system that takes into account the interplay between recommendations, the evolution of user interests, and harmful content. We model the impact of recommendations on user behavior, particularly the tendency to consume harmful content. We seek recommendation policies that establish a tradeoff between maximizing click-through rate (CTR) and mitigating harm. We establish conditions under which the user profile dynamics have a stationary point, and propose algorithms for finding an optimal recommendation policy at stationarity. We experiment on a semi-synthetic movie recommendation setting initialized with real data and observe that our policies outperform baselines at simultaneously maximizing CTR and mitigating harm.
Fair Concurrent Training of Multiple Models in Federated Learning
Apr 22, 2024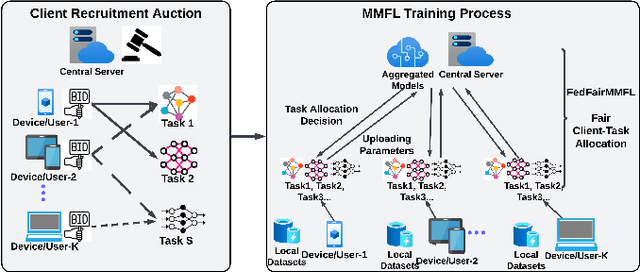
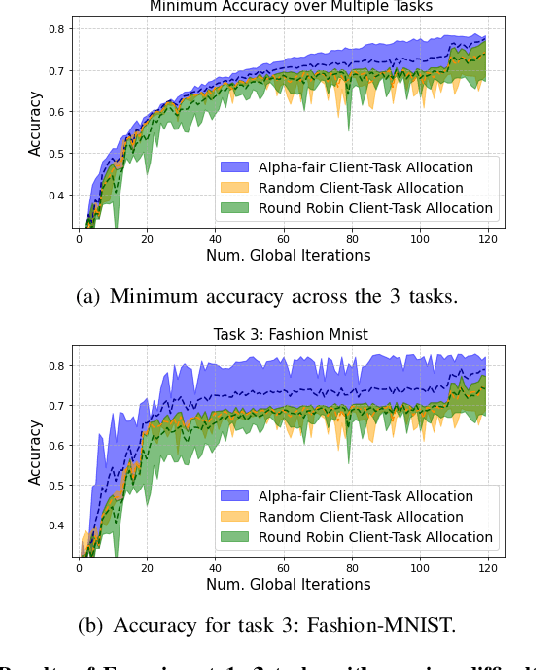
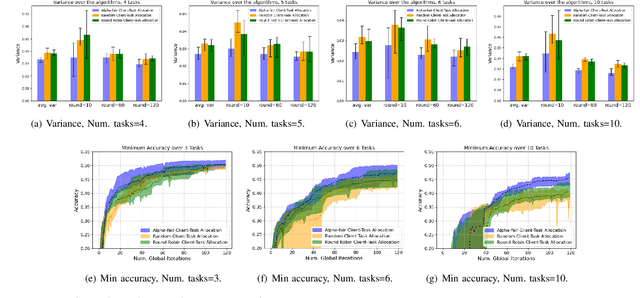
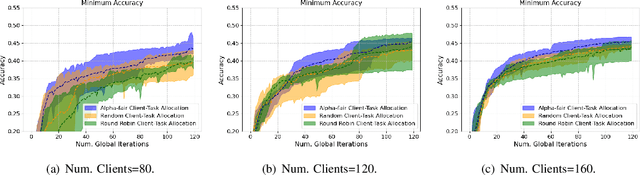
Federated learning (FL) enables collaborative learning across multiple clients. In most FL work, all clients train a single learning task. However, the recent proliferation of FL applications may increasingly require multiple FL tasks to be trained simultaneously, sharing clients' computing and communication resources, which we call Multiple-Model Federated Learning (MMFL). Current MMFL algorithms use naive average-based client-task allocation schemes that can lead to unfair performance when FL tasks have heterogeneous difficulty levels, e.g., tasks with larger models may need more rounds and data to train. Just as naively allocating resources to generic computing jobs with heterogeneous resource needs can lead to unfair outcomes, naive allocation of clients to FL tasks can lead to unfairness, with some tasks having excessively long training times, or lower converged accuracies. Furthermore, in the FL setting, since clients are typically not paid for their training effort, we face a further challenge that some clients may not even be willing to train some tasks, e.g., due to high computational costs, which may exacerbate unfairness in training outcomes across tasks. We address both challenges by firstly designing FedFairMMFL, a difficulty-aware algorithm that dynamically allocates clients to tasks in each training round. We provide guarantees on airness and FedFairMMFL's convergence rate. We then propose a novel auction design that incentivizes clients to train multiple tasks, so as to fairly distribute clients' training efforts across the tasks. We show how our fairness-based learning and incentive mechanisms impact training convergence and finally evaluate our algorithm with multiple sets of learning tasks on real world datasets.