 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSplain: Sparse and Smooth Explainer for Retinopathy of Prematurity Classification
Dec 08, 2025Neural networks are frequently used in medical diagnosis. However, due to their black-box nature, model explainers are used to help clinicians understand better and trust model outputs. This paper introduces an explainer method for classifying Retinopathy of Prematurity (ROP) from fundus images. Previous methods fail to generate explanations that preserve input image structures such as smoothness and sparsity. We introduce Sparse and Smooth Explainer (SSplain), a method that generates pixel-wise explanations while preserving image structures by enforcing smoothness and sparsity. This results in realistic explanations to enhance the understanding of the given black-box model. To achieve this goal, we define an optimization problem with combinatorial constraints and solve it using the Alternating Direction Method of Multipliers (ADMM). Experimental results show that SSplain outperforms commonly used explainers in terms of both post-hoc accuracy and smoothness analyses. Additionally, SSplain identifies features that are consistent with domain-understandable features that clinicians consider as discriminative factors for ROP. We also show SSplain's generalization by applying it to additional publicly available datasets. Code is available at https://github.com/neu-spiral/SSplain.
Trends and Challenges in Next-Generation GNSS Interference Management
Oct 31, 2025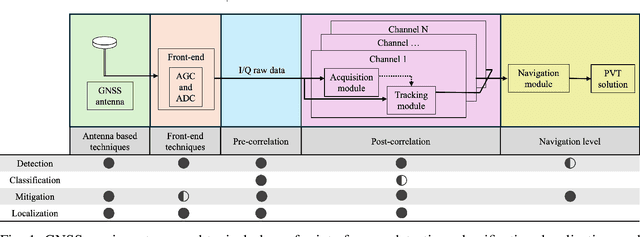
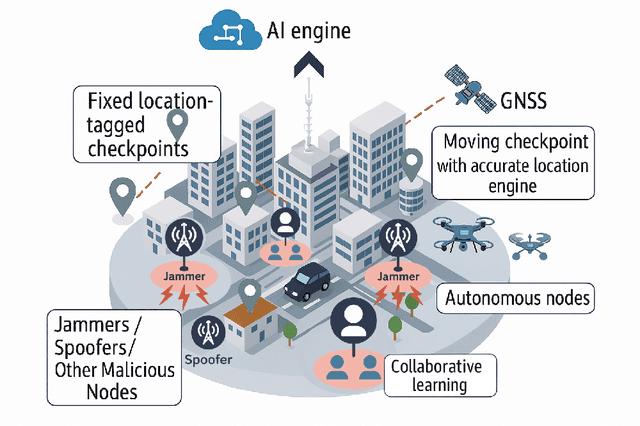
The global navigation satellite system (GNSS) continues to evolve in order to meet the demands of emerging applications such as autonomous driving and smart environmental monitoring. However, these advancements are accompanied by a rise in interference threats, which can significantly compromise the reliability and safety of GNSS. Such interference problems are typically addressed through signal-processing techniques that rely on physics-based mathematical models. Unfortunately, solutions of this nature can often fail to fully capture the complex forms of interference. To address this, artificial intelligence (AI)-inspired solutions are expected to play a key role in future interference management solutions, thanks to their ability to exploit data in addition to physics-based models. This magazine paper discusses the main challenges and tasks required to secure GNSS and present a research vision on how AI can be leveraged towards achieving more robust GNSS-based positioning.
Bayesian Jammer Localization with a Hybrid CNN and Path-Loss Mixture of Experts
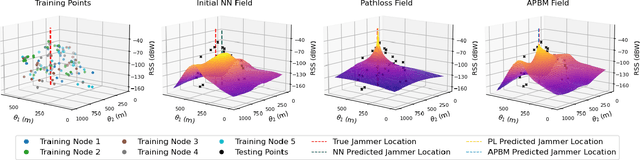
Oct 23, 2025Global Navigation Satellite System (GNSS) signals are vulnerable to jamming, particularly in urban areas where multipath and shadowing distort received power. Previous data-driven approaches achieved reasonable localization but poorly reconstructed the received signal strength (RSS) field due to limited spatial context. We propose a hybrid Bayesian mixture-of-experts framework that fuses a physical path-loss (PL) model and a convolutional neural network (CNN) through log-linear pooling. The PL expert ensures physical consistency, while the CNN leverages building-height maps to capture urban propagation effects. Bayesian inference with Laplace approximation provides posterior uncertainty over both the jammer position and RSS field. Experiments on urban ray-tracing data show that localization accuracy improves and uncertainty decreases with more training points, while uncertainty concentrates near the jammer and along urban canyons where propagation is most sensitive.
Robust Recursive Fusion of Multiresolution Multispectral Images with Location-Aware Neural Networks
Jun 16, 2025Multiresolution image fusion is a key problem for real-time satellite imaging and plays a central role in detecting and monitoring natural phenomena such as floods. It aims to solve the trade-off between temporal and spatial resolution in remote sensing instruments. Although several algorithms have been proposed for this problem, the presence of outliers such as clouds downgrades their performance. Moreover, strategies that integrate robustness, recursive operation and learned models are missing. In this paper, a robust recursive image fusion framework leveraging location-aware neural networks (NN) to model the image dynamics is proposed. Outliers are modeled by representing the probability of contamination of a given pixel and band. A NN model trained on a small dataset provides accurate predictions of the stochastic image time evolution, which improves both the accuracy and robustness of the method. A recursive solution is proposed to estimate the high-resolution images using a Bayesian variational inference framework. Experiments fusing images from the Landsat 8 and MODIS instruments show that the proposed approach is significantly more robust against cloud cover, without losing performance when no clouds are present.
Recursive Deep Inverse Reinforcement Learning
Apr 21, 2025Inferring an adversary's goals from exhibited behavior is crucial for counterplanning and non-cooperative multi-agent systems in domains like cybersecurity, military, and strategy games. Deep Inverse Reinforcement Learning (IRL) methods based on maximum entropy principles show promise in recovering adversaries' goals but are typically offline, require large batch sizes with gradient descent, and rely on first-order updates, limiting their applicability in real-time scenarios. We propose an online Recursive Deep Inverse Reinforcement Learning (RDIRL) approach to recover the cost function governing the adversary actions and goals. Specifically, we minimize an upper bound on the standard Guided Cost Learning (GCL) objective using sequential second-order Newton updates, akin to the Extended Kalman Filter (EKF), leading to a fast (in terms of convergence) learning algorithm. We demonstrate that RDIRL is able to recover cost and reward functions of expert agents in standard and adversarial benchmark tasks. Experiments on benchmark tasks show that our proposed approach outperforms several leading IRL algorithms.
Dependency-aware Maximum Likelihood Estimation for Active Learning
Mar 07, 2025Active learning aims to efficiently build a labeled training set by strategically selecting samples to query labels from annotators. In this sequential process, each sample acquisition influences subsequent selections, causing dependencies among samples in the labeled set. However, these dependencies are overlooked during the model parameter estimation stage when updating the model using Maximum Likelihood Estimation (MLE), a conventional method that assumes independent and identically distributed (i.i.d.) data. We propose Dependency-aware MLE (DMLE), which corrects MLE within the active learning framework by addressing sample dependencies typically neglected due to the i.i.d. assumption, ensuring consistency with active learning principles in the model parameter estimation process. This improved method achieves superior performance across multiple benchmark datasets, reaching higher performance in earlier cycles compared to conventional MLE. Specifically, we observe average accuracy improvements of 6\%, 8.6\%, and 10.5\% for $k=1$, $k=5$, and $k=10$ respectively, after collecting the first 100 samples, where entropy is the acquisition function and $k$ is the query batch size acquired at every active learning cycle.
MarkovType: A Markov Decision Process Strategy for Non-Invasive Brain-Computer Interfaces Typing Systems
Dec 20, 2024Brain-Computer Interfaces (BCIs) help people with severe speech and motor disabilities communicate and interact with their environment using neural activity. This work focuses on the Rapid Serial Visual Presentation (RSVP) paradigm of BCIs using noninvasive electroencephalography (EEG). The RSVP typing task is a recursive task with multiple sequences, where users see only a subset of symbols in each sequence. Extensive research has been conducted to improve classification in the RSVP typing task, achieving fast classification. However, these methods struggle to achieve high accuracy and do not consider the typing mechanism in the learning procedure. They apply binary target and non-target classification without including recursive training. To improve performance in the classification of symbols while controlling the classification speed, we incorporate the typing setup into training by proposing a Partially Observable Markov Decision Process (POMDP) approach. To the best of our knowledge, this is the first work to formulate the RSVP typing task as a POMDP for recursive classification. Experiments show that the proposed approach, MarkovType, results in a more accurate typing system compared to competitors. Additionally, our experiments demonstrate that while there is a trade-off between accuracy and speed, MarkovType achieves the optimal balance between these factors compared to other methods.
Learning Physics Informed Neural ODEs With Partial Measurements
Dec 11, 2024



Learning dynamics governing physical and spatiotemporal processes is a challenging problem, especially in scenarios where states are partially measured. In this work, we tackle the problem of learning dynamics governing these systems when parts of the system's states are not measured, specifically when the dynamics generating the non-measured states are unknown. Inspired by state estimation theory and Physics Informed Neural ODEs, we present a sequential optimization framework in which dynamics governing unmeasured processes can be learned. We demonstrate the performance of the proposed approach leveraging numerical simulations and a real dataset extracted from an electro-mechanical positioning system. We show how the underlying equations fit into our formalism and demonstrate the improved performance of the proposed method when compared with baselines.
A Bayesian Framework for Clustered Federated Learning
Oct 22, 2024One of the main challenges of federated learning (FL) is handling non-independent and identically distributed (non-IID) client data, which may occur in practice due to unbalanced datasets and use of different data sources across clients. Knowledge sharing and model personalization are key strategies for addressing this issue. Clustered federated learning is a class of FL methods that groups clients that observe similarly distributed data into clusters, such that every client is typically associated with one data distribution and participates in training a model for that distribution along their cluster peers. In this paper, we present a unified Bayesian framework for clustered FL which associates clients to clusters. Then we propose several practical algorithms to handle the, otherwise growing, data associations in a way that trades off performance and computational complexity. This work provides insights on client-cluster associations and enables client knowledge sharing in new ways. The proposed framework circumvents the need for unique client-cluster associations, which is seen to increase the performance of the resulting models in a variety of experiments.
Bayesian data fusion for distributed learning
Oct 20, 2024One of the main challenges of federated learning (FL) is handling non-independent and identically distributed (non-IID) client data, which may occur in practice due to unbalanced datasets and use of different data sources across clients. Knowledge sharing and model personalization are key strategies for addressing this issue. Clustered federated learning is a class of FL methods that groups clients that observe similarly distributed data into clusters, such that every client is typically associated with one data distribution and participates in training a model for that distribution along their cluster peers. In this paper, we present a unified Bayesian framework for clustered FL which associates clients to clusters. Then we propose several practical algorithms to handle the, otherwise growing, data associations in a way that trades off performance and computational complexity. This work provides insights on client-cluster associations and enables client knowledge sharing in new ways. The proposed framework circumvents the need for unique client-cluster associations, which is seen to increase the performance of the resulting models in a variety of experiments.