 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised End-to-End Array Calibration for Multi-Target Integrated Sensing and Communication
Apr 01, 2026In this work, we consider end-to-end calibration of an integrated sensing and communication (ISAC) base station (BS) under gain-phase and antenna displacement impairments without collecting signals from predefined positions (labeled data). We consider a BS with two impaired uniform linear arrays used for simultaneous multi-target sensing and communication with a user equipment (UE) leveraging orthogonal frequency-division multiplexing signals. The main contribution is the design of a framework that can compensate for the impairments without labeled data and considering coherent receive signals. We harness a differentiable precoder based on the maximum array response in an angular direction at the transmitter and the orthogonal matching pursuit (OMP) algorithm at the sensing receiver. We propose an ISAC loss as a combination of sensing and communication losses that provides a trade-off between the two functionalities. We compare two sensing objective alternatives: (i) maximize the maximum response of the angle-delay map of the targets or (ii) minimize the norm of the residual signal at the output of the OMP algorithm after all estimated targets have been removed. The communication objective maximizes the energy of the received signal at the UE. Additionally, our framework leverages an approximation of the channel gradient that avoids the impractical knowledge of the gradient of the channel. Our results show that the proposed method performs closely to using labeled data and knowledge of the channel gradient in terms of sensing position estimation and communication symbol error rate. When comparing the two sensing losses, minimizing the norm of the OMP residual yields significantly better sensing position estimation with slightly increased complexity.
WiMamba: Linear-Scale Wireless Foundation Model
Mar 27, 2026Foundation models learn transferable representations, motivating growing interest in their application to wireless systems. Existing wireless foundation models are predominantly based on transformer architectures, whose quadratic computational and memory complexity can hinder practical deployment for large-scale channels. In this work, we introduce WiMamba, a wireless foundation model built upon the recently proposed Mamba architecture, which replaces attention mechanisms with selective state-space models and enables linear-time sequence modeling. Leveraging this architectural advantage combined with adaptive preprocessing, WiMamba achieves scalable and low-latency inference while maintaining strong representational expressivity. We further develop a dedicated task-agnostic, self-supervised pre-training framework tailored to wireless channels, resulting in a genuine foundation model that learns transferable channel representations. Evaluations across four downstream tasks demonstrate that WiMamba matches or outperforms transformer-based wireless foundation models, while offering dramatic latency and memory reductions.
Knowledge Distillation for Collaborative Learning in Distributed Communications and Sensing
Mar 17, 2026The rise of sixth generation (6G) wireless networks promises to deliver ultra-reliable, low-latency, and energy-efficient communications, sensing, and computing. However, traditional centralized artificial intelligence (AI) paradigms are ill-suited to the decentralized, resource-constrained, and dynamic nature of 6G ecosystems. This paper explores knowledge distillation (KD) and collaborative learning as promising techniques that enable the efficient and scalable deployment of lightweight AI models across distributed communications and sensing (C&S) nodes. We begin by providing an overview of KD and highlight the key strengths that make it particularly effective in distributed scenarios characterized by device heterogeneity, task diversity, and constrained resources. We then examine its role in fostering collective intelligence through collaborative learning between the central and distributed nodes via various knowledge distilling and deployment strategies. Finally, we present a systematic numerical study demonstrating that KD-empowered collaborative learning can effectively support lightweight AI models for multi-modal sensing-assisted beam tracking applications with substantial performance gains and complexity reduction.
SGD-Based Knowledge Distillation with Bayesian Teachers: Theory and Guidelines
Jan 04, 2026Knowledge Distillation (KD) is a central paradigm for transferring knowledge from a large teacher network to a typically smaller student model, often by leveraging soft probabilistic outputs. While KD has shown strong empirical success in numerous applications, its theoretical underpinnings remain only partially understood. In this work, we adopt a Bayesian perspective on KD to rigorously analyze the convergence behavior of students trained with Stochastic Gradient Descent (SGD). We study two regimes: $(i)$ when the teacher provides the exact Bayes Class Probabilities (BCPs); and $(ii)$ supervision with noisy approximations of the BCPs. Our analysis shows that learning from BCPs yields variance reduction and removes neighborhood terms in the convergence bounds compared to one-hot supervision. We further characterize how the level of noise affects generalization and accuracy. Motivated by these insights, we advocate the use of Bayesian deep learning models, which typically provide improved estimates of the BCPs, as teachers in KD. Consistent with our analysis, we experimentally demonstrate that students distilled from Bayesian teachers not only achieve higher accuracies (up to +4.27%), but also exhibit more stable convergence (up to 30% less noise), compared to students distilled from deterministic teachers.
Online Learning of Modular Bayesian Deep Receivers: Single-Step Adaptation with Streaming Data
Nov 08, 2025Deep neural network (DNN)-based receivers offer a powerful alternative to classical model-based designs for wireless communication, especially in complex and nonlinear propagation environments. However, their adoption is challenged by the rapid variability of wireless channels, which makes pre-trained static DNN-based receivers ineffective, and by the latency and computational burden of online stochastic gradient descent (SGD)-based learning. In this work, we propose an online learning framework that enables rapid low-complexity adaptation of DNN-based receivers. Our approach is based on two main tenets. First, we cast online learning as Bayesian tracking in parameter space, enabling a single-step adaptation, which deviates from multi-epoch SGD . Second, we focus on modular DNN architectures that enable parallel, online, and localized variational Bayesian updates. Simulations with practical communication channels demonstrate that our proposed online learning framework can maintain a low error rate with markedly reduced update latency and increased robustness to channel dynamics as compared to traditional gradient descent based method.
AI-Aided Annealed Langevin Dynamics for Rapid Optimization of Programmable Channels
Oct 21, 2025Emerging technologies such as Reconfigurable Intelligent Surfaces (RIS) make it possible to optimize some parameters of wireless channels. Conventional approaches require relating the channel and its programmable parameters via a simple model that supports rapid optimization, e.g., re-tuning the parameters each time the users move. However, in practice such models are often crude approximations of the channel, and a more faithful description can be obtained via complex simulators, or only by measurements. In this work, we introduce a novel approach for rapid optimization of programmable channels based on AI-aided Annealed Langevin Dynamics (ALD), which bypasses the need for explicit channel modeling. By framing the ALD algorithm using the MAP estimate, we design a deep unfolded ALD algorithm that leverages a Deep Neural Network (DNN) to estimate score gradients for optimizing channel parameters. We introduce a training method that overcomes the need for channel modeling using zero-order gradients, combined with active learning to enhance generalization, enabling optimization in complex and dynamically changing environments. We evaluate the proposed method in RIS-aided scenarios subject to rich-scattering effects. Our results demonstrate that our AI-aided ALD method enables rapid and reliable channel parameter tuning with limited latency.
Hybrid RISs for Simultaneous Tunable Reflections and Sensing
Jul 22, 2025The concept of smart wireless environments envisions dynamic programmable propagation of information-bearing signals through the deployment of Reconfigurable Intelligent Surfaces (RISs). Typical RIS implementations include metasurfaces with passive unit elements capable to reflect their incident waves in controllable ways. However, this solely reflective operation induces significant challenges in the RIS orchestration from the wireless network. For example, channel estimation, which is essential for coherent RIS-empowered wireless communications, is quite challenging with the available solely reflecting RIS designs. This chapter reviews the emerging concept of Hybrid Reflecting and Sensing RISs (HRISs), which enables metasurfaces to reflect the impinging signal in a controllable manner, while simultaneously sensing a portion of it. The sensing capability of HRISs facilitates various network management functionalities, including channel parameter estimation and localization, while, most importantly, giving rise to computationally autonomous and self-configuring RISs. The implementation details of HRISs are first presented, which are then followed by a convenient mathematical model for characterizing their dual functionality. Then, two indicative applications of HRISs are discussed, one for simultaneous communications and sensing and another that showcases their usefulness for estimating the individual channels in the uplink of a multi-user HRIS-empowered communication system. For both of these applications, performance evaluation results are included validating the role of HRISs for sensing as well as integrated sensing and communications.
In-Context Learning for Gradient-Free Receiver Adaptation: Principles, Applications, and Theory
Jun 18, 2025In recent years, deep learning has facilitated the creation of wireless receivers capable of functioning effectively in conditions that challenge traditional model-based designs. Leveraging programmable hardware architectures, deep learning-based receivers offer the potential to dynamically adapt to varying channel environments. However, current adaptation strategies, including joint training, hypernetwork-based methods, and meta-learning, either demonstrate limited flexibility or necessitate explicit optimization through gradient descent. This paper presents gradient-free adaptation techniques rooted in the emerging paradigm of in-context learning (ICL). We review architectural frameworks for ICL based on Transformer models and structured state-space models (SSMs), alongside theoretical insights into how sequence models effectively learn adaptation from contextual information. Further, we explore the application of ICL to cell-free massive MIMO networks, providing both theoretical analyses and empirical evidence. Our findings indicate that ICL represents a principled and efficient approach to real-time receiver adaptation using pilot signals and auxiliary contextual information-without requiring online retraining.
Adaptive Deadline and Batch Layered Synchronized Federated Learning
May 29, 2025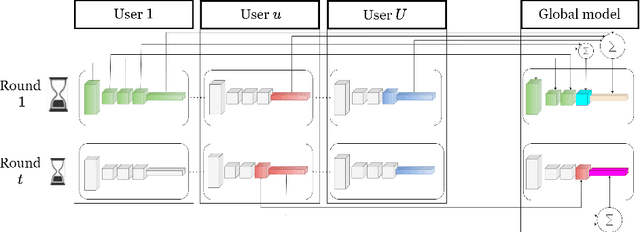
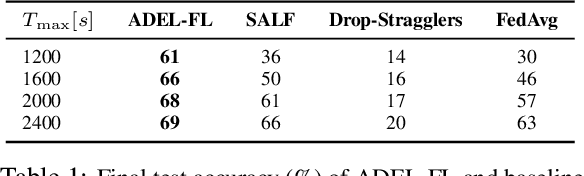
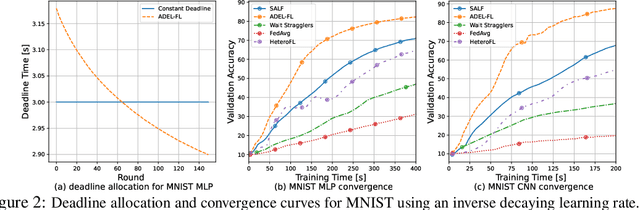
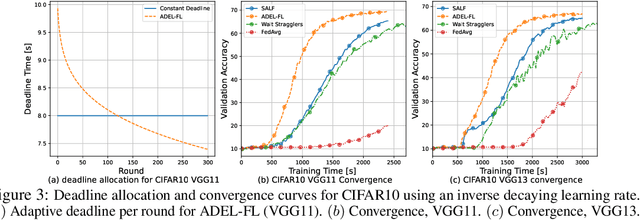
Federated learning (FL) enables collaborative model training across distributed edge devices while preserving data privacy, and typically operates in a round-based synchronous manner. However, synchronous FL suffers from latency bottlenecks due to device heterogeneity, where slower clients (stragglers) delay or degrade global updates. Prior solutions, such as fixed deadlines, client selection, and layer-wise partial aggregation, alleviate the effect of stragglers, but treat round timing and local workload as static parameters, limiting their effectiveness under strict time constraints. We propose ADEL-FL, a novel framework that jointly optimizes per-round deadlines and user-specific batch sizes for layer-wise aggregation. Our approach formulates a constrained optimization problem minimizing the expected L2 distance to the global optimum under total training time and global rounds. We provide a convergence analysis under exponential compute models and prove that ADEL-FL yields unbiased updates with bounded variance. Extensive experiments demonstrate that ADEL-FL outperforms alternative methods in both convergence rate and final accuracy under heterogeneous conditions.
EOTNet: Deep Memory Aided Bayesian Filter for Extended Object Tracking
May 24, 2025Extended object tracking methods based on random matrices, founded on Bayesian filters, have been able to achieve efficient recursive processes while jointly estimating the kinematic states and extension of the targets. Existing random matrix approaches typically assume that the evolution of state and extension follows a first-order Markov process, where the current estimate of the target depends solely on the previous moment. However, in real-world scenarios, this assumption fails because the evolution of states and extension is usually non-Markovian. In this paper, we introduce a novel extended object tracking method: a Bayesian recursive neural network assisted by deep memory. Initially, we propose an equivalent model under a non-Markovian assumption and derive the implementation of its Bayesian filtering framework. Thereafter, Gaussian approximation and moment matching are employed to derive the analytical solution for the proposed Bayesian filtering framework. Finally, based on the closed-form solution, we design an end-to-end trainable Bayesian recursive neural network for extended object tracking. Experiment results on simulated and real-world datasets show that the proposed methods outperforms traditional extended object tracking methods and state-of-the-art deep learning approaches.