 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBionic Human-Motion Style Transfer for Physically Executable Whole-Body Control of Humanoid Robots
Jun 02, 2026Expressive whole-body motion is important for humanoid robots operating in human environments, where robots are expected to move stably while presenting readable and adjustable body behaviors. However, most expressive motions are still obtained from fixed demonstrations or manually designed scripts, making it difficult to reuse a demonstrated style across different motion contents. Inspired by the way human motion styles convey affective and intentional cues through gait rhythm, posture, arm swing and body sway, this paper proposes a bionic generation-to-control framework for exemplar-driven style transfer on humanoid robots. Given a short human style exemplar and a target content motion, the proposed framework generates a stylized whole-body reference that preserves the intended motion content while transferring the demonstrated style. A physics-aware multi-condition latent diffusion model is developed to fuse style, content and trajectory conditions, and classifier-free guidance is used to adjust the style intensity without retraining. To improve hardware executability, contact-consistency and temporal-smoothness regularization are imposed on decoded motions during training. The generated references are then converted into G1-compatible robot references and executed by a preview-based whole-body tracking policy trained with a cluster-and-distill strategy. Simulation and Unitree G1 experiments show that the proposed method can transfer short human style exemplars to diverse robot motion contents, reduce contact and jitter artifacts compared with animation-oriented style-transfer baselines, and achieve a 96.0% success rate over 125 reported real-robot trials. The results demonstrate the feasibility of using short human motion exemplars as reusable bionic sources for physically executable expressive humanoid motion.
OD-DEAL: Dynamic Expert-Guided Adversarial Learning with Online Decomposition for Scalable Capacitated Vehicle Routing
Feb 03, 2026Solving large-scale capacitated vehicle routing problems (CVRP) is hindered by the high complexity of heuristics and the limited generalization of neural solvers on massive graphs. We propose OD-DEAL, an adversarial learning framework that tightly integrates hybrid genetic search (HGS) and online barycenter clustering (BCC) decomposition, and leverages high-fidelity knowledge distillation to transfer expert heuristic behavior. OD-DEAL trains a graph attention network (GAT)-based generative policy through a minimax game, in which divide-and-conquer strategies from a hybrid expert are distilled into dense surrogate rewards. This enables high-quality, clustering-free inference on large-scale instances. Empirical results demonstrate that OD-DEAL achieves state-of-the-art (SOTA) real-time CVRP performance, solving 10000-node instances with near-constant neural scaling. This uniquely enables the sub-second, heuristic-quality inference required for dynamic large-scale deployment.
Lumine: An Open Recipe for Building Generalist Agents in 3D Open Worlds
Nov 12, 2025
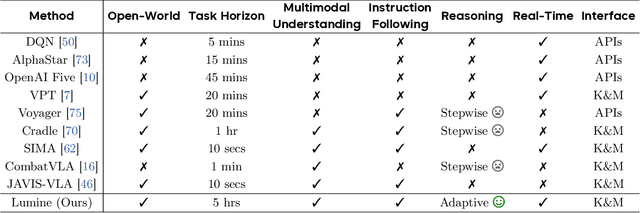


We introduce Lumine, the first open recipe for developing generalist agents capable of completing hours-long complex missions in real time within challenging 3D open-world environments. Lumine adopts a human-like interaction paradigm that unifies perception, reasoning, and action in an end-to-end manner, powered by a vision-language model. It processes raw pixels at 5 Hz to produce precise 30 Hz keyboard-mouse actions and adaptively invokes reasoning only when necessary. Trained in Genshin Impact, Lumine successfully completes the entire five-hour Mondstadt main storyline on par with human-level efficiency and follows natural language instructions to perform a broad spectrum of tasks in both 3D open-world exploration and 2D GUI manipulation across collection, combat, puzzle-solving, and NPC interaction. In addition to its in-domain performance, Lumine demonstrates strong zero-shot cross-game generalization. Without any fine-tuning, it accomplishes 100-minute missions in Wuthering Waves and the full five-hour first chapter of Honkai: Star Rail. These promising results highlight Lumine's effectiveness across distinct worlds and interaction dynamics, marking a concrete step toward generalist agents in open-ended environments.
EOTNet: Deep Memory Aided Bayesian Filter for Extended Object Tracking
May 24, 2025Extended object tracking methods based on random matrices, founded on Bayesian filters, have been able to achieve efficient recursive processes while jointly estimating the kinematic states and extension of the targets. Existing random matrix approaches typically assume that the evolution of state and extension follows a first-order Markov process, where the current estimate of the target depends solely on the previous moment. However, in real-world scenarios, this assumption fails because the evolution of states and extension is usually non-Markovian. In this paper, we introduce a novel extended object tracking method: a Bayesian recursive neural network assisted by deep memory. Initially, we propose an equivalent model under a non-Markovian assumption and derive the implementation of its Bayesian filtering framework. Thereafter, Gaussian approximation and moment matching are employed to derive the analytical solution for the proposed Bayesian filtering framework. Finally, based on the closed-form solution, we design an end-to-end trainable Bayesian recursive neural network for extended object tracking. Experiment results on simulated and real-world datasets show that the proposed methods outperforms traditional extended object tracking methods and state-of-the-art deep learning approaches.
High-Precision Transformer-Based Visual Servoing for Humanoid Robots in Aligning Tiny Objects
Mar 06, 2025



High-precision tiny object alignment remains a common and critical challenge for humanoid robots in real-world. To address this problem, this paper proposes a vision-based framework for precisely estimating and controlling the relative position between a handheld tool and a target object for humanoid robots, e.g., a screwdriver tip and a screw head slot. By fusing images from the head and torso cameras on a robot with its head joint angles, the proposed Transformer-based visual servoing method can correct the handheld tool's positional errors effectively, especially at a close distance. Experiments on M4-M8 screws demonstrate an average convergence error of 0.8-1.3 mm and a success rate of 93\%-100\%. Through comparative analysis, the results validate that this capability of high-precision tiny object alignment is enabled by the Distance Estimation Transformer architecture and the Multi-Perception-Head mechanism proposed in this paper.
Stereo-Talker: Audio-driven 3D Human Synthesis with Prior-Guided Mixture-of-Experts
Oct 31, 2024



This paper introduces Stereo-Talker, a novel one-shot audio-driven human video synthesis system that generates 3D talking videos with precise lip synchronization, expressive body gestures, temporally consistent photo-realistic quality, and continuous viewpoint control. The process follows a two-stage approach. In the first stage, the system maps audio input to high-fidelity motion sequences, encompassing upper-body gestures and facial expressions. To enrich motion diversity and authenticity, large language model (LLM) priors are integrated with text-aligned semantic audio features, leveraging LLMs' cross-modal generalization power to enhance motion quality. In the second stage, we improve diffusion-based video generation models by incorporating a prior-guided Mixture-of-Experts (MoE) mechanism: a view-guided MoE focuses on view-specific attributes, while a mask-guided MoE enhances region-based rendering stability. Additionally, a mask prediction module is devised to derive human masks from motion data, enhancing the stability and accuracy of masks and enabling mask guiding during inference. We also introduce a comprehensive human video dataset with 2,203 identities, covering diverse body gestures and detailed annotations, facilitating broad generalization. The code, data, and pre-trained models will be released for research purposes.
Boosting Gaze Object Prediction via Pixel-level Supervision from Vision Foundation Model
Aug 02, 2024Gaze object prediction (GOP) aims to predict the category and location of the object that a human is looking at. Previous methods utilized box-level supervision to identify the object that a person is looking at, but struggled with semantic ambiguity, ie, a single box may contain several items since objects are close together. The Vision foundation model (VFM) has improved in object segmentation using box prompts, which can reduce confusion by more precisely locating objects, offering advantages for fine-grained prediction of gaze objects. This paper presents a more challenging gaze object segmentation (GOS) task, which involves inferring the pixel-level mask corresponding to the object captured by human gaze behavior. In particular, we propose that the pixel-level supervision provided by VFM can be integrated into gaze object prediction to mitigate semantic ambiguity. This leads to our gaze object detection and segmentation framework that enables accurate pixel-level predictions. Different from previous methods that require additional head input or ignore head features, we propose to automatically obtain head features from scene features to ensure the model's inference efficiency and flexibility in the real world. Moreover, rather than directly fuse features to predict gaze heatmap as in existing methods, which may overlook spatial location and subtle details of the object, we develop a space-to-object gaze regression method to facilitate human-object gaze interaction. Specifically, it first constructs an initial human-object spatial connection, then refines this connection by interacting with semantically clear features in the segmentation branch, ultimately predicting a gaze heatmap for precise localization. Extensive experiments on GOO-Synth and GOO-Real datasets demonstrate the effectiveness of our method.
A UAV-Enabled Time-Sensitive Data Collection Scheme for Grassland Monitoring Edge Networks
Jul 30, 2024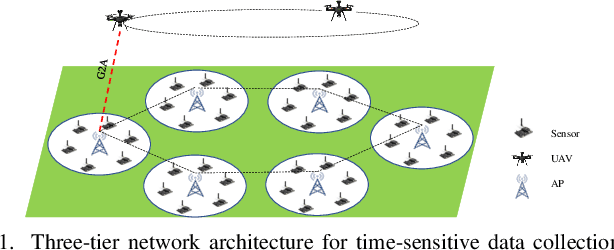
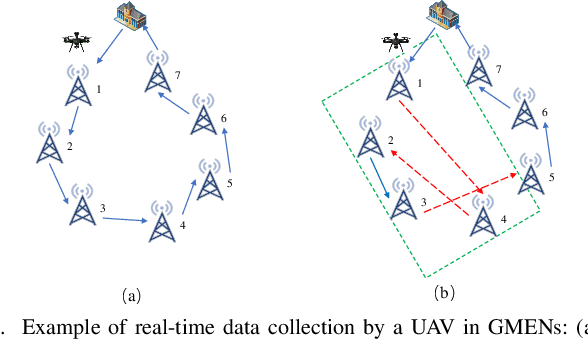
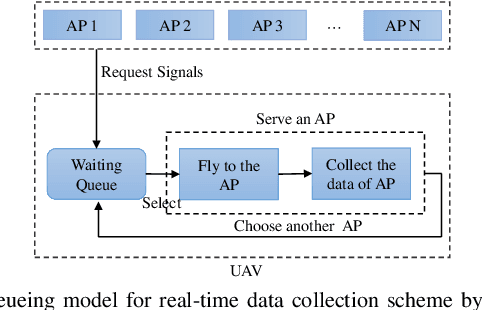
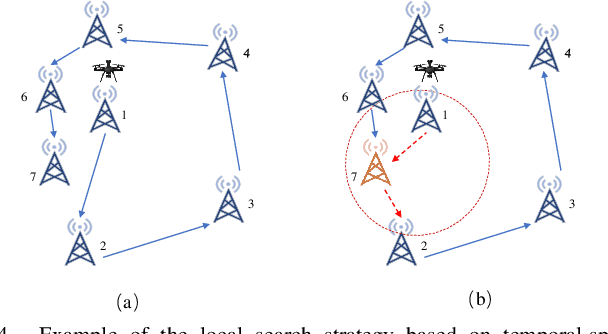
Grassland monitoring is essential for the sustainable development of grassland resources. Traditional Internet of Things (IoT) devices generate critical ecological data, making data loss unacceptable, but the harsh environment complicates data collection. Unmanned Aerial Vehicle (UAV) and mobile edge computing (MEC) offer efficient data collection solutions, enhancing performance on resource-limited mobile devices. In this context, this paper is the first to investigate a UAV-enabled time-sensitive data collection problem (TSDCMP) within grassland monitoring edge networks (GMENs). Unlike many existing data collection scenarios, this problem has three key challenges. First, the total amount of data collected depends significantly on the data collection duration and arrival time of UAV at each access point (AP). Second, the volume of data at different APs varies among regions due to differences in monitoring objects and vegetation coverage. Third, the service requests time and locations from APs are often not adjacent topologically. To address these issues, We formulate the TSDCMP for UAV-enabled GMENs as a mixed-integer programming model in a single trip. This model considers constraints such as the limited energy of UAV, the coupled routing and time scheduling, and the state of APs and UAV arrival time. Subsequently, we propose a novel cooperative heuristic algorithm based on temporal-spatial correlations (CHTSC) that integrates a modified dynamic programming (MDP) into an iterated local search to solve the TSDCMP for UAV-enabled GMENs. This approach fully takes into account the temporal and spatial relationships between consecutive service requests from APs. Systematic simulation studies demonstrate that the mixed-integer programming model effectively represents the TSDCMP within UAV-enabled GMENs.
Explainable Bayesian Recurrent Neural Smoother to Capture Global State Evolutionary Correlations
Jun 17, 2024Through integrating the evolutionary correlations across global states in the bidirectional recursion, an explainable Bayesian recurrent neural smoother (EBRNS) is proposed for offline data-assisted fixed-interval state smoothing. At first, the proposed model, containing global states in the evolutionary interval, is transformed into an equivalent model with bidirectional memory. This transformation incorporates crucial global state information with support for bi-directional recursive computation. For the transformed model, the joint state-memory-trend Bayesian filtering and smoothing frameworks are derived by introducing the bidirectional memory iteration mechanism and offline data into Bayesian estimation theory. The derived frameworks are implemented using the Gaussian approximation to ensure analytical properties and computational efficiency. Finally, the neural network modules within EBRNS and its two-stage training scheme are designed. Unlike most existing approaches that artificially combine deep learning and model-based estimation, the bidirectional recursion and internal gated structures of EBRNS are naturally derived from Bayesian estimation theory, explainably integrating prior model knowledge, online measurement, and offline data. Experiments on representative real-world datasets demonstrate that the high smoothing accuracy of EBRNS is accompanied by data efficiency and a lightweight parameter scale.
Performance Analysis of Integrated Sensing and Communication Networks with Blockage Effects
Mar 28, 2024



Communication-sensing integration represents an up-and-coming area of research, enabling wireless networks to simultaneously perform communication and sensing tasks. However, in urban cellular networks, the blockage of buildings results in a complex signal propagation environment, affecting the performance analysis of integrated sensing and communication (ISAC) networks. To overcome this obstacle, this paper constructs a comprehensive framework considering building blockage and employs a distance-correlated blockage model to analyze interference from line of sight (LoS), non-line of sight (NLoS), and target reflection cascading (TRC) links. Using stochastic geometric theory, expressions for signal-to-interference-plus-noise ratio (SINR) and coverage probability for communication and sensing in the presence of blockage are derived, allowing for a comprehensive comparison under the same parameters. The research findings indicate that blockage can positively impact coverage, especially in enhancing communication performance. The analysis also suggests that there exists an optimal base station (BS) density when blockage is of the same order of magnitude as the BS density, maximizing communication or sensing coverage probability.