 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotiMotion: Motion-Controlled Video Generation with Visual Reasoning
May 21, 2026Current motion-controlled image-to-video generation models rigidly follow user-provided trajectories that are often sparse, imprecise, and causally incomplete. Such reliance often yields unnatural or implausible outcomes, especially by missing secondary causal consequences. To address this, we introduce MotiMotion, a novel framework that reformulates motion control as a reasoning-then-generation problem. To encourage causally grounded and commonsense-consistent interactions, we leverage a training-free vision-language reasoner to refine image-space coordinates of primary trajectories and to hallucinate plausible secondary motions. To further improve motion naturalness, we propose a confidence-aware control scheme that modulates guidance strength, enabling the model to closely follow high-confidence plans while correcting artifacts under low-confidence inputs with its internal generative priors. To support systematic evaluation, we curate a new image-to-video benchmark, MotiBench, consisting of interaction-centric scenes where new events are triggered by motion. Both VLM-based evaluation and a human study on MotiBench demonstrate that MotiMotion produces videos with more plausible object behaviors and interaction, and is preferred over existing approaches.
TokenLight: Precise Lighting Control in Images using Attribute Tokens
Apr 16, 2026This paper presents a method for image relighting that enables precise and continuous control over multiple illumination attributes in a photograph. We formulate relighting as a conditional image generation task and introduce attribute tokens to encode distinct lighting factors such as intensity, color, ambient illumination, diffuse level, and 3D light positions. The model is trained on a large-scale synthetic dataset with ground-truth lighting annotations, supplemented by a small set of real captures to enhance realism and generalization. We validate our approach across a variety of relighting tasks, including controlling in-scene lighting fixtures and editing environment illumination using virtual light sources, on synthetic and real images. Our method achieves state-of-the-art quantitative and qualitative performance compared to prior work. Remarkably, without explicit inverse rendering supervision, the model exhibits an inherent understanding of how light interacts with scene geometry, occlusion, and materials, yielding convincing lighting effects even in traditionally challenging scenarios such as placing lights within objects or relighting transparent materials plausibly. Project page: vrroom.github.io/tokenlight/
Endless World: Real-Time 3D-Aware Long Video Generation
Dec 13, 2025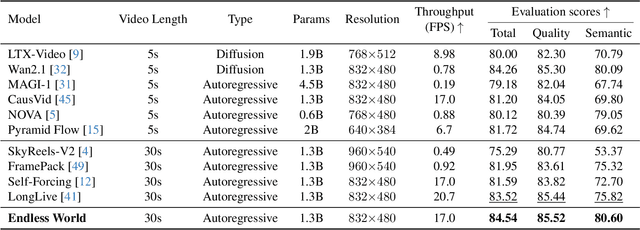
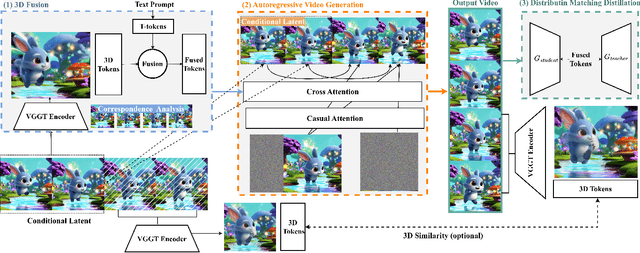
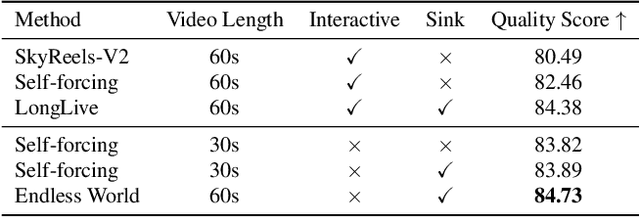

Producing long, coherent video sequences with stable 3D structure remains a major challenge, particularly in streaming scenarios. Motivated by this, we introduce Endless World, a real-time framework for infinite, 3D-consistent video generation.To support infinite video generation, we introduce a conditional autoregressive training strategy that aligns newly generated content with existing video frames. This design preserves long-range dependencies while remaining computationally efficient, enabling real-time inference on a single GPU without additional training overhead.Moreover, our Endless World integrates global 3D-aware attention to provide continuous geometric guidance across time. Our 3D injection mechanism enforces physical plausibility and geometric consistency throughout extended sequences, addressing key challenges in long-horizon and dynamic scene synthesis.Extensive experiments demonstrate that Endless World produces long, stable, and visually coherent videos, achieving competitive or superior performance to existing methods in both visual fidelity and spatial consistency. Our project has been available on https://bwgzk-keke.github.io/EndlessWorld/.
FreeViS: Training-free Video Stylization with Inconsistent References
Oct 02, 2025Video stylization plays a key role in content creation, but it remains a challenging problem. Na\"ively applying image stylization frame-by-frame hurts temporal consistency and reduces style richness. Alternatively, training a dedicated video stylization model typically requires paired video data and is computationally expensive. In this paper, we propose FreeViS, a training-free video stylization framework that generates stylized videos with rich style details and strong temporal coherence. Our method integrates multiple stylized references to a pretrained image-to-video (I2V) model, effectively mitigating the propagation errors observed in prior works, without introducing flickers and stutters. In addition, it leverages high-frequency compensation to constrain the content layout and motion, together with flow-based motion cues to preserve style textures in low-saliency regions. Through extensive evaluations, FreeViS delivers higher stylization fidelity and superior temporal consistency, outperforming recent baselines and achieving strong human preference. Our training-free pipeline offers a practical and economic solution for high-quality, temporally coherent video stylization. The code and videos can be accessed via https://xujiacong.github.io/FreeViS/
Think Before You Diffuse: LLMs-Guided Physics-Aware Video Generation
May 27, 2025Recent video diffusion models have demonstrated their great capability in generating visually-pleasing results, while synthesizing the correct physical effects in generated videos remains challenging. The complexity of real-world motions, interactions, and dynamics introduce great difficulties when learning physics from data. In this work, we propose DiffPhy, a generic framework that enables physically-correct and photo-realistic video generation by fine-tuning a pre-trained video diffusion model. Our method leverages large language models (LLMs) to explicitly reason a comprehensive physical context from the text prompt and use it to guide the generation. To incorporate physical context into the diffusion model, we leverage a Multimodal large language model (MLLM) as a supervisory signal and introduce a set of novel training objectives that jointly enforce physical correctness and semantic consistency with the input text. We also establish a high-quality physical video dataset containing diverse phyiscal actions and events to facilitate effective finetuning. Extensive experiments on public benchmarks demonstrate that DiffPhy is able to produce state-of-the-art results across diverse physics-related scenarios. Our project page is available at https://bwgzk-keke.github.io/DiffPhy/
Lux Post Facto: Learning Portrait Performance Relighting with Conditional Video Diffusion and a Hybrid Dataset
Mar 18, 2025Video portrait relighting remains challenging because the results need to be both photorealistic and temporally stable. This typically requires a strong model design that can capture complex facial reflections as well as intensive training on a high-quality paired video dataset, such as dynamic one-light-at-a-time (OLAT). In this work, we introduce Lux Post Facto, a novel portrait video relighting method that produces both photorealistic and temporally consistent lighting effects. From the model side, we design a new conditional video diffusion model built upon state-of-the-art pre-trained video diffusion model, alongside a new lighting injection mechanism to enable precise control. This way we leverage strong spatial and temporal generative capability to generate plausible solutions to the ill-posed relighting problem. Our technique uses a hybrid dataset consisting of static expression OLAT data and in-the-wild portrait performance videos to jointly learn relighting and temporal modeling. This avoids the need to acquire paired video data in different lighting conditions. Our extensive experiments show that our model produces state-of-the-art results both in terms of photorealism and temporal consistency.
Reference-based Controllable Scene Stylization with Gaussian Splatting
Jul 09, 2024



Referenced-based scene stylization that edits the appearance based on a content-aligned reference image is an emerging research area. Starting with a pretrained neural radiance field (NeRF), existing methods typically learn a novel appearance that matches the given style. Despite their effectiveness, they inherently suffer from time-consuming volume rendering, and thus are impractical for many real-time applications. In this work, we propose ReGS, which adapts 3D Gaussian Splatting (3DGS) for reference-based stylization to enable real-time stylized view synthesis. Editing the appearance of a pretrained 3DGS is challenging as it uses discrete Gaussians as 3D representation, which tightly bind appearance with geometry. Simply optimizing the appearance as prior methods do is often insufficient for modeling continuous textures in the given reference image. To address this challenge, we propose a novel texture-guided control mechanism that adaptively adjusts local responsible Gaussians to a new geometric arrangement, serving for desired texture details. The proposed process is guided by texture clues for effective appearance editing, and regularized by scene depth for preserving original geometric structure. With these novel designs, we show ReGs can produce state-of-the-art stylization results that respect the reference texture while embracing real-time rendering speed for free-view navigation.
Wild-GS: Real-Time Novel View Synthesis from Unconstrained Photo Collections
Jun 14, 2024
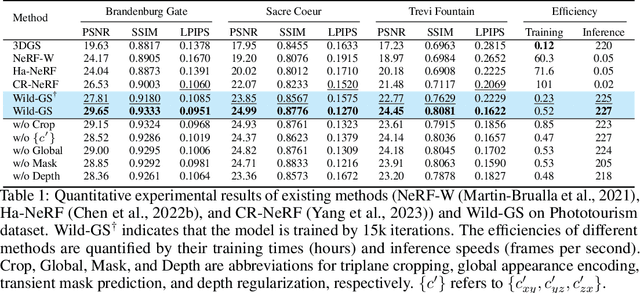
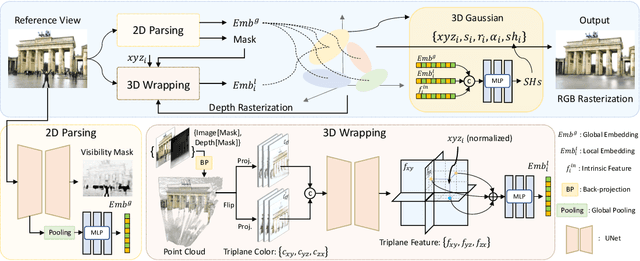
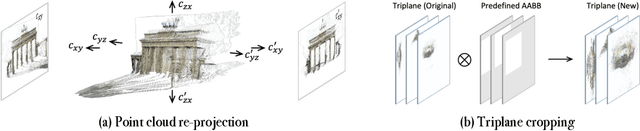
Photographs captured in unstructured tourist environments frequently exhibit variable appearances and transient occlusions, challenging accurate scene reconstruction and inducing artifacts in novel view synthesis. Although prior approaches have integrated the Neural Radiance Field (NeRF) with additional learnable modules to handle the dynamic appearances and eliminate transient objects, their extensive training demands and slow rendering speeds limit practical deployments. Recently, 3D Gaussian Splatting (3DGS) has emerged as a promising alternative to NeRF, offering superior training and inference efficiency along with better rendering quality. This paper presents Wild-GS, an innovative adaptation of 3DGS optimized for unconstrained photo collections while preserving its efficiency benefits. Wild-GS determines the appearance of each 3D Gaussian by their inherent material attributes, global illumination and camera properties per image, and point-level local variance of reflectance. Unlike previous methods that model reference features in image space, Wild-GS explicitly aligns the pixel appearance features to the corresponding local Gaussians by sampling the triplane extracted from the reference image. This novel design effectively transfers the high-frequency detailed appearance of the reference view to 3D space and significantly expedites the training process. Furthermore, 2D visibility maps and depth regularization are leveraged to mitigate the transient effects and constrain the geometry, respectively. Extensive experiments demonstrate that Wild-GS achieves state-of-the-art rendering performance and the highest efficiency in both training and inference among all the existing techniques.
Holo-Relighting: Controllable Volumetric Portrait Relighting from a Single Image
Mar 14, 2024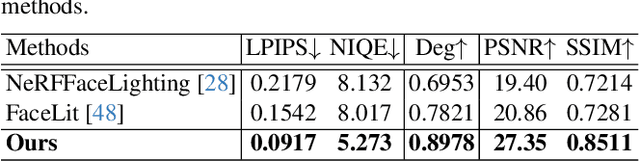
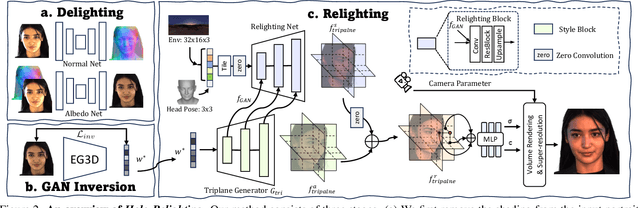
At the core of portrait photography is the search for ideal lighting and viewpoint. The process often requires advanced knowledge in photography and an elaborate studio setup. In this work, we propose Holo-Relighting, a volumetric relighting method that is capable of synthesizing novel viewpoints, and novel lighting from a single image. Holo-Relighting leverages the pretrained 3D GAN (EG3D) to reconstruct geometry and appearance from an input portrait as a set of 3D-aware features. We design a relighting module conditioned on a given lighting to process these features, and predict a relit 3D representation in the form of a tri-plane, which can render to an arbitrary viewpoint through volume rendering. Besides viewpoint and lighting control, Holo-Relighting also takes the head pose as a condition to enable head-pose-dependent lighting effects. With these novel designs, Holo-Relighting can generate complex non-Lambertian lighting effects (e.g., specular highlights and cast shadows) without using any explicit physical lighting priors. We train Holo-Relighting with data captured with a light stage, and propose two data-rendering techniques to improve the data quality for training the volumetric relighting system. Through quantitative and qualitative experiments, we demonstrate Holo-Relighting can achieve state-of-the-arts relighting quality with better photorealism, 3D consistency and controllability.
LightPainter: Interactive Portrait Relighting with Freehand Scribble
Mar 22, 2023Recent portrait relighting methods have achieved realistic results of portrait lighting effects given a desired lighting representation such as an environment map. However, these methods are not intuitive for user interaction and lack precise lighting control. We introduce LightPainter, a scribble-based relighting system that allows users to interactively manipulate portrait lighting effect with ease. This is achieved by two conditional neural networks, a delighting module that recovers geometry and albedo optionally conditioned on skin tone, and a scribble-based module for relighting. To train the relighting module, we propose a novel scribble simulation procedure to mimic real user scribbles, which allows our pipeline to be trained without any human annotations. We demonstrate high-quality and flexible portrait lighting editing capability with both quantitative and qualitative experiments. User study comparisons with commercial lighting editing tools also demonstrate consistent user preference for our method.