 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDUM: A Scalable Deep Unrolled Model for Universal MRI Reconstruction
Dec 19, 2025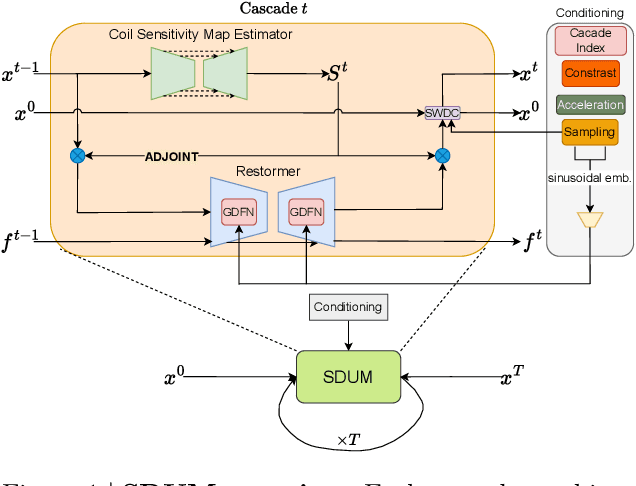

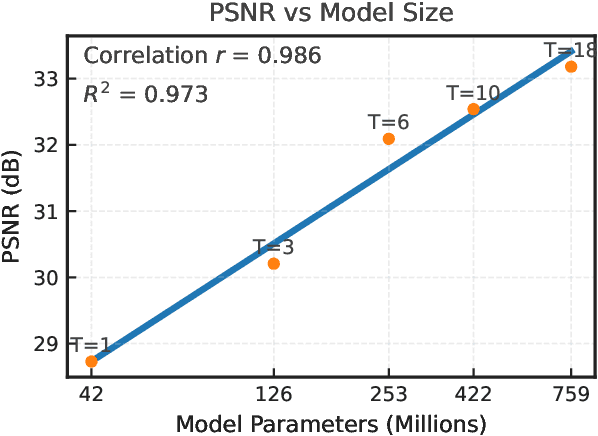
Clinical MRI encompasses diverse imaging protocols--spanning anatomical targets (cardiac, brain, knee), contrasts (T1, T2, mapping), sampling patterns (Cartesian, radial, spiral, kt-space), and acceleration factors--yet current deep learning reconstructions are typically protocol-specific, hindering generalization and deployment. We introduce Scalable Deep Unrolled Model (SDUM), a universal framework combining a Restormer-based reconstructor, a learned coil sensitivity map estimator (CSME), sampling-aware weighted data consistency (SWDC), universal conditioning (UC) on cascade index and protocol metadata, and progressive cascade expansion training. SDUM exhibits foundation-model-like scaling behavior: reconstruction quality follows PSNR ${\sim}$ log(parameters) with correlation $r{=}0.986$ ($R^2{=}0.973$) up to 18 cascades, demonstrating predictable performance gains with model depth. A single SDUM trained on heterogeneous data achieves state-of-the-art results across all four CMRxRecon2025 challenge tracks--multi-center, multi-disease, 5T, and pediatric--without task-specific fine-tuning, surpassing specialized baselines by up to ${+}1.0$~dB. On CMRxRecon2024, SDUM outperforms the winning method PromptMR+ by ${+}0.55$~dB; on fastMRI brain, it exceeds PC-RNN by ${+}1.8$~dB. Ablations validate each component: SWDC ${+}0.43$~dB over standard DC, per-cascade CSME ${+}0.51$~dB, UC ${+}0.38$~dB. These results establish SDUM as a practical path toward universal, scalable MRI reconstruction.
Relative-Based Scaling Law for Neural Language Models
Oct 23, 2025Scaling laws aim to accurately predict model performance across different scales. Existing scaling-law studies almost exclusively rely on cross-entropy as the evaluation metric. However, cross-entropy provides only a partial view of performance: it measures the absolute probability assigned to the correct token, but ignores the relative ordering between correct and incorrect tokens. Yet, relative ordering is crucial for language models, such as in greedy-sampling scenario. To address this limitation, we investigate scaling from the perspective of relative ordering. We first propose the Relative-Based Probability (RBP) metric, which quantifies the probability that the correct token is ranked among the top predictions. Building on this metric, we establish the Relative-Based Scaling Law, which characterizes how RBP improves with increasing model size. Through extensive experiments on four datasets and four model families spanning five orders of magnitude, we demonstrate the robustness and accuracy of this law. Finally, we illustrate the broad application of this law with two examples, namely providing a deeper explanation of emergence phenomena and facilitating finding fundamental theories of scaling laws. In summary, the Relative-Based Scaling Law complements the cross-entropy perspective and contributes to a more complete understanding of scaling large language models. Thus, it offers valuable insights for both practical development and theoretical exploration.
MoViT: Memorizing Vision Transformers for Medical Image Analysis
Apr 04, 2023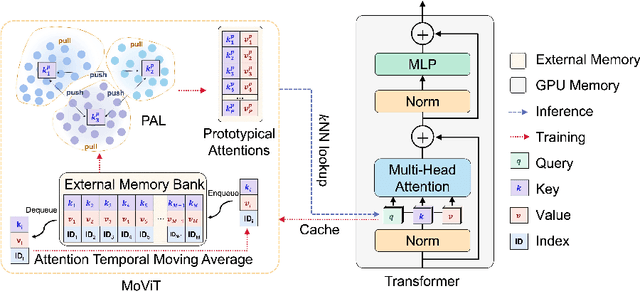
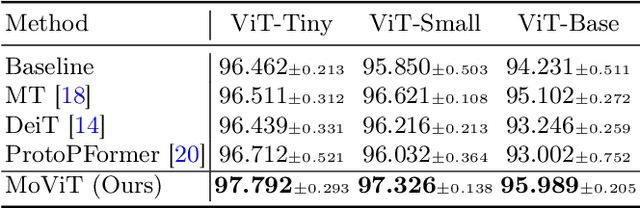
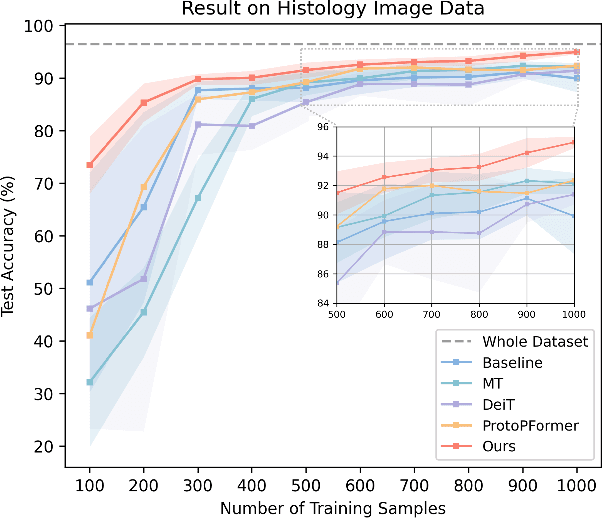
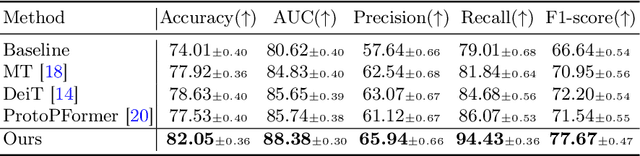
The synergy of long-range dependencies from transformers and local representations of image content from convolutional neural networks (CNNs) has led to advanced architectures and increased performance for various medical image analysis tasks due to their complementary benefits. However, compared with CNNs, transformers require considerably more training data, due to a larger number of parameters and an absence of inductive bias. The need for increasingly large datasets continues to be problematic, particularly in the context of medical imaging, where both annotation efforts and data protection result in limited data availability. In this work, inspired by the human decision-making process of correlating new ``evidence'' with previously memorized ``experience'', we propose a Memorizing Vision Transformer (MoViT) to alleviate the need for large-scale datasets to successfully train and deploy transformer-based architectures. MoViT leverages an external memory structure to cache history attention snapshots during the training stage. To prevent overfitting, we incorporate an innovative memory update scheme, attention temporal moving average, to update the stored external memories with the historical moving average. For inference speedup, we design a prototypical attention learning method to distill the external memory into smaller representative subsets. We evaluate our method on a public histology image dataset and an in-house MRI dataset, demonstrating that MoViT applied to varied medical image analysis tasks, can outperform vanilla transformer models across varied data regimes, especially in cases where only a small amount of annotated data is available. More importantly, MoViT can reach a competitive performance of ViT with only 3.0% of the training data.
ReconFormer: Accelerated MRI Reconstruction Using Recurrent Transformer
Jan 28, 2022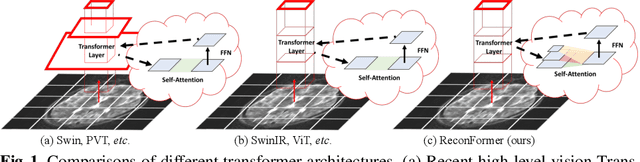
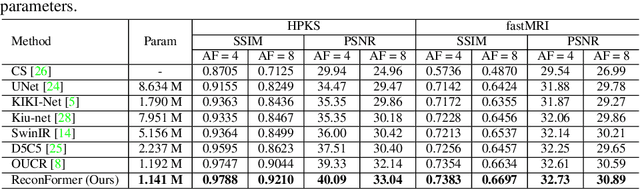
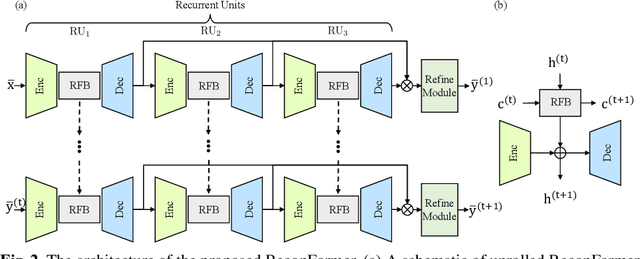
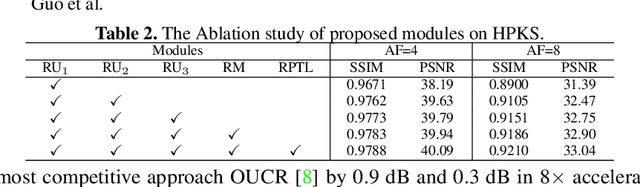
Accelerating magnetic resonance image (MRI) reconstruction process is a challenging ill-posed inverse problem due to the excessive under-sampling operation in k-space. In this paper, we propose a recurrent transformer model, namely ReconFormer, for MRI reconstruction which can iteratively reconstruct high fertility magnetic resonance images from highly under-sampled k-space data. In particular, the proposed architecture is built upon Recurrent Pyramid Transformer Layers (RPTL), which jointly exploits intrinsic multi-scale information at every architecture unit as well as the dependencies of the deep feature correlation through recurrent states. Moreover, the proposed ReconFormer is lightweight since it employs the recurrent structure for its parameter efficiency. We validate the effectiveness of ReconFormer on multiple datasets with different magnetic resonance sequences and show that it achieves significant improvements over the state-of-the-art methods with better parameter efficiency. Implementation code will be available in https://github.com/guopengf/ReconFormer.
Over-and-Under Complete Convolutional RNN for MRI Reconstruction
Jun 25, 2021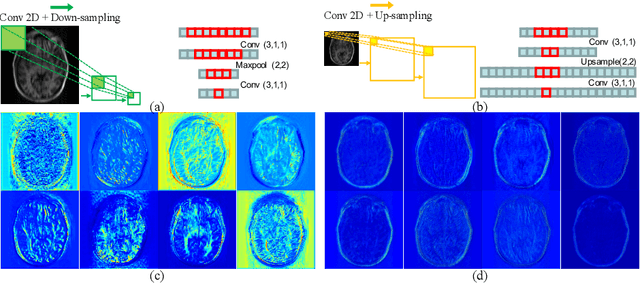
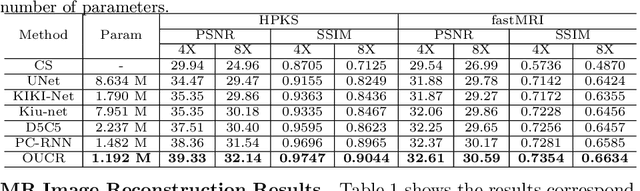
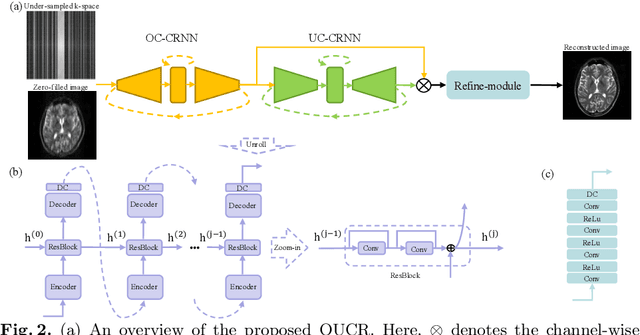
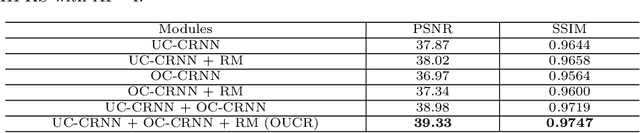
Reconstructing magnetic resonance (MR) images from undersampled data is a challenging problem due to various artifacts introduced by the under-sampling operation. Recent deep learning-based methods for MR image reconstruction usually leverage a generic auto-encoder architecture which captures low-level features at the initial layers and high-level features at the deeper layers. Such networks focus much on global features which may not be optimal to reconstruct the fully-sampled image. In this paper, we propose an Over-and-Under Complete Convolutional Recurrent Neural Network (OUCR), which consists of an overcomplete and an undercomplete Convolutional Recurrent Neural Network(CRNN). The overcomplete branch gives special attention in learning local structures by restraining the receptive field of the network. Combining it with the undercomplete branch leads to a network which focuses more on low-level features without losing out on the global structures. Extensive experiments on two datasets demonstrate that the proposed method achieves significant improvements over the compressed sensing and popular deep learning-based methods with less number of trainable parameters.
Multi-institutional Collaborations for Improving Deep Learning-based Magnetic Resonance Image Reconstruction Using Federated Learning
Mar 10, 2021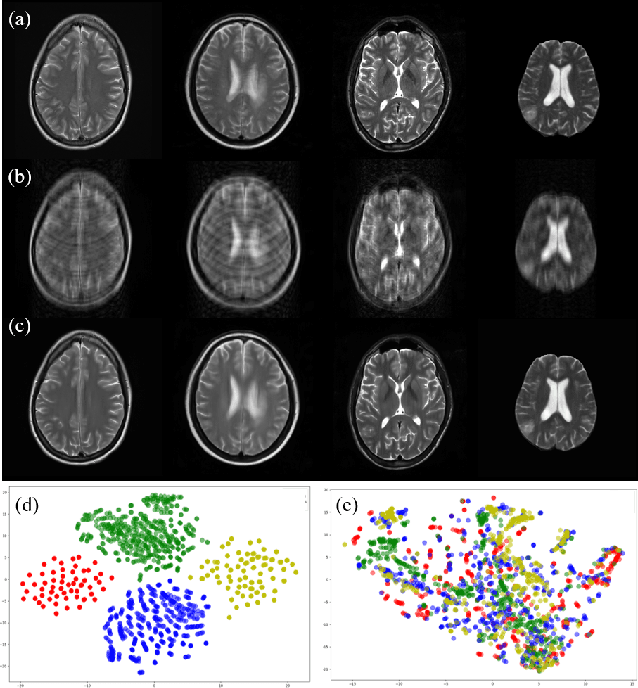
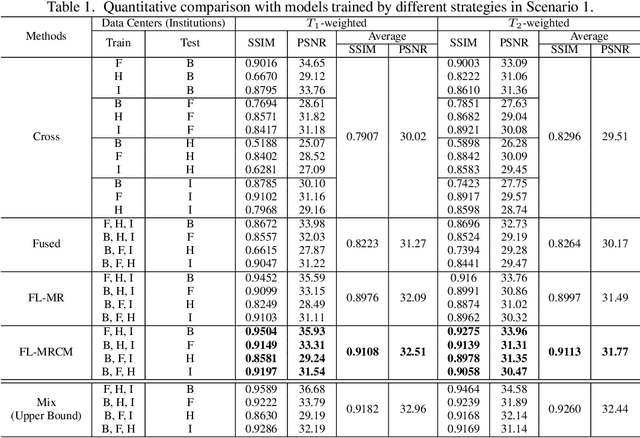
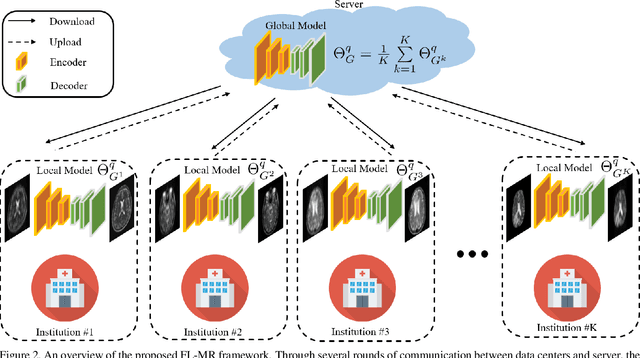
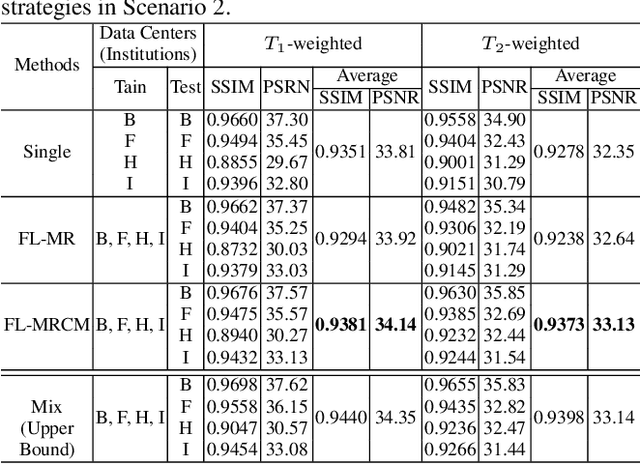
Fast and accurate reconstruction of magnetic resonance (MR) images from under-sampled data is important in many clinical applications. In recent years, deep learning-based methods have been shown to produce superior performance on MR image reconstruction. However, these methods require large amounts of data which is difficult to collect and share due to the high cost of acquisition and medical data privacy regulations. In order to overcome this challenge, we propose a federated learning (FL) based solution in which we take advantage of the MR data available at different institutions while preserving patients' privacy. However, the generalizability of models trained with the FL setting can still be suboptimal due to domain shift, which results from the data collected at multiple institutions with different sensors, disease types, and acquisition protocols, etc. With the motivation of circumventing this challenge, we propose a cross-site modeling for MR image reconstruction in which the learned intermediate latent features among different source sites are aligned with the distribution of the latent features at the target site. Extensive experiments are conducted to provide various insights about FL for MR image reconstruction. Experimental results demonstrate that the proposed framework is a promising direction to utilize multi-institutional data without compromising patients' privacy for achieving improved MR image reconstruction. Our code will be available at https://github.com/guopengf/FLMRCM.
Confidence-guided Lesion Mask-based Simultaneous Synthesis of Anatomic and Molecular MR Images in Patients with Post-treatment Malignant Gliomas
Aug 06, 2020Data-driven automatic approaches have demonstrated their great potential in resolving various clinical diagnostic dilemmas in neuro-oncology, especially with the help of standard anatomic and advanced molecular MR images. However, data quantity and quality remain a key determinant of, and a significant limit on, the potential of such applications. In our previous work, we explored synthesis of anatomic and molecular MR image network (SAMR) in patients with post-treatment malignant glioms. Now, we extend it and propose Confidence Guided SAMR (CG-SAMR) that synthesizes data from lesion information to multi-modal anatomic sequences, including T1-weighted (T1w), gadolinium enhanced T1w (Gd-T1w), T2-weighted (T2w), and fluid-attenuated inversion recovery (FLAIR), and the molecular amide proton transfer-weighted (APTw) sequence. We introduce a module which guides the synthesis based on confidence measure about the intermediate results. Furthermore, we extend the proposed architecture for unsupervised synthesis so that unpaired data can be used for training the network. Extensive experiments on real clinical data demonstrate that the proposed model can perform better than the state-of-theart synthesis methods.
Lesion Mask-based Simultaneous Synthesis of Anatomic and MolecularMR Images using a GAN
Jul 05, 2020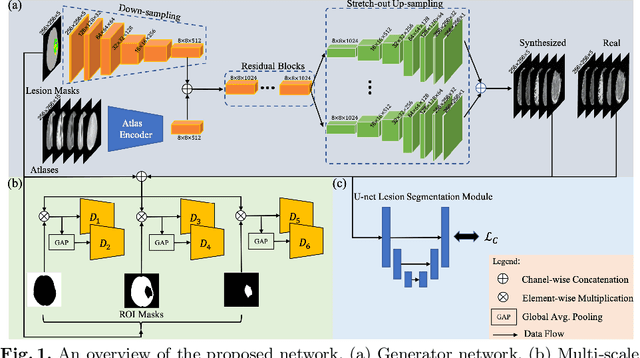

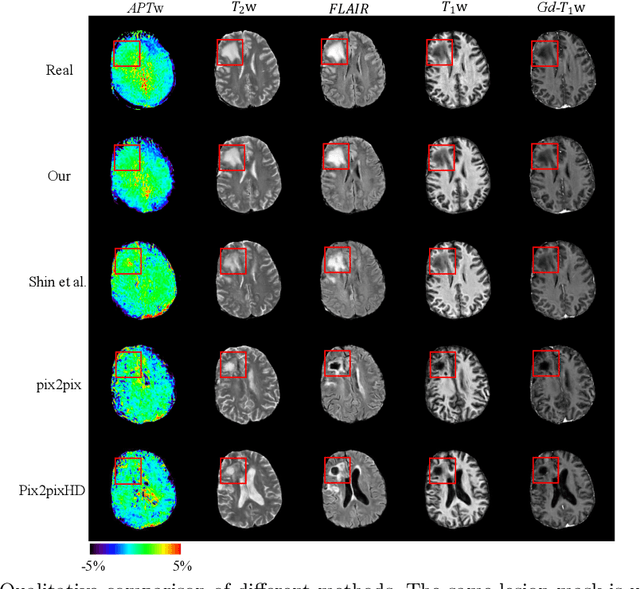
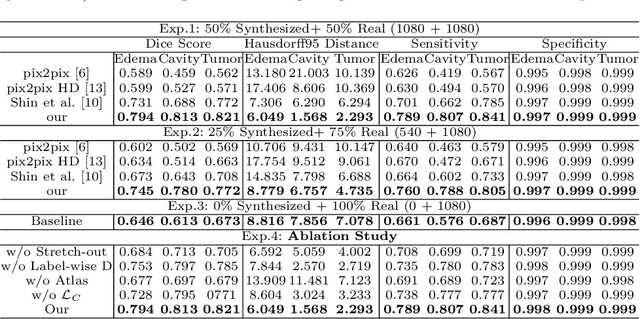
Data-driven automatic approaches have demonstrated their great potential in resolving various clinical diagnostic dilemmas for patients with malignant gliomas in neuro-oncology with the help of conventional and advanced molecular MR images. However, the lack of sufficient annotated MRI data has vastly impeded the development of such automatic methods. Conventional data augmentation approaches, including flipping, scaling, rotation, and distortion are not capable of generating data with diverse image content. In this paper, we propose a generative adversarial network (GAN), which can simultaneously synthesize data from arbitrary manipulated lesion information on multiple anatomic and molecular MRI sequences, including T1-weighted (T1w), gadolinium enhanced T1w (Gd-T1w), T2-weighted (T2w), fluid-attenuated inversion recovery (FLAIR), and amide proton transfer-weighted (APTw). The proposed framework consists of a stretch-out up-sampling module, a brain atlas encoder, a segmentation consistency module, and multi-scale labelwise discriminators. Extensive experiments on real clinical data demonstrate that the proposed model can perform significantly better than the state-of-the-art synthesis methods.