 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly and Prediagnostic Detection of Pancreatic Cancer from Computed Tomography
Jan 29, 2026Pancreatic ductal adenocarcinoma (PDAC), one of the deadliest solid malignancies, is often detected at a late and inoperable stage. Retrospective reviews of prediagnostic CT scans, when conducted by expert radiologists aware that the patient later developed PDAC, frequently reveal lesions that were previously overlooked. To help detecting these lesions earlier, we developed an automated system named ePAI (early Pancreatic cancer detection with Artificial Intelligence). It was trained on data from 1,598 patients from a single medical center. In the internal test involving 1,009 patients, ePAI achieved an area under the receiver operating characteristic curve (AUC) of 0.939-0.999, a sensitivity of 95.3%, and a specificity of 98.7% for detecting small PDAC less than 2 cm in diameter, precisely localizing PDAC as small as 2 mm. In an external test involving 7,158 patients across 6 centers, ePAI achieved an AUC of 0.918-0.945, a sensitivity of 91.5%, and a specificity of 88.0%, precisely localizing PDAC as small as 5 mm. Importantly, ePAI detected PDACs on prediagnostic CT scans obtained 3 to 36 months before clinical diagnosis that had originally been overlooked by radiologists. It successfully detected and localized PDACs in 75 of 159 patients, with a median lead time of 347 days before clinical diagnosis. Our multi-reader study showed that ePAI significantly outperformed 30 board-certified radiologists by 50.3% (P < 0.05) in sensitivity while maintaining a comparable specificity of 95.4% in detecting PDACs early and prediagnostic. These findings suggest its potential of ePAI as an assistive tool to improve early detection of pancreatic cancer.
SDUM: A Scalable Deep Unrolled Model for Universal MRI Reconstruction
Dec 19, 2025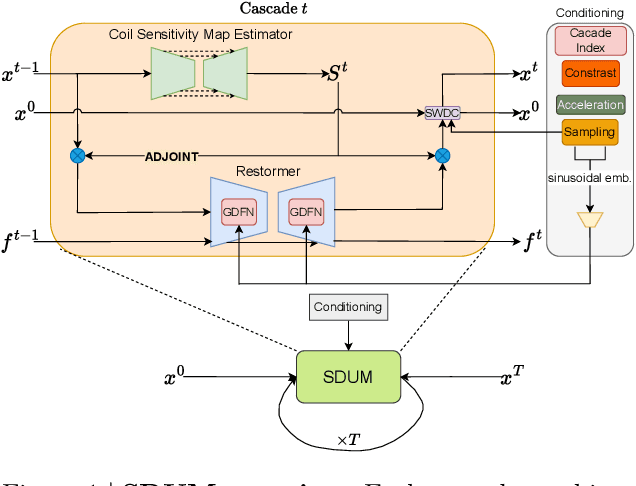
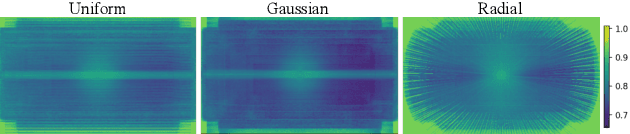

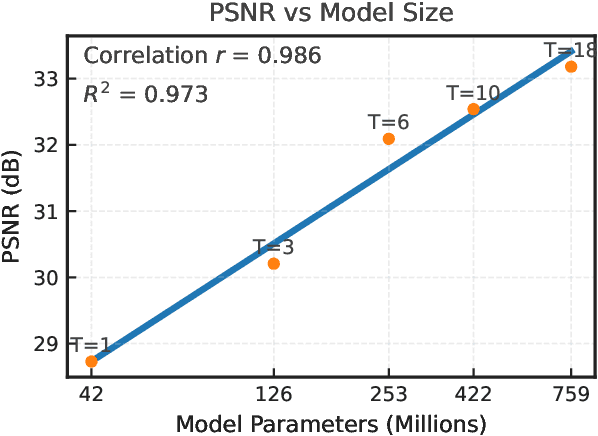
Clinical MRI encompasses diverse imaging protocols--spanning anatomical targets (cardiac, brain, knee), contrasts (T1, T2, mapping), sampling patterns (Cartesian, radial, spiral, kt-space), and acceleration factors--yet current deep learning reconstructions are typically protocol-specific, hindering generalization and deployment. We introduce Scalable Deep Unrolled Model (SDUM), a universal framework combining a Restormer-based reconstructor, a learned coil sensitivity map estimator (CSME), sampling-aware weighted data consistency (SWDC), universal conditioning (UC) on cascade index and protocol metadata, and progressive cascade expansion training. SDUM exhibits foundation-model-like scaling behavior: reconstruction quality follows PSNR ${\sim}$ log(parameters) with correlation $r{=}0.986$ ($R^2{=}0.973$) up to 18 cascades, demonstrating predictable performance gains with model depth. A single SDUM trained on heterogeneous data achieves state-of-the-art results across all four CMRxRecon2025 challenge tracks--multi-center, multi-disease, 5T, and pediatric--without task-specific fine-tuning, surpassing specialized baselines by up to ${+}1.0$~dB. On CMRxRecon2024, SDUM outperforms the winning method PromptMR+ by ${+}0.55$~dB; on fastMRI brain, it exceeds PC-RNN by ${+}1.8$~dB. Ablations validate each component: SWDC ${+}0.43$~dB over standard DC, per-cascade CSME ${+}0.51$~dB, UC ${+}0.38$~dB. These results establish SDUM as a practical path toward universal, scalable MRI reconstruction.
Generative AI for Film Creation: A Survey of Recent Advances
Apr 11, 2025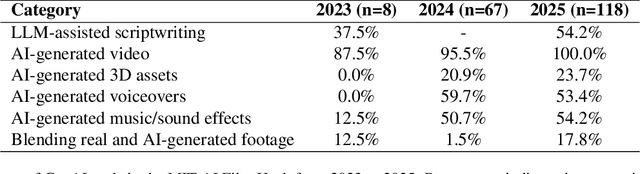


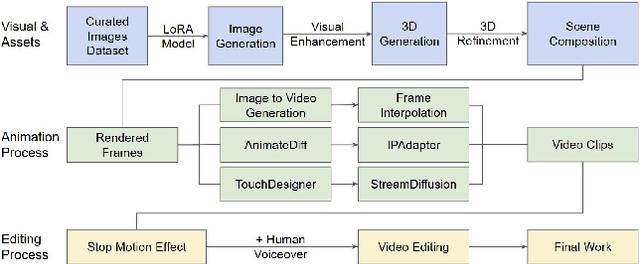
Generative AI (GenAI) is transforming filmmaking, equipping artists with tools like text-to-image and image-to-video diffusion, neural radiance fields, avatar generation, and 3D synthesis. This paper examines the adoption of these technologies in filmmaking, analyzing workflows from recent AI-driven films to understand how GenAI contributes to character creation, aesthetic styling, and narration. We explore key strategies for maintaining character consistency, achieving stylistic coherence, and ensuring motion continuity. Additionally, we highlight emerging trends such as the growing use of 3D generation and the integration of real footage with AI-generated elements. Beyond technical advancements, we examine how GenAI is enabling new artistic expressions, from generating hard-to-shoot footage to dreamlike diffusion-based morphing effects, abstract visuals, and unworldly objects. We also gather artists' feedback on challenges and desired improvements, including consistency, controllability, fine-grained editing, and motion refinement. Our study provides insights into the evolving intersection of AI and filmmaking, offering a roadmap for researchers and artists navigating this rapidly expanding field.
GATE: Graph-based Adaptive Tool Evolution Across Diverse Tasks
Feb 20, 2025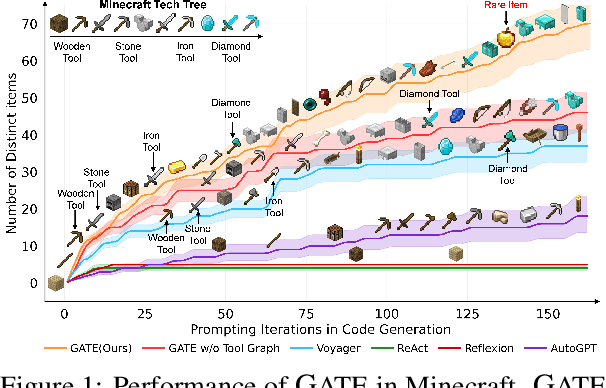
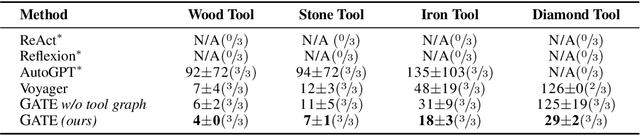
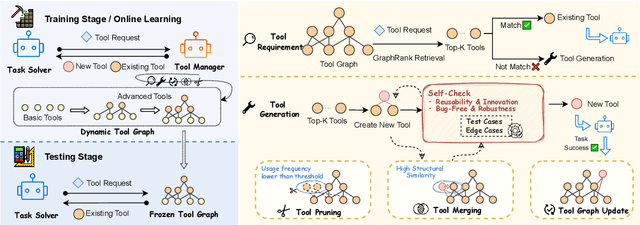
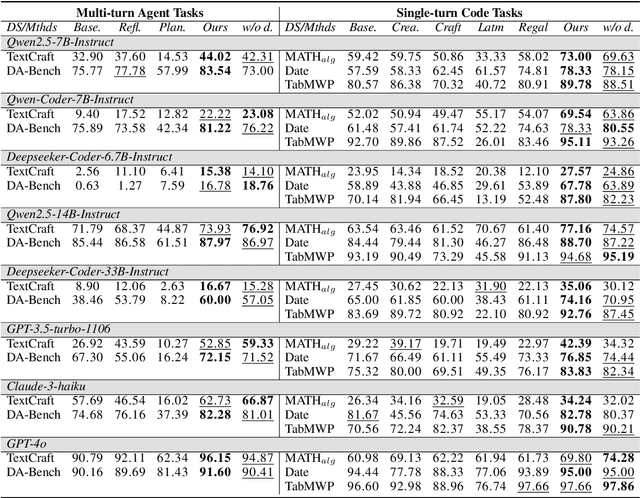
Large Language Models (LLMs) have shown great promise in tool-making, yet existing frameworks often struggle to efficiently construct reliable toolsets and are limited to single-task settings. To address these challenges, we propose GATE (Graph-based Adaptive Tool Evolution), an adaptive framework that dynamically constructs and evolves a hierarchical graph of reusable tools across multiple scenarios. We evaluate GATE on open-ended tasks (Minecraft), agent-based tasks (TextCraft, DABench), and code generation tasks (MATH, Date, TabMWP). Our results show that GATE achieves up to 4.3x faster milestone completion in Minecraft compared to the previous SOTA, and provides an average improvement of 9.23% over existing tool-making methods in code generation tasks and 10.03% in agent tasks. GATE demonstrates the power of adaptive evolution, balancing tool quantity, complexity, and functionality while maintaining high efficiency. Code and data are available at \url{https://github.com/ayanami2003/GATE}.
Few-shot Named Entity Recognition via Superposition Concept Discrimination
Mar 25, 2024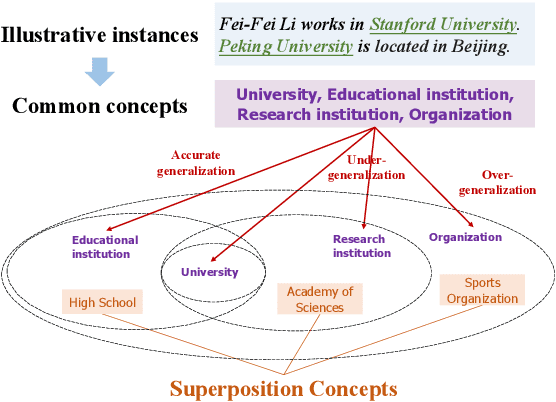
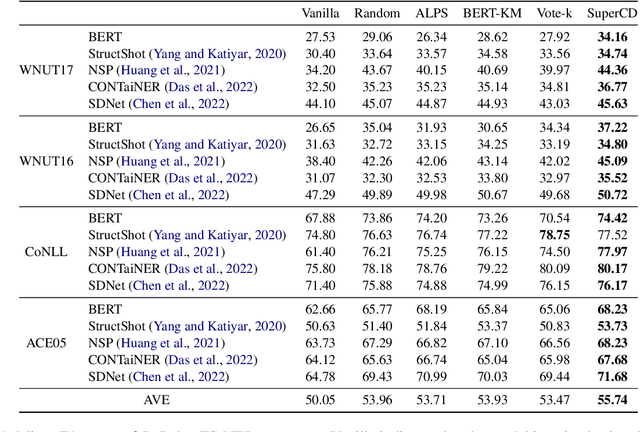
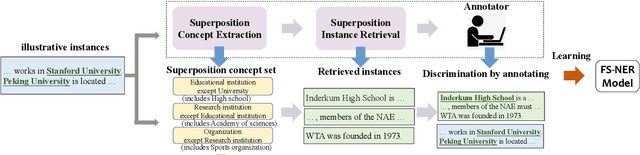
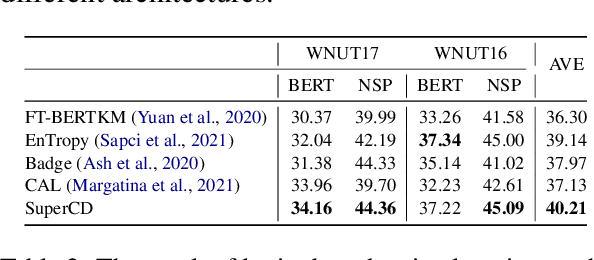
Few-shot NER aims to identify entities of target types with only limited number of illustrative instances. Unfortunately, few-shot NER is severely challenged by the intrinsic precise generalization problem, i.e., it is hard to accurately determine the desired target type due to the ambiguity stemming from information deficiency. In this paper, we propose Superposition Concept Discriminator (SuperCD), which resolves the above challenge via an active learning paradigm. Specifically, a concept extractor is first introduced to identify superposition concepts from illustrative instances, with each concept corresponding to a possible generalization boundary. Then a superposition instance retriever is applied to retrieve corresponding instances of these superposition concepts from large-scale text corpus. Finally, annotators are asked to annotate the retrieved instances and these annotated instances together with original illustrative instances are used to learn FS-NER models. To this end, we learn a universal concept extractor and superposition instance retriever using a large-scale openly available knowledge bases. Experiments show that SuperCD can effectively identify superposition concepts from illustrative instances, retrieve superposition instances from large-scale corpus, and significantly improve the few-shot NER performance with minimal additional efforts.
MoViT: Memorizing Vision Transformers for Medical Image Analysis
Apr 04, 2023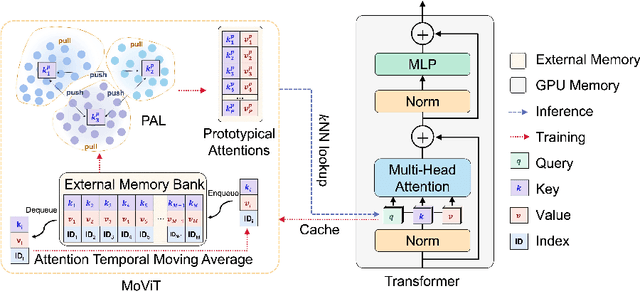
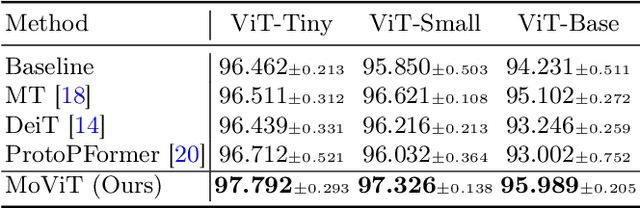
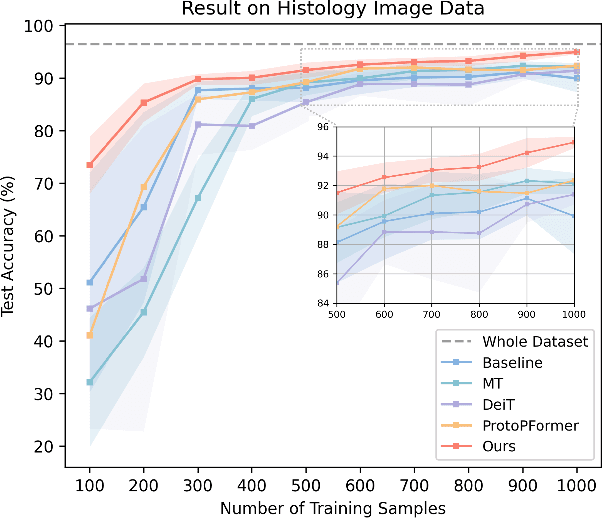
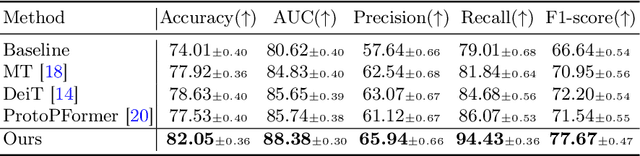
The synergy of long-range dependencies from transformers and local representations of image content from convolutional neural networks (CNNs) has led to advanced architectures and increased performance for various medical image analysis tasks due to their complementary benefits. However, compared with CNNs, transformers require considerably more training data, due to a larger number of parameters and an absence of inductive bias. The need for increasingly large datasets continues to be problematic, particularly in the context of medical imaging, where both annotation efforts and data protection result in limited data availability. In this work, inspired by the human decision-making process of correlating new ``evidence'' with previously memorized ``experience'', we propose a Memorizing Vision Transformer (MoViT) to alleviate the need for large-scale datasets to successfully train and deploy transformer-based architectures. MoViT leverages an external memory structure to cache history attention snapshots during the training stage. To prevent overfitting, we incorporate an innovative memory update scheme, attention temporal moving average, to update the stored external memories with the historical moving average. For inference speedup, we design a prototypical attention learning method to distill the external memory into smaller representative subsets. We evaluate our method on a public histology image dataset and an in-house MRI dataset, demonstrating that MoViT applied to varied medical image analysis tasks, can outperform vanilla transformer models across varied data regimes, especially in cases where only a small amount of annotated data is available. More importantly, MoViT can reach a competitive performance of ViT with only 3.0% of the training data.
Optimal Hyperparameters and Structure Setting of Multi-Objective Robust CNN Systems via Generalized Taguchi Method and Objective Vector Norm
Feb 10, 2022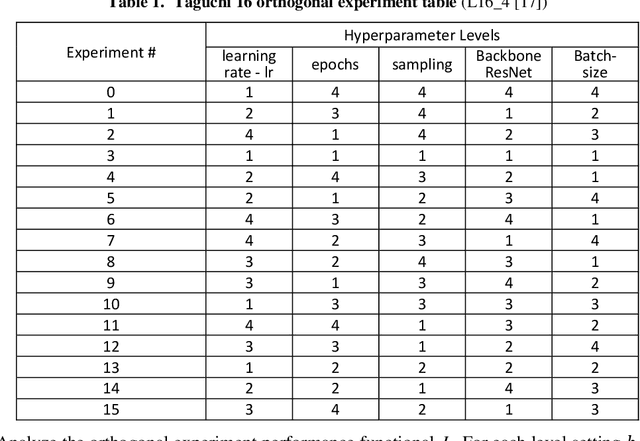
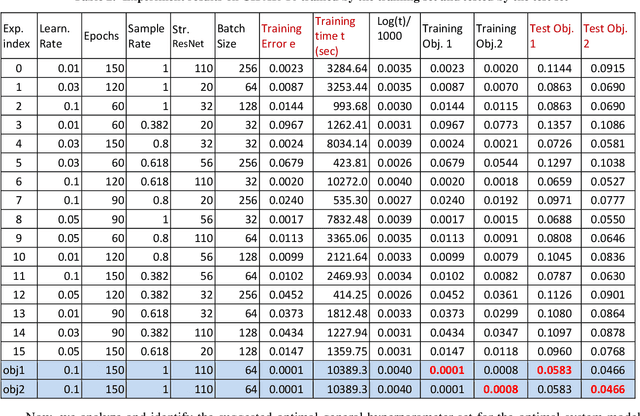
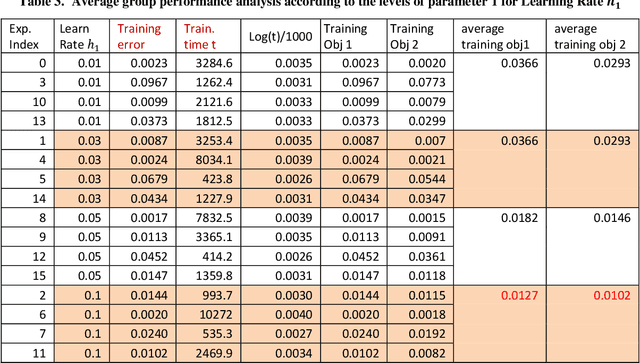
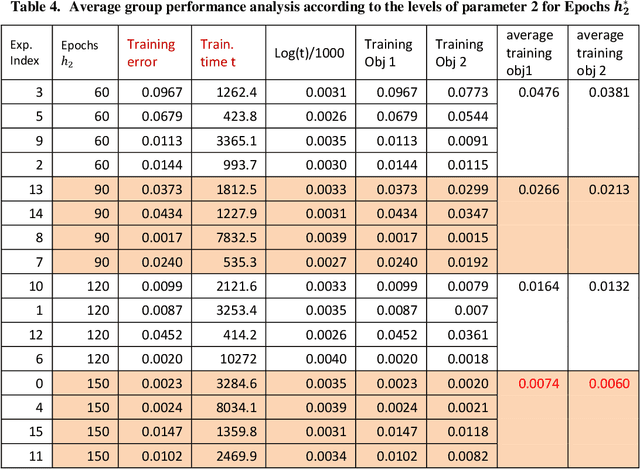
Recently, Machine Learning (ML), Artificial Intelligence (AI), and Convolutional Neural Network (CNN) have made huge progress with broad applications, where their systems have deep learning structures and a large number of hyperparameters that determine the quality and performance of the CNNs and AI systems. These systems may have multi-objective ML and AI performance needs. There is a key requirement to find the optimal hyperparameters and structures for multi-objective robust optimal CNN systems. This paper proposes a generalized Taguchi approach to effectively determine the optimal hyperparameters and structure for the multi-objective robust optimal CNN systems via their objective performance vector norm. The proposed approach and methods are applied to a CNN classification system with the original ResNet for CIFAR-10 dataset as a demonstration and validation, which shows the proposed methods are highly effective to achieve an optimal accuracy rate of the original ResNet on CIFAR-10.
ReconFormer: Accelerated MRI Reconstruction Using Recurrent Transformer
Jan 28, 2022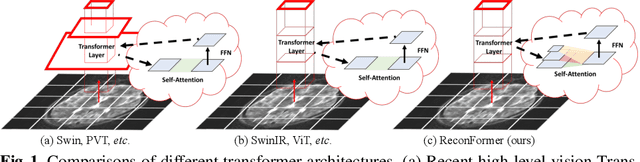
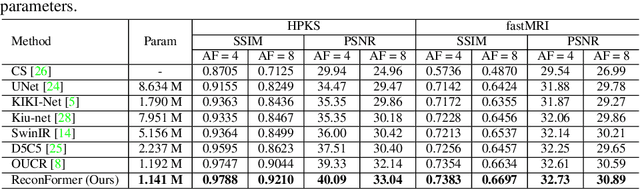
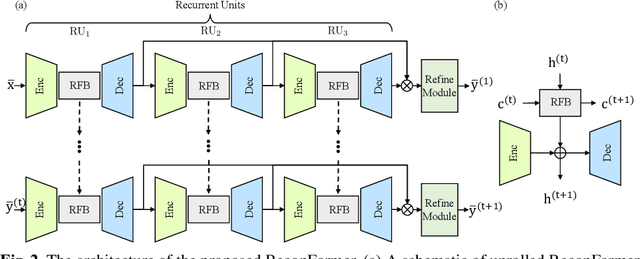
Accelerating magnetic resonance image (MRI) reconstruction process is a challenging ill-posed inverse problem due to the excessive under-sampling operation in k-space. In this paper, we propose a recurrent transformer model, namely ReconFormer, for MRI reconstruction which can iteratively reconstruct high fertility magnetic resonance images from highly under-sampled k-space data. In particular, the proposed architecture is built upon Recurrent Pyramid Transformer Layers (RPTL), which jointly exploits intrinsic multi-scale information at every architecture unit as well as the dependencies of the deep feature correlation through recurrent states. Moreover, the proposed ReconFormer is lightweight since it employs the recurrent structure for its parameter efficiency. We validate the effectiveness of ReconFormer on multiple datasets with different magnetic resonance sequences and show that it achieves significant improvements over the state-of-the-art methods with better parameter efficiency. Implementation code will be available in https://github.com/guopengf/ReconFormer.
Over-and-Under Complete Convolutional RNN for MRI Reconstruction
Jun 25, 2021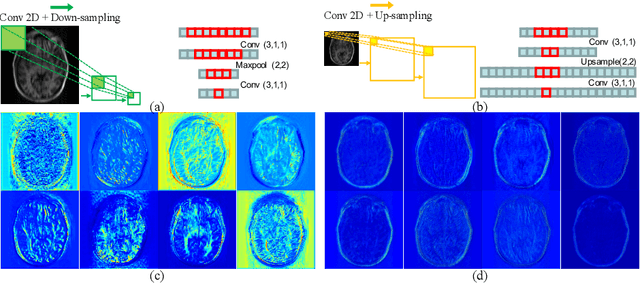
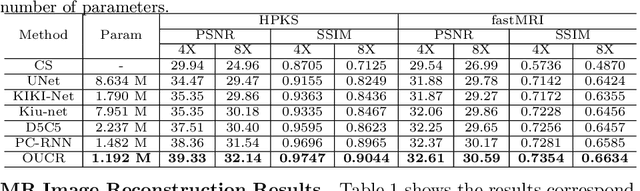
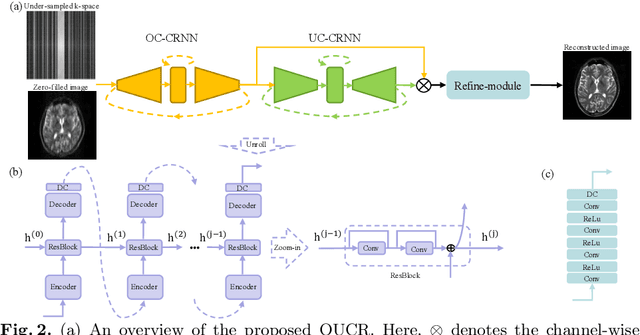
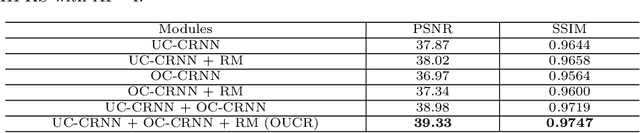
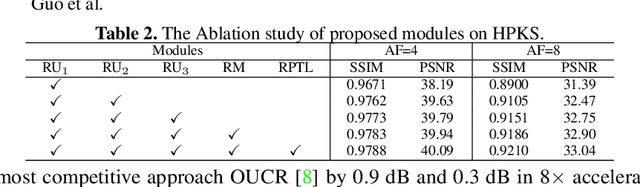
Reconstructing magnetic resonance (MR) images from undersampled data is a challenging problem due to various artifacts introduced by the under-sampling operation. Recent deep learning-based methods for MR image reconstruction usually leverage a generic auto-encoder architecture which captures low-level features at the initial layers and high-level features at the deeper layers. Such networks focus much on global features which may not be optimal to reconstruct the fully-sampled image. In this paper, we propose an Over-and-Under Complete Convolutional Recurrent Neural Network (OUCR), which consists of an overcomplete and an undercomplete Convolutional Recurrent Neural Network(CRNN). The overcomplete branch gives special attention in learning local structures by restraining the receptive field of the network. Combining it with the undercomplete branch leads to a network which focuses more on low-level features without losing out on the global structures. Extensive experiments on two datasets demonstrate that the proposed method achieves significant improvements over the compressed sensing and popular deep learning-based methods with less number of trainable parameters.
ModelPS: An Interactive and Collaborative Platform for Editing Pre-trained Models at Scale
May 26, 2021
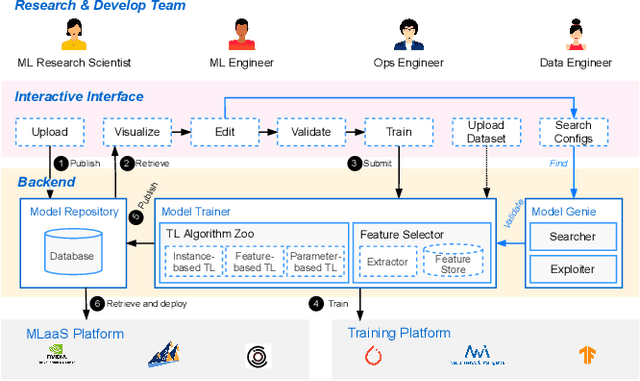
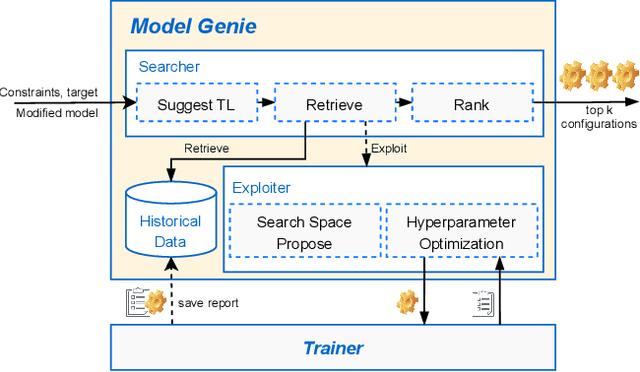
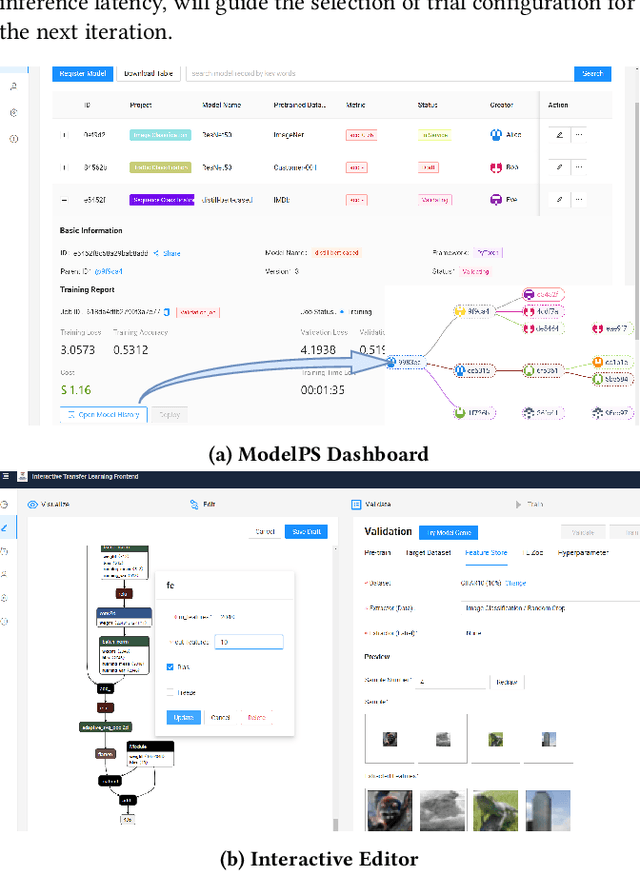
AI engineering has emerged as a crucial discipline to democratize deep neural network (DNN) models among software developers with a diverse background. In particular, altering these DNN models in the deployment stage posits a tremendous challenge. In this research, we propose and develop a low-code solution, ModelPS (an acronym for "Model Photoshop"), to enable and empower collaborative DNN model editing and intelligent model serving. The ModelPS solution embodies two transformative features: 1) a user-friendly web interface for a developer team to share and edit DNN models pictorially, in a low-code fashion, and 2) a model genie engine in the backend to aid developers in customizing model editing configurations for given deployment requirements or constraints. Our case studies with a wide range of deep learning (DL) models show that the system can tremendously reduce both development and communication overheads with improved productivity. The code has been released as an open-source package at GitHub.