 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillPyramid: A Hierarchical Skill Consolidation Framework for Self-Evolving Agents
Jun 02, 2026Recent AI agents can flexibly invoke skills to solve complex tasks, but their long-term improvement is fundamentally constrained by a lack of systematic skill construction, accumulation, and transfer. In particular, without a unified framework for skill consolidation, agents tend to redundantly construct similar capabilities across different tasks, are unable to effectively transform experience into reusable assets, and struggle to generalize task-specific skills to novel scenarios. To address this limitation, we propose SkillPyramid, a skill consolidation framework that reuses existing skill experience for broader task generalization. Operating on a hierarchical skill topology, SkillPyramid further introduces a self-evolution mechanism that enables agents to compose, validate, and incorporate new skills during task execution. Experiments on ALFWorld, WebShop, and ScienceWorld across four backbone models show that SkillPyramid substantially increases the average reward by 38.0% and reduces execution steps by 27.7%. Overall, our method transforms a skill collection from a static resource pool into a dynamic evolution system.
DV-World: Benchmarking Data Visualization Agents in Real-World Scenarios
Apr 28, 2026Real-world data visualization (DV) requires native environmental grounding, cross-platform evolution, and proactive intent alignment. Yet, existing benchmarks often suffer from code-sandbox confinement, single-language creation-only tasks, and assumption of perfect intent. To bridge these gaps, we introduce DV-World, a benchmark of 260 tasks designed to evaluate DV agents across real-world professional lifecycles. DV-World spans three domains: DV-Sheet for native spreadsheet manipulation including chart and dashboard creation as well as diagnostic repair; DV-Evolution for adapting and restructuring reference visual artifacts to fit new data across diverse programming paradigms and DV-Interact for proactive intent alignment with a user simulator that mimics real-world ambiguous requirements. Our hybrid evaluation framework integrates Table-value Alignment for numerical precision and MLLM-as-a-Judge with rubrics for semantic-visual assessment. Experiments reveal that state-of-the-art models achieve less than 50% overall performance, exposing critical deficits in handling the complex challenges of real-world data visualization. DV-World provides a realistic testbed to steer development toward the versatile expertise required in enterprise workflows. Our data and code are available at \href{https://github.com/DA-Open/DV-World}{this project page}.
From $P(y|x)$ to $P(y)$: Investigating Reinforcement Learning in Pre-train Space
Apr 15, 2026While reinforcement learning with verifiable rewards (RLVR) significantly enhances LLM reasoning by optimizing the conditional distribution P(y|x), its potential is fundamentally bounded by the base model's existing output distribution. Optimizing the marginal distribution P(y) in the Pre-train Space addresses this bottleneck by encoding reasoning ability and preserving broad exploration capacity. Yet, conventional pre-training relies on static corpora for passive learning, leading to a distribution shift that hinders targeted reasoning enhancement. In this paper, we introduce PreRL (Pre-train Space RL), which applies reward-driven online updates directly to P(y). We theoretically and empirically validate the strong gradient alignment between log P(y) and log P(y|x), establishing PreRL as a viable surrogate for standard RL. Furthermore, we uncover a critical mechanism: Negative Sample Reinforcement (NSR) within PreRL serves as an exceptionally effective driver for reasoning. NSR-PreRL rapidly prunes incorrect reasoning spaces while stimulating endogenous reflective behaviors, increasing transition and reflection thoughts by 14.89x and 6.54x, respectively. Leveraging these insights, we propose Dual Space RL (DSRL), a Policy Reincarnation strategy that initializes models with NSR-PreRL to expand the reasoning horizon before transitioning to standard RL for fine-grained optimization. Extensive experiments demonstrate that DSRL consistently outperforms strong baselines, proving that pre-train space pruning effectively steers the policy toward a refined correct reasoning subspace.
ResAdapt: Adaptive Resolution for Efficient Multimodal Reasoning
Mar 31, 2026Multimodal Large Language Models (MLLMs) achieve stronger visual understanding by scaling input fidelity, yet the resulting visual token growth makes jointly sustaining high spatial resolution and long temporal context prohibitive. We argue that the bottleneck lies not in how post-encoding representations are compressed but in the volume of pixels the encoder receives, and address it with ResAdapt, an Input-side adaptation framework that learns how much visual budget each frame should receive before encoding. ResAdapt couples a lightweight Allocator with an unchanged MLLM backbone, so the backbone retains its native visual-token interface while receiving an operator-transformed input. We formulate allocation as a contextual bandit and train the Allocator with Cost-Aware Policy Optimization (CAPO), which converts sparse rollout feedback into a stable accuracy-cost learning signal. Across budget-controlled video QA, temporal grounding, and image reasoning tasks, ResAdapt improves low-budget operating points and often lies on or near the efficiency-accuracy frontier, with the clearest gains on reasoning-intensive benchmarks under aggressive compression. Notably, ResAdapt supports up to 16x more frames at the same visual budget while delivering over 15% performance gain. Code is available at https://github.com/Xnhyacinth/ResAdapt.
WideSeek: Advancing Wide Research via Multi-Agent Scaling
Feb 02, 2026Search intelligence is evolving from Deep Research to Wide Research, a paradigm essential for retrieving and synthesizing comprehensive information under complex constraints in parallel. However, progress in this field is impeded by the lack of dedicated benchmarks and optimization methodologies for search breadth. To address these challenges, we take a deep dive into Wide Research from two perspectives: Data Pipeline and Agent Optimization. First, we produce WideSeekBench, a General Broad Information Seeking (GBIS) benchmark constructed via a rigorous multi-phase data pipeline to ensure diversity across the target information volume, logical constraints, and domains. Second, we introduce WideSeek, a dynamic hierarchical multi-agent architecture that can autonomously fork parallel sub-agents based on task requirements. Furthermore, we design a unified training framework that linearizes multi-agent trajectories and optimizes the system using end-to-end RL. Experimental results demonstrate the effectiveness of WideSeek and multi-agent RL, highlighting that scaling the number of agents is a promising direction for advancing the Wide Research paradigm.
Bottom-up Policy Optimization: Your Language Model Policy Secretly Contains Internal Policies
Dec 22, 2025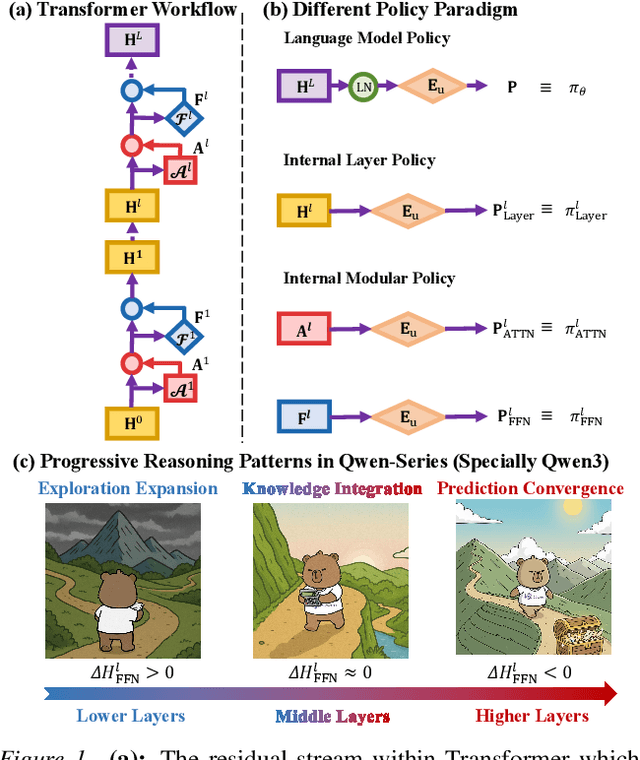
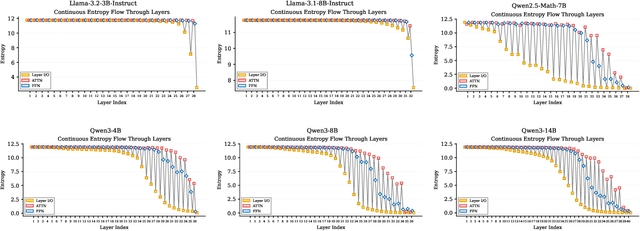
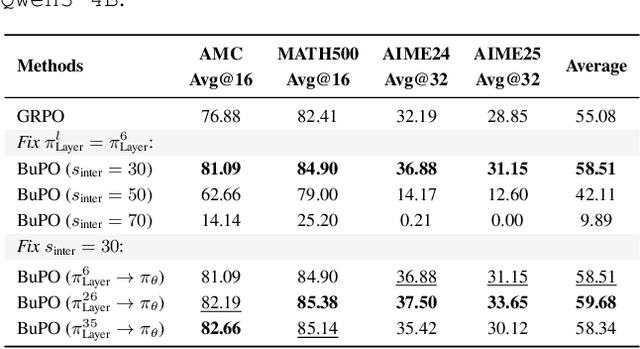
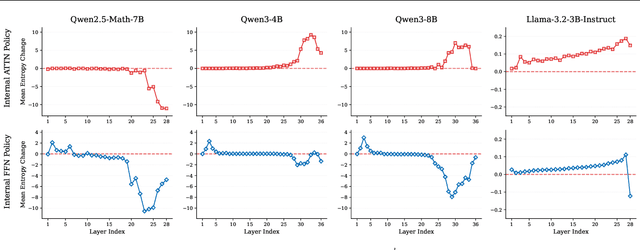
Existing reinforcement learning (RL) approaches treat large language models (LLMs) as a single unified policy, overlooking their internal mechanisms. Understanding how policy evolves across layers and modules is therefore crucial for enabling more targeted optimization and raveling out complex reasoning mechanisms. In this paper, we decompose the language model policy by leveraging the intrinsic split of the Transformer residual stream and the equivalence between the composition of hidden states with the unembedding matrix and the resulting samplable policy. This decomposition reveals Internal Layer Policies, corresponding to contributions from individual layers, and Internal Modular Policies, which align with the self-attention and feed-forward network (FFN) components within each layer. By analyzing the entropy of internal policy, we find that: (a) Early layers keep high entropy for exploration, top layers converge to near-zero entropy for refinement, with convergence patterns varying across model series. (b) LLama's prediction space rapidly converges in the final layer, whereas Qwen-series models, especially Qwen3, exhibit a more human-like, progressively structured reasoning pattern. Motivated by these findings, we propose Bottom-up Policy Optimization (BuPO), a novel RL paradigm that directly optimizes the internal layer policy during early training. By aligning training objective at lower layer, BuPO reconstructs foundational reasoning capabilities and achieves superior performance. Extensive experiments on complex reasoning benchmarks demonstrates the effectiveness of our method. Our code is available at https://github.com/Trae1ounG/BuPO.
The Zero-Step Thinking: An Empirical Study of Mode Selection as Harder Early Exit in Reasoning Models
Oct 22, 2025Reasoning models have demonstrated exceptional performance in tasks such as mathematics and logical reasoning, primarily due to their ability to engage in step-by-step thinking during the reasoning process. However, this often leads to overthinking, resulting in unnecessary computational overhead. To address this issue, Mode Selection aims to automatically decide between Long-CoT (Chain-of-Thought) or Short-CoT by utilizing either a Thinking or NoThinking mode. Simultaneously, Early Exit determines the optimal stopping point during the iterative reasoning process. Both methods seek to reduce the computational burden. In this paper, we first identify Mode Selection as a more challenging variant of the Early Exit problem, as they share similar objectives but differ in decision timing. While Early Exit focuses on determining the best stopping point for concise reasoning at inference time, Mode Selection must make this decision at the beginning of the reasoning process, relying on pre-defined fake thoughts without engaging in an explicit reasoning process, referred to as zero-step thinking. Through empirical studies on nine baselines, we observe that prompt-based approaches often fail due to their limited classification capabilities when provided with minimal hand-crafted information. In contrast, approaches that leverage internal information generally perform better across most scenarios but still exhibit issues with stability. Our findings indicate that existing methods relying solely on the information provided by models are insufficient for effectively addressing Mode Selection in scenarios with limited information, highlighting the ongoing challenges of this task. Our code is available at https://github.com/Trae1ounG/Zero_Step_Thinking.
Towards Agentic Self-Learning LLMs in Search Environment
Oct 16, 2025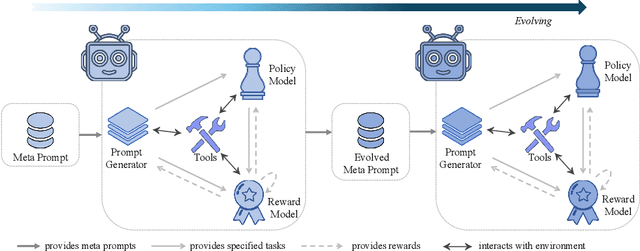
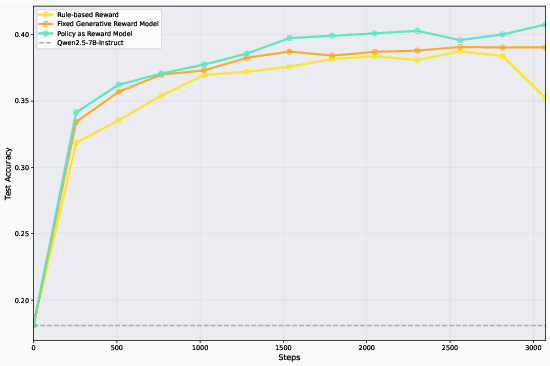
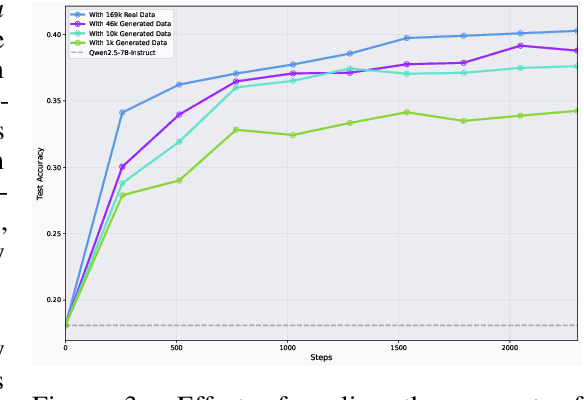
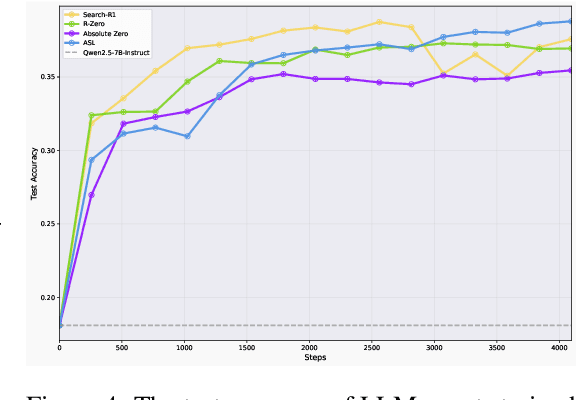
We study whether self-learning can scale LLM-based agents without relying on human-curated datasets or predefined rule-based rewards. Through controlled experiments in a search-agent setting, we identify two key determinants of scalable agent training: the source of reward signals and the scale of agent task data. We find that rewards from a Generative Reward Model (GRM) outperform rigid rule-based signals for open-domain learning, and that co-evolving the GRM with the policy further boosts performance. Increasing the volume of agent task data-even when synthetically generated-substantially enhances agentic capabilities. Building on these insights, we propose \textbf{Agentic Self-Learning} (ASL), a fully closed-loop, multi-role reinforcement learning framework that unifies task generation, policy execution, and evaluation within a shared tool environment and LLM backbone. ASL coordinates a Prompt Generator, a Policy Model, and a Generative Reward Model to form a virtuous cycle of harder task setting, sharper verification, and stronger solving. Empirically, ASL delivers steady, round-over-round gains, surpasses strong RLVR baselines (e.g., Search-R1) that plateau or degrade, and continues improving under zero-labeled-data conditions, indicating superior sample efficiency and robustness. We further show that GRM verification capacity is the main bottleneck: if frozen, it induces reward hacking and stalls progress; continual GRM training on the evolving data distribution mitigates this, and a small late-stage injection of real verification data raises the performance ceiling. This work establishes reward source and data scale as critical levers for open-domain agent learning and demonstrates the efficacy of multi-role co-evolution for scalable, self-improving agents. The data and code of this paper are released at https://github.com/forangel2014/Towards-Agentic-Self-Learning
SparK: Query-Aware Unstructured Sparsity with Recoverable KV Cache Channel Pruning
Aug 21, 2025Long-context inference in large language models (LLMs) is increasingly constrained by the KV cache bottleneck: memory usage grows linearly with sequence length, while attention computation scales quadratically. Existing approaches address this issue by compressing the KV cache along the temporal axis through strategies such as token eviction or merging to reduce memory and computational overhead. However, these methods often neglect fine-grained importance variations across feature dimensions (i.e., the channel axis), thereby limiting their ability to effectively balance efficiency and model accuracy. In reality, we observe that channel saliency varies dramatically across both queries and positions: certain feature channels carry near-zero information for a given query, while others spike in relevance. To address this oversight, we propose SPARK, a training-free plug-and-play method that applies unstructured sparsity by pruning KV at the channel level, while dynamically restoring the pruned entries during attention score computation. Notably, our approach is orthogonal to existing KV compression and quantization techniques, making it compatible for integration with them to achieve further acceleration. By reducing channel-level redundancy, SPARK enables processing of longer sequences within the same memory budget. For sequences of equal length, SPARK not only preserves or improves model accuracy but also reduces KV cache storage by over 30% compared to eviction-based methods. Furthermore, even with an aggressive pruning ratio of 80%, SPARK maintains performance with less degradation than 5% compared to the baseline eviction method, demonstrating its robustness and effectiveness. Our code will be available at https://github.com/Xnhyacinth/SparK.
Socratic-PRMBench: Benchmarking Process Reward Models with Systematic Reasoning Patterns
May 29, 2025Process Reward Models (PRMs) are crucial in complex reasoning and problem-solving tasks (e.g., LLM agents with long-horizon decision-making) by verifying the correctness of each intermediate reasoning step. In real-world scenarios, LLMs may apply various reasoning patterns (e.g., decomposition) to solve a problem, potentially suffering from errors under various reasoning patterns. Therefore, PRMs are required to identify errors under various reasoning patterns during the reasoning process. However, existing benchmarks mainly focus on evaluating PRMs with stepwise correctness, ignoring a systematic evaluation of PRMs under various reasoning patterns. To mitigate this gap, we introduce Socratic-PRMBench, a new benchmark to evaluate PRMs systematically under six reasoning patterns, including Transformation, Decomposition, Regather, Deduction, Verification, and Integration. Socratic-PRMBench}comprises 2995 reasoning paths with flaws within the aforementioned six reasoning patterns. Through our experiments on both PRMs and LLMs prompted as critic models, we identify notable deficiencies in existing PRMs. These observations underscore the significant weakness of current PRMs in conducting evaluations on reasoning steps under various reasoning patterns. We hope Socratic-PRMBench can serve as a comprehensive testbed for systematic evaluation of PRMs under diverse reasoning patterns and pave the way for future development of PRMs.