 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniMoE: An Efficient MoE by Orchestrating Atomic Experts at Scale
Feb 05, 2026Mixture-of-Experts (MoE) architectures are evolving towards finer granularity to improve parameter efficiency. However, existing MoE designs face an inherent trade-off between the granularity of expert specialization and hardware execution efficiency. We propose OmniMoE, a system-algorithm co-designed framework that pushes expert granularity to its logical extreme. OmniMoE introduces vector-level Atomic Experts, enabling scalable routing and execution within a single MoE layer, while retaining a shared dense MLP branch for general-purpose processing. Although this atomic design maximizes capacity, it poses severe challenges for routing complexity and memory access. To address these, OmniMoE adopts a system-algorithm co-design: (i) a Cartesian Product Router that decomposes the massive index space to reduce routing complexity from O(N) to O(sqrt(N)); and (ii) Expert-Centric Scheduling that inverts the execution order to turn scattered, memory-bound lookups into efficient dense matrix operations. Validated on seven benchmarks, OmniMoE (with 1.7B active parameters) achieves 50.9% zero-shot accuracy across seven benchmarks, outperforming coarse-grained (e.g., DeepSeekMoE) and fine-grained (e.g., PEER) baselines. Crucially, OmniMoE reduces inference latency from 73ms to 6.7ms (a 10.9-fold speedup) compared to PEER, demonstrating that massive-scale fine-grained MoE can be fast and accurate. Our code is open-sourced at https://github.com/flash-algo/omni-moe.
Towards Automated Kernel Generation in the Era of LLMs
Jan 26, 2026The performance of modern AI systems is fundamentally constrained by the quality of their underlying kernels, which translate high-level algorithmic semantics into low-level hardware operations. Achieving near-optimal kernels requires expert-level understanding of hardware architectures and programming models, making kernel engineering a critical but notoriously time-consuming and non-scalable process. Recent advances in large language models (LLMs) and LLM-based agents have opened new possibilities for automating kernel generation and optimization. LLMs are well-suited to compress expert-level kernel knowledge that is difficult to formalize, while agentic systems further enable scalable optimization by casting kernel development as an iterative, feedback-driven loop. Rapid progress has been made in this area. However, the field remains fragmented, lacking a systematic perspective for LLM-driven kernel generation. This survey addresses this gap by providing a structured overview of existing approaches, spanning LLM-based approaches and agentic optimization workflows, and systematically compiling the datasets and benchmarks that underpin learning and evaluation in this domain. Moreover, key open challenges and future research directions are further outlined, aiming to establish a comprehensive reference for the next generation of automated kernel optimization. To keep track of this field, we maintain an open-source GitHub repository at https://github.com/flagos-ai/awesome-LLM-driven-kernel-generation.
CCI4.0: A Bilingual Pretraining Dataset for Enhancing Reasoning in Large Language Models
Jun 09, 2025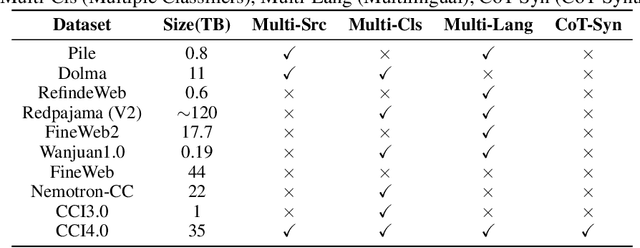
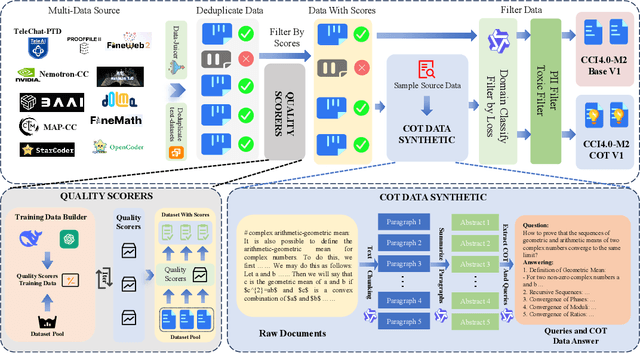
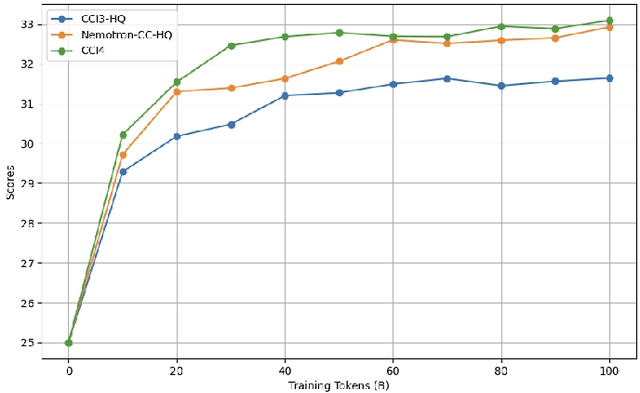
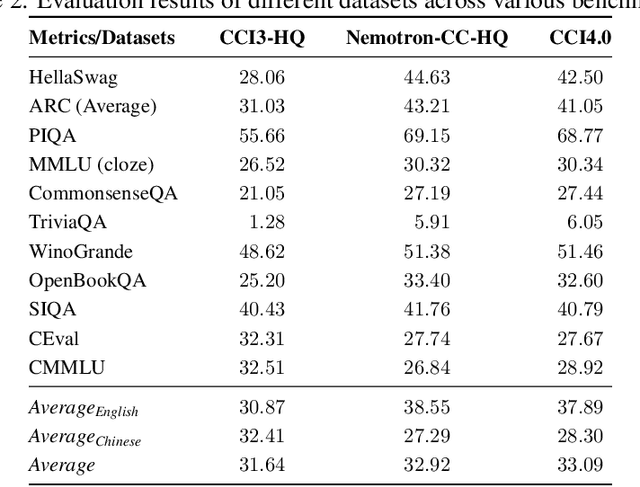
We introduce CCI4.0, a large-scale bilingual pre-training dataset engineered for superior data quality and diverse human-like reasoning trajectory. CCI4.0 occupies roughly $35$ TB of disk space and comprises two sub-datasets: CCI4.0-M2-Base and CCI4.0-M2-CoT. CCI4.0-M2-Base combines a $5.2$ TB carefully curated Chinese web corpus, a $22.5$ TB English subset from Nemotron-CC, and diverse sources from math, wiki, arxiv, and code. Although these data are mostly sourced from well-processed datasets, the quality standards of various domains are dynamic and require extensive expert experience and labor to process. So, we propose a novel pipeline justifying data quality mainly based on models through two-stage deduplication, multiclassifier quality scoring, and domain-aware fluency filtering. We extract $4.5$ billion pieces of CoT(Chain-of-Thought) templates, named CCI4.0-M2-CoT. Differing from the distillation of CoT from larger models, our proposed staged CoT extraction exemplifies diverse reasoning patterns and significantly decreases the possibility of hallucination. Empirical evaluations demonstrate that LLMs pre-trained in CCI4.0 benefit from cleaner, more reliable training signals, yielding consistent improvements in downstream tasks, especially in math and code reflection tasks. Our results underscore the critical role of rigorous data curation and human thinking templates in advancing LLM performance, shedding some light on automatically processing pretraining corpora.
Amplify Adjacent Token Differences: Enhancing Long Chain-of-Thought Reasoning with Shift-FFN
May 22, 2025Recently, models such as OpenAI-o1 and DeepSeek-R1 have demonstrated remarkable performance on complex reasoning tasks through Long Chain-of-Thought (Long-CoT) reasoning. Although distilling this capability into student models significantly enhances their performance, this paper finds that fine-tuning LLMs with full parameters or LoRA with a low rank on long CoT data often leads to Cyclical Reasoning, where models repeatedly reiterate previous inference steps until the maximum length limit. Further analysis reveals that smaller differences in representations between adjacent tokens correlates with a higher tendency toward Cyclical Reasoning. To mitigate this issue, this paper proposes Shift Feedforward Networks (Shift-FFN), a novel approach that edits the current token's representation with the previous one before inputting it to FFN. This architecture dynamically amplifies the representation differences between adjacent tokens. Extensive experiments on multiple mathematical reasoning tasks demonstrate that LoRA combined with Shift-FFN achieves higher accuracy and a lower rate of Cyclical Reasoning across various data sizes compared to full fine-tuning and standard LoRA. Our data and code are available at https://anonymous.4open.science/r/Shift-FFN
InCo-DPO: Balancing Distribution Shift and Data Quality for Enhanced Preference Optimization
Mar 20, 2025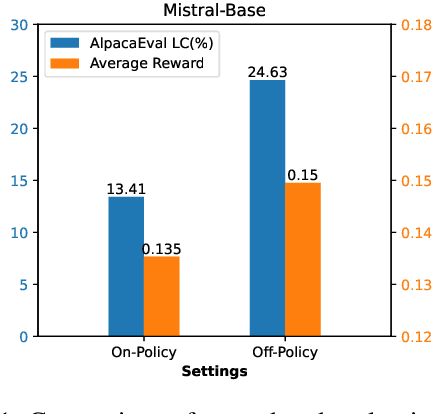
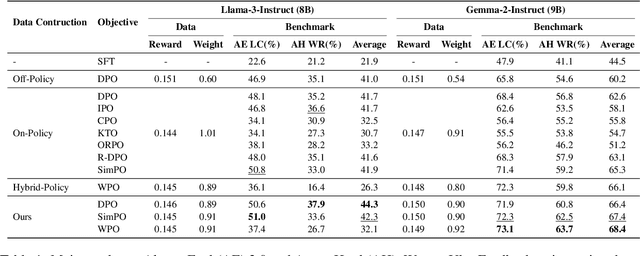
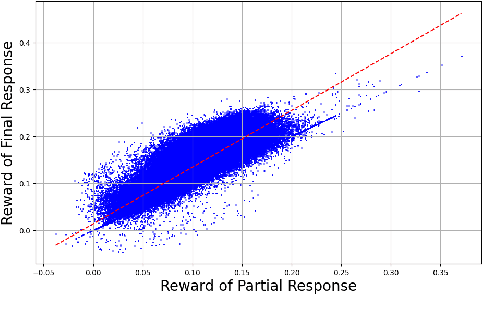
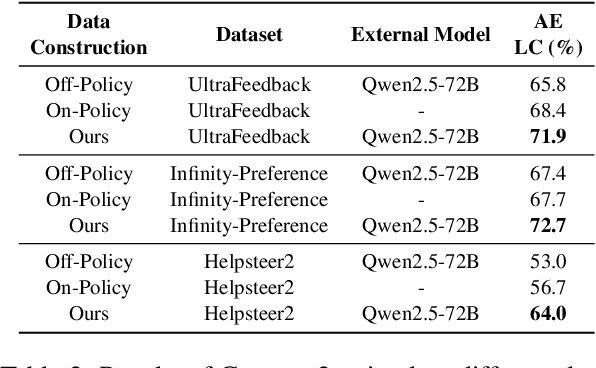
Direct Preference Optimization (DPO) optimizes language models to align with human preferences. Utilizing on-policy samples, generated directly by the policy model, typically results in better performance due to its distribution consistency with the model compared to off-policy samples. This paper identifies the quality of candidate preference samples as another critical factor. While the quality of on-policy data is inherently constrained by the capabilities of the policy model, off-policy data, which can be derived from diverse sources, offers greater potential for quality despite experiencing distribution shifts. However, current research mostly relies on on-policy data and neglects the value of off-policy data in terms of data quality, due to the challenge posed by distribution shift. In this paper, we propose InCo-DPO, an efficient method for synthesizing preference data by integrating on-policy and off-policy data, allowing dynamic adjustments to balance distribution shifts and data quality, thus finding an optimal trade-off. Consequently, InCo-DPO overcomes the limitations of distribution shifts in off-policy data and the quality constraints of on-policy data. We evaluated InCo-DPO with the Alpaca-Eval 2.0 and Arena-Hard benchmarks. Experimental results demonstrate that our approach not only outperforms both on-policy and off-policy data but also achieves a state-of-the-art win rate of 60.8 on Arena-Hard with the vanilla DPO using Gemma-2 model.
Predictable Emergent Abilities of LLMs: Proxy Tasks Are All You Need
Dec 10, 2024



While scaling laws optimize training configurations for large language models (LLMs) through experiments on smaller or early-stage models, they fail to predict emergent abilities due to the absence of such capabilities in these models. To address this, we propose a method that predicts emergent abilities by leveraging proxy tasks. We begin by establishing relevance metrics between the target task and candidate tasks based on performance differences across multiple models. These candidate tasks are then validated for robustness with small model ensembles, leading to the selection of the most appropriate proxy tasks. The predicted performance on the target task is then derived by integrating the evaluation results of these proxies. In a case study on tool utilization capabilities, our method demonstrated a strong correlation between predicted and actual performance, confirming its effectiveness.
LLaSA: Large Language and Structured Data Assistant
Nov 16, 2024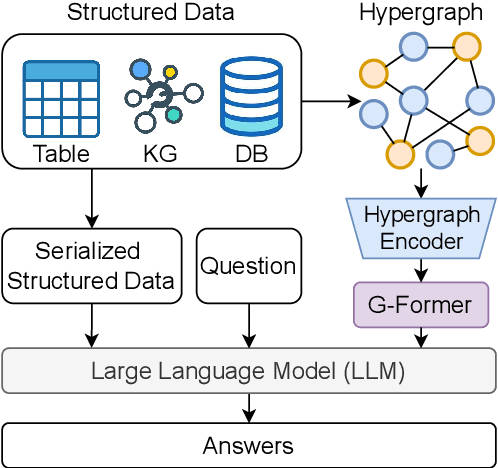
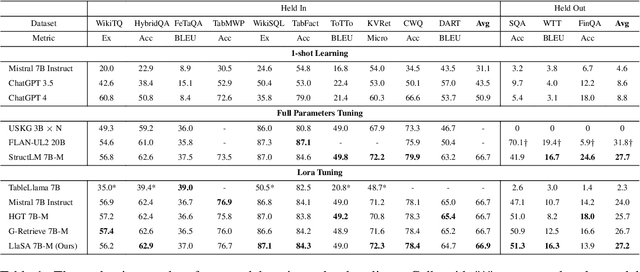
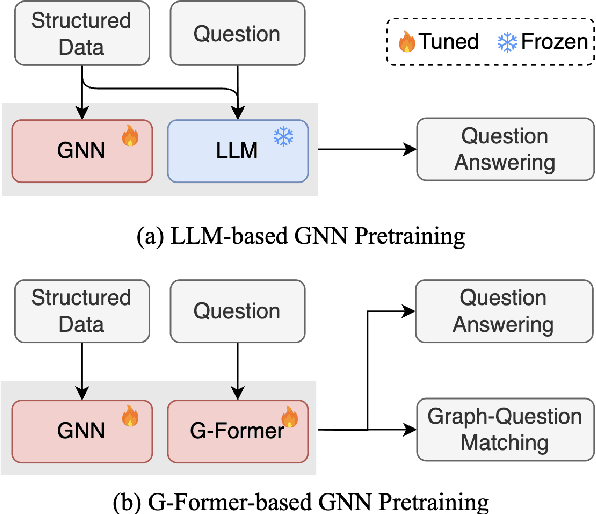
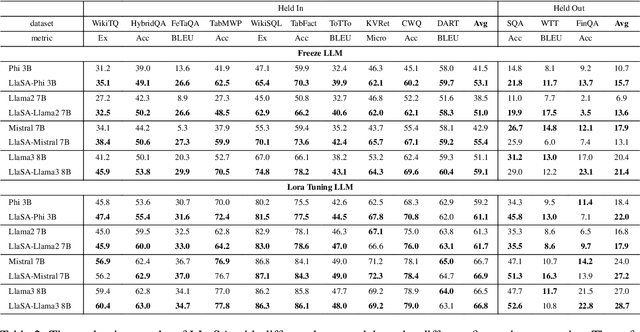
Structured data, such as tables, graphs, and databases, play a critical role in plentiful NLP tasks such as question answering and dialogue system. Recently, inspired by Vision-Language Models, Graph Neutral Networks (GNNs) have been introduced as an additional modality into the input of Large Language Models (LLMs) to improve their performance on Structured Knowledge Grounding (SKG) tasks. However, those GNN-enhanced LLMs have the following limitations: (1) They employ diverse GNNs to model varying types of structured data, rendering them unable to uniformly process various forms of structured data. (2) The pretraining of GNNs is coupled with specific LLMs, which prevents GNNs from fully aligning with the textual space and limits their adaptability to other LLMs. To address these issues, we propose \textbf{L}arge \textbf{L}anguage and \textbf{S}tructured Data \textbf{A}ssistant (LLaSA), a general framework for enhancing LLMs' ability to handle structured data. Specifically, we represent various types of structured data in a unified hypergraph format, and use self-supervised learning to pretrain a hypergraph encoder, and a G-Former compressing encoded hypergraph representations with cross-attention. The compressed hypergraph representations are appended to the serialized inputs during training and inference stages of LLMs. Experimental results on multiple SKG tasks show that our pretrained hypergraph encoder can adapt to various LLMs and enhance their ability to process different types of structured data. Besides, LLaSA, with LoRA fine-tuning, outperforms previous SOTA method using full parameters tuning.
CCI3.0-HQ: a large-scale Chinese dataset of high quality designed for pre-training large language models
Oct 24, 2024We present CCI3.0-HQ (https://huggingface.co/datasets/BAAI/CCI3-HQ), a high-quality 500GB subset of the Chinese Corpora Internet 3.0 (CCI3.0)(https://huggingface.co/datasets/BAAI/CCI3-Data), developed using a novel two-stage hybrid filtering pipeline that significantly enhances data quality. To evaluate its effectiveness, we trained a 0.5B parameter model from scratch on 100B tokens across various datasets, achieving superior performance on 10 benchmarks in a zero-shot setting compared to CCI3.0, SkyPile, and WanjuanV1. The high-quality filtering process effectively distills the capabilities of the Qwen2-72B-instruct model into a compact 0.5B model, attaining optimal F1 scores for Chinese web data classification. We believe this open-access dataset will facilitate broader access to high-quality language models.
Infinity-MM: Scaling Multimodal Performance with Large-Scale and High-Quality Instruction Data
Oct 24, 2024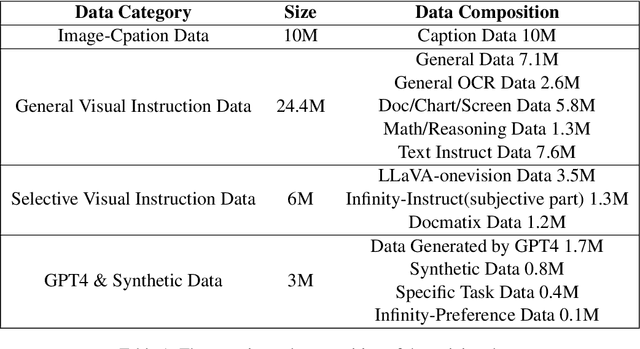
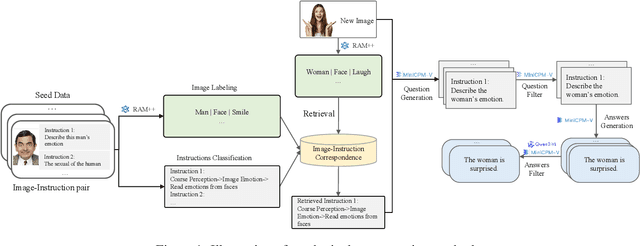
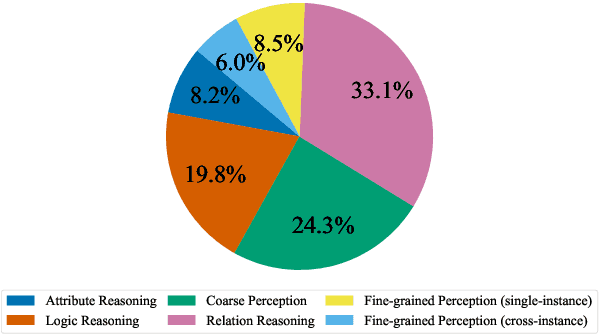
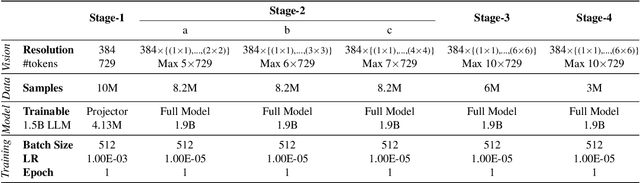
Vision-Language Models (VLMs) have recently made significant progress, but the limited scale and quality of open-source instruction data hinder their performance compared to closed-source models. In this work, we address this limitation by introducing Infinity-MM, a large-scale multimodal instruction dataset with 40 million samples, enhanced through rigorous quality filtering and deduplication. We also propose a synthetic instruction generation method based on open-source VLMs, using detailed image annotations and diverse question generation. Using this data, we trained a 2-billion-parameter VLM, Aquila-VL-2B, achieving state-of-the-art (SOTA) performance for models of similar scale. This demonstrates that expanding instruction data and generating synthetic data can significantly improve the performance of open-source models.
ReTok: Replacing Tokenizer to Enhance Representation Efficiency in Large Language Model
Oct 06, 2024Tokenizer is an essential component for large language models (LLMs), and a tokenizer with a high compression rate can improve the model's representation and processing efficiency. However, the tokenizer cannot ensure high compression rate in all scenarios, and an increase in the average input and output lengths will increases the training and inference costs of the model. Therefore, it is crucial to find ways to improve the model's efficiency with minimal cost while maintaining the model's performance. In this work, we propose a method to improve model representation and processing efficiency by replacing the tokenizers of LLMs. We propose replacing and reinitializing the parameters of the model's input and output layers with the parameters of the original model, and training these parameters while keeping other parameters fixed. We conducted experiments on different LLMs, and the results show that our method can maintain the performance of the model after replacing the tokenizer, while significantly improving the decoding speed for long texts.