 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiMo-V2-Flash Technical Report
Jan 08, 2026We present MiMo-V2-Flash, a Mixture-of-Experts (MoE) model with 309B total parameters and 15B active parameters, designed for fast, strong reasoning and agentic capabilities. MiMo-V2-Flash adopts a hybrid attention architecture that interleaves Sliding Window Attention (SWA) with global attention, with a 128-token sliding window under a 5:1 hybrid ratio. The model is pre-trained on 27 trillion tokens with Multi-Token Prediction (MTP), employing a native 32k context length and subsequently extended to 256k. To efficiently scale post-training compute, MiMo-V2-Flash introduces a novel Multi-Teacher On-Policy Distillation (MOPD) paradigm. In this framework, domain-specialized teachers (e.g., trained via large-scale reinforcement learning) provide dense and token-level reward, enabling the student model to perfectly master teacher expertise. MiMo-V2-Flash rivals top-tier open-weight models such as DeepSeek-V3.2 and Kimi-K2, despite using only 1/2 and 1/3 of their total parameters, respectively. During inference, by repurposing MTP as a draft model for speculative decoding, MiMo-V2-Flash achieves up to 3.6 acceptance length and 2.6x decoding speedup with three MTP layers. We open-source both the model weights and the three-layer MTP weights to foster open research and community collaboration.
MiMo-Audio: Audio Language Models are Few-Shot Learners
Dec 29, 2025Existing audio language models typically rely on task-specific fine-tuning to accomplish particular audio tasks. In contrast, humans are able to generalize to new audio tasks with only a few examples or simple instructions. GPT-3 has shown that scaling next-token prediction pretraining enables strong generalization capabilities in text, and we believe this paradigm is equally applicable to the audio domain. By scaling MiMo-Audio's pretraining data to over one hundred million of hours, we observe the emergence of few-shot learning capabilities across a diverse set of audio tasks. We develop a systematic evaluation of these capabilities and find that MiMo-Audio-7B-Base achieves SOTA performance on both speech intelligence and audio understanding benchmarks among open-source models. Beyond standard metrics, MiMo-Audio-7B-Base generalizes to tasks absent from its training data, such as voice conversion, style transfer, and speech editing. MiMo-Audio-7B-Base also demonstrates powerful speech continuation capabilities, capable of generating highly realistic talk shows, recitations, livestreaming and debates. At the post-training stage, we curate a diverse instruction-tuning corpus and introduce thinking mechanisms into both audio understanding and generation. MiMo-Audio-7B-Instruct achieves open-source SOTA on audio understanding benchmarks (MMSU, MMAU, MMAR, MMAU-Pro), spoken dialogue benchmarks (Big Bench Audio, MultiChallenge Audio) and instruct-TTS evaluations, approaching or surpassing closed-source models. Model checkpoints and full evaluation suite are available at https://github.com/XiaomiMiMo/MiMo-Audio.
GroundingME: Exposing the Visual Grounding Gap in MLLMs through Multi-Dimensional Evaluation
Dec 19, 2025Visual grounding, localizing objects from natural language descriptions, represents a critical bridge between language and vision understanding. While multimodal large language models (MLLMs) achieve impressive scores on existing benchmarks, a fundamental question remains: can MLLMs truly ground language in vision with human-like sophistication, or are they merely pattern-matching on simplified datasets? Current benchmarks fail to capture real-world complexity where humans effortlessly navigate ambiguous references and recognize when grounding is impossible. To rigorously assess MLLMs' true capabilities, we introduce GroundingME, a benchmark that systematically challenges models across four critical dimensions: (1) Discriminative, distinguishing highly similar objects, (2) Spatial, understanding complex relational descriptions, (3) Limited, handling occlusions or tiny objects, and (4) Rejection, recognizing ungroundable queries. Through careful curation combining automated generation with human verification, we create 1,005 challenging examples mirroring real-world complexity. Evaluating 25 state-of-the-art MLLMs reveals a profound capability gap: the best model achieves only 45.1% accuracy, while most score 0% on rejection tasks, reflexively hallucinating objects rather than acknowledging their absence, raising critical safety concerns for deployment. We explore two strategies for improvements: (1) test-time scaling selects optimal response by thinking trajectory to improve complex grounding by up to 2.9%, and (2) data-mixture training teaches models to recognize ungroundable queries, boosting rejection accuracy from 0% to 27.9%. GroundingME thus serves as both a diagnostic tool revealing current limitations in MLLMs and a roadmap toward human-level visual grounding.
MiMo: Unlocking the Reasoning Potential of Language Model -- From Pretraining to Posttraining
May 12, 2025We present MiMo-7B, a large language model born for reasoning tasks, with optimization across both pre-training and post-training stages. During pre-training, we enhance the data preprocessing pipeline and employ a three-stage data mixing strategy to strengthen the base model's reasoning potential. MiMo-7B-Base is pre-trained on 25 trillion tokens, with additional Multi-Token Prediction objective for enhanced performance and accelerated inference speed. During post-training, we curate a dataset of 130K verifiable mathematics and programming problems for reinforcement learning, integrating a test-difficulty-driven code-reward scheme to alleviate sparse-reward issues and employing strategic data resampling to stabilize training. Extensive evaluations show that MiMo-7B-Base possesses exceptional reasoning potential, outperforming even much larger 32B models. The final RL-tuned model, MiMo-7B-RL, achieves superior performance on mathematics, code and general reasoning tasks, surpassing the performance of OpenAI o1-mini. The model checkpoints are available at https://github.com/xiaomimimo/MiMo.
Infinity-MM: Scaling Multimodal Performance with Large-Scale and High-Quality Instruction Data
Oct 24, 2024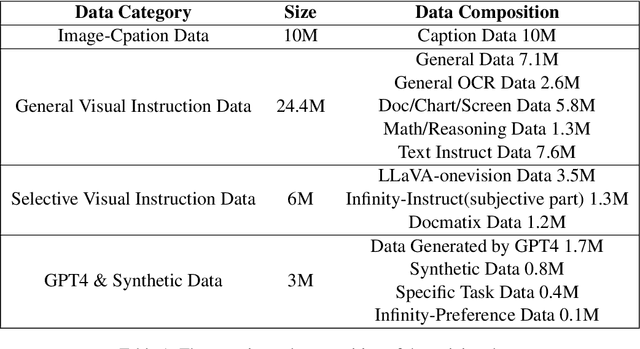
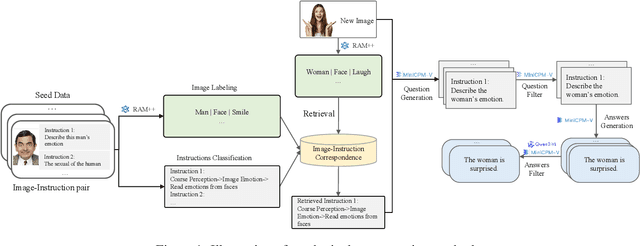
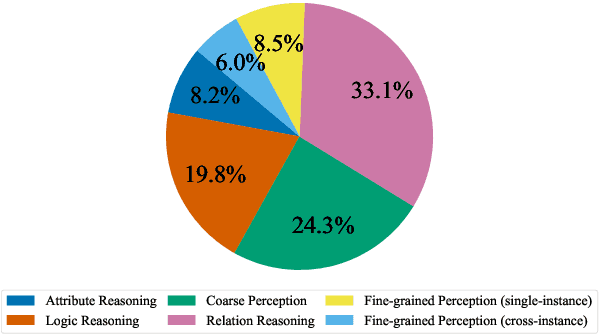
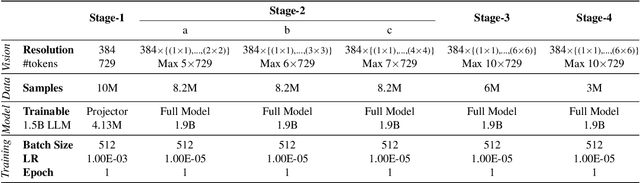
Vision-Language Models (VLMs) have recently made significant progress, but the limited scale and quality of open-source instruction data hinder their performance compared to closed-source models. In this work, we address this limitation by introducing Infinity-MM, a large-scale multimodal instruction dataset with 40 million samples, enhanced through rigorous quality filtering and deduplication. We also propose a synthetic instruction generation method based on open-source VLMs, using detailed image annotations and diverse question generation. Using this data, we trained a 2-billion-parameter VLM, Aquila-VL-2B, achieving state-of-the-art (SOTA) performance for models of similar scale. This demonstrates that expanding instruction data and generating synthetic data can significantly improve the performance of open-source models.
CCI3.0-HQ: a large-scale Chinese dataset of high quality designed for pre-training large language models
Oct 24, 2024We present CCI3.0-HQ (https://huggingface.co/datasets/BAAI/CCI3-HQ), a high-quality 500GB subset of the Chinese Corpora Internet 3.0 (CCI3.0)(https://huggingface.co/datasets/BAAI/CCI3-Data), developed using a novel two-stage hybrid filtering pipeline that significantly enhances data quality. To evaluate its effectiveness, we trained a 0.5B parameter model from scratch on 100B tokens across various datasets, achieving superior performance on 10 benchmarks in a zero-shot setting compared to CCI3.0, SkyPile, and WanjuanV1. The high-quality filtering process effectively distills the capabilities of the Qwen2-72B-instruct model into a compact 0.5B model, attaining optimal F1 scores for Chinese web data classification. We believe this open-access dataset will facilitate broader access to high-quality language models.
ReTok: Replacing Tokenizer to Enhance Representation Efficiency in Large Language Model
Oct 06, 2024Tokenizer is an essential component for large language models (LLMs), and a tokenizer with a high compression rate can improve the model's representation and processing efficiency. However, the tokenizer cannot ensure high compression rate in all scenarios, and an increase in the average input and output lengths will increases the training and inference costs of the model. Therefore, it is crucial to find ways to improve the model's efficiency with minimal cost while maintaining the model's performance. In this work, we propose a method to improve model representation and processing efficiency by replacing the tokenizers of LLMs. We propose replacing and reinitializing the parameters of the model's input and output layers with the parameters of the original model, and training these parameters while keeping other parameters fixed. We conducted experiments on different LLMs, and the results show that our method can maintain the performance of the model after replacing the tokenizer, while significantly improving the decoding speed for long texts.
Aquila2 Technical Report
Aug 14, 2024This paper introduces the Aquila2 series, which comprises a wide range of bilingual models with parameter sizes of 7, 34, and 70 billion. These models are trained based on an innovative framework named HeuriMentor (HM), which offers real-time insights into model convergence and enhances the training process and data management. The HM System, comprising the Adaptive Training Engine (ATE), Training State Monitor (TSM), and Data Management Unit (DMU), allows for precise monitoring of the model's training progress and enables efficient optimization of data distribution, thereby enhancing training effectiveness. Extensive evaluations show that the Aquila2 model series performs comparably well on both English and Chinese benchmarks. Specifically, Aquila2-34B demonstrates only a slight decrease in performance when quantized to Int4. Furthermore, we have made our training code (https://github.com/FlagOpen/FlagScale) and model weights (https://github.com/FlagAI-Open/Aquila2) publicly available to support ongoing research and the development of applications.
AquilaMoE: Efficient Training for MoE Models with Scale-Up and Scale-Out Strategies
Aug 13, 2024In recent years, with the rapid application of large language models across various fields, the scale of these models has gradually increased, and the resources required for their pre-training have grown exponentially. Training an LLM from scratch will cost a lot of computation resources while scaling up from a smaller model is a more efficient approach and has thus attracted significant attention. In this paper, we present AquilaMoE, a cutting-edge bilingual 8*16B Mixture of Experts (MoE) language model that has 8 experts with 16 billion parameters each and is developed using an innovative training methodology called EfficientScale. This approach optimizes performance while minimizing data requirements through a two-stage process. The first stage, termed Scale-Up, initializes the larger model with weights from a pre-trained smaller model, enabling substantial knowledge transfer and continuous pretraining with significantly less data. The second stage, Scale-Out, uses a pre-trained dense model to initialize the MoE experts, further enhancing knowledge transfer and performance. Extensive validation experiments on 1.8B and 7B models compared various initialization schemes, achieving models that maintain and reduce loss during continuous pretraining. Utilizing the optimal scheme, we successfully trained a 16B model and subsequently the 8*16B AquilaMoE model, demonstrating significant improvements in performance and training efficiency.
Addressing the Length Bias Problem in Document-Level Neural Machine Translation
Nov 20, 2023Document-level neural machine translation (DNMT) has shown promising results by incorporating more context information. However, this approach also introduces a length bias problem, whereby DNMT suffers from significant translation quality degradation when decoding documents that are much shorter or longer than the maximum sequence length during training. %i.e., the length bias problem. To solve the length bias problem, we propose to improve the DNMT model in training method, attention mechanism, and decoding strategy. Firstly, we propose to sample the training data dynamically to ensure a more uniform distribution across different sequence lengths. Then, we introduce a length-normalized attention mechanism to aid the model in focusing on target information, mitigating the issue of attention divergence when processing longer sequences. Lastly, we propose a sliding window strategy during decoding that integrates as much context information as possible without exceeding the maximum sequence length. The experimental results indicate that our method can bring significant improvements on several open datasets, and further analysis shows that our method can significantly alleviate the length bias problem.