 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Hallucination in Financial Retrieval-Augmented Generation via Fine-Grained Knowledge Verification
Feb 05, 2026In financial Retrieval-Augmented Generation (RAG) systems, models frequently rely on retrieved documents to generate accurate responses due to the time-sensitive nature of the financial domain. While retrieved documents help address knowledge gaps, model-generated responses still suffer from hallucinations that contradict the retrieved information. To mitigate this inconsistency, we propose a Reinforcement Learning framework enhanced with Fine-grained Knowledge Verification (RLFKV). Our method decomposes financial responses into atomic knowledge units and assesses the correctness of each unit to compute the fine-grained faithful reward. This reward offers more precise optimization signals, thereby improving alignment with the retrieved documents. Additionally, to prevent reward hacking (e.g., overly concise replies), we incorporate an informativeness reward that encourages the policy model to retain at least as many knowledge units as the base model. Experiments conducted on the public Financial Data Description (FDD) task and our newly proposed FDD-ANT dataset demonstrate consistent improvements, confirming the effectiveness of our approach.
Aquila2 Technical Report
Aug 14, 2024This paper introduces the Aquila2 series, which comprises a wide range of bilingual models with parameter sizes of 7, 34, and 70 billion. These models are trained based on an innovative framework named HeuriMentor (HM), which offers real-time insights into model convergence and enhances the training process and data management. The HM System, comprising the Adaptive Training Engine (ATE), Training State Monitor (TSM), and Data Management Unit (DMU), allows for precise monitoring of the model's training progress and enables efficient optimization of data distribution, thereby enhancing training effectiveness. Extensive evaluations show that the Aquila2 model series performs comparably well on both English and Chinese benchmarks. Specifically, Aquila2-34B demonstrates only a slight decrease in performance when quantized to Int4. Furthermore, we have made our training code (https://github.com/FlagOpen/FlagScale) and model weights (https://github.com/FlagAI-Open/Aquila2) publicly available to support ongoing research and the development of applications.
AquilaMoE: Efficient Training for MoE Models with Scale-Up and Scale-Out Strategies
Aug 13, 2024In recent years, with the rapid application of large language models across various fields, the scale of these models has gradually increased, and the resources required for their pre-training have grown exponentially. Training an LLM from scratch will cost a lot of computation resources while scaling up from a smaller model is a more efficient approach and has thus attracted significant attention. In this paper, we present AquilaMoE, a cutting-edge bilingual 8*16B Mixture of Experts (MoE) language model that has 8 experts with 16 billion parameters each and is developed using an innovative training methodology called EfficientScale. This approach optimizes performance while minimizing data requirements through a two-stage process. The first stage, termed Scale-Up, initializes the larger model with weights from a pre-trained smaller model, enabling substantial knowledge transfer and continuous pretraining with significantly less data. The second stage, Scale-Out, uses a pre-trained dense model to initialize the MoE experts, further enhancing knowledge transfer and performance. Extensive validation experiments on 1.8B and 7B models compared various initialization schemes, achieving models that maintain and reduce loss during continuous pretraining. Utilizing the optimal scheme, we successfully trained a 16B model and subsequently the 8*16B AquilaMoE model, demonstrating significant improvements in performance and training efficiency.
CMMU: A Benchmark for Chinese Multi-modal Multi-type Question Understanding and Reasoning
Jan 26, 2024

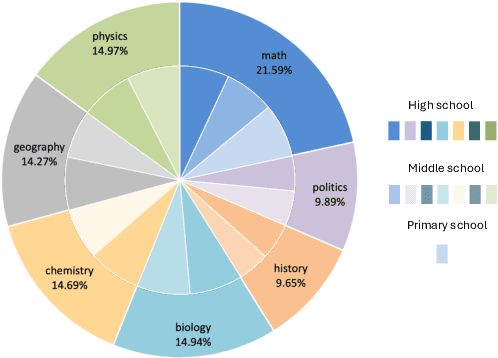

Multi-modal large language models(MLLMs) have achieved remarkable progress and demonstrated powerful knowledge comprehension and reasoning abilities. However, the mastery of domain-specific knowledge, which is essential for evaluating the intelligence of MLLMs, continues to be a challenge. Current multi-modal benchmarks for domain-specific knowledge concentrate on multiple-choice questions and are predominantly available in English, which imposes limitations on the comprehensiveness of the evaluation. To this end, we introduce CMMU, a novel benchmark for multi-modal and multi-type question understanding and reasoning in Chinese. CMMU consists of 3,603 questions in 7 subjects, covering knowledge from primary to high school. The questions can be categorized into 3 types: multiple-choice, multiple-response, and fill-in-the-blank, bringing greater challenges to MLLMs. In addition, we propose a rigorous evaluation strategy called ShiftCheck for assessing multiple-choice questions. The strategy aims to reduce position bias, minimize the influence of randomness on correctness, and perform a quantitative analysis of position bias. We evaluate seven open-source MLLMs along with GPT4-V, Gemini-Pro, and Qwen-VL-Plus. The results demonstrate that CMMU poses a significant challenge to the recent MLLMs.
AltDiffusion: A Multilingual Text-to-Image Diffusion Model
Aug 23, 2023Large Text-to-Image(T2I) diffusion models have shown a remarkable capability to produce photorealistic and diverse images based on text inputs. However, existing works only support limited language input, e.g., English, Chinese, and Japanese, leaving users beyond these languages underserved and blocking the global expansion of T2I models. Therefore, this paper presents AltDiffusion, a novel multilingual T2I diffusion model that supports eighteen different languages. Specifically, we first train a multilingual text encoder based on the knowledge distillation. Then we plug it into a pretrained English-only diffusion model and train the model with a two-stage schema to enhance the multilingual capability, including concept alignment and quality improvement stage on a large-scale multilingual dataset. Furthermore, we introduce a new benchmark, which includes Multilingual-General-18(MG-18) and Multilingual-Cultural-18(MC-18) datasets, to evaluate the capabilities of T2I diffusion models for generating high-quality images and capturing culture-specific concepts in different languages. Experimental results on both MG-18 and MC-18 demonstrate that AltDiffusion outperforms current state-of-the-art T2I models, e.g., Stable Diffusion in multilingual understanding, especially with respect to culture-specific concepts, while still having comparable capability for generating high-quality images. All source code and checkpoints could be found in https://github.com/superhero-7/AltDiffuson.