 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Much Orthogonalization Does Muon Need?
May 29, 2026Muon optimizers improve neural-network training by replacing ill-conditioned momentum updates with approximately semi-orthogonal updates. This motivates a practical question: how much orthogonalization does Muon actually require? We study this question using a relaxed cubic Newton--Schulz schedule derived directly for Muon's low precision singular value band. The resulting five-step cubic construction uses ten dominant matrix multiplications, compared with fifteen for five quintic Newton--Schulz iterations. The cubic schedule is not intended as a more accurate polar solver; instead, it is a principled low-cost variant that lets us probe the relation between polar accuracy, spectral shaping, and training quality. Across synthetic diagnostics, NanoGPT ablations, and training experiments on hybrid MoE/Mamba models, we find that training quality is not governed monotonically by polar-decomposition accuracy: truncated Polar Express, Muon-Jordan, cubic Newton--Schulz, and an explicit FP32 SVD polar factor can reach nearly indistinguishable final loss on GPT-2 Small, and cubic5 matches the Muon-Jordan quintic update within about $10^{-3}$ validation loss on hybrid MoE/Mamba models with one billion to four billion parameters. These results support cubic5 as a practical low-cost Muon orthogonalization variant, with empirical evidence of training-quality parity in the settings tested.
On Multi-Step Theorem Prediction via Non-Parametric Structural Priors
Mar 05, 2026Multi-step theorem prediction is a central challenge in automated reasoning. Existing neural-symbolic approaches rely heavily on supervised parametric models, which exhibit limited generalization to evolving theorem libraries. In this work, we explore training-free theorem prediction through the lens of in-context learning (ICL). We identify a critical scalability bottleneck, termed Structural Drift: as reasoning depth increases, the performance of vanilla ICL degrades sharply, often collapsing to near zero. We attribute this failure to the LLM's inability to recover latent topological dependencies, leading to unstructured exploration. To address this issue, we propose Theorem Precedence Graphs, which encode temporal dependencies from historical solution traces as directed graphs, and impose explicit topological constraints that effectively prune the search space during inference. Coupled with retrieval-augmented graph construction and a stepwise symbolic executor, our approach enables LLMs to act as structured planners without any gradient-based optimization. Experiments on the FormalGeo7k benchmark show that our method achieves 89.29% accuracy, substantially outperforming ICL baselines and matching state-of-the-art supervised models. These results indicate that explicit structural priors offer a promising direction for scaling LLM-based symbolic reasoning.
Geo-Code: A Code Framework for Reverse Code Generation from Geometric Images Based on Two-Stage Multi-Agent Evolution
Feb 08, 2026Program code serves as a bridge linking vision and logic, providing a feasible supervisory approach for enhancing the multimodal reasoning capability of large models through geometric operations such as auxiliary line construction and perspective transformation. Nevertheless, current inverse graphics methods face tremendous challenges in accurately reconstructing complex geometric details, which often results in the loss of key geometric constraints or structural distortion. To address this bottleneck, we propose Geo-coder -- the first inverse programming framework for geometric images based on a multi-agent system. Our method innovatively decouples the process into geometric modeling via pixel-wise anchoring and metric-driven code evolution: Stage 1 leverages the complementary advantages of visual operators and large models to achieve precise capture of pixel coordinates and visual attributes; Stage 2 introduces a synthesis-rendering-validation closed loop, where bidirectional visual feedback drives the self-correction of code. Extensive experiments demonstrate that Geo-coder achieves a substantial lead in both geometric reconstruction accuracy and visual consistency. Notably, by effectively preserving the core geometric semantics, the images reconstructed with our method exhibit equivalent performance to the original ones in multimodal reasoning tasks, which fully validates the robustness of the framework. Finally, to further reduce research costs, we have open-sourced the Geo-coder dataset constructed on the GeoCode framework, which contains more than 1,500 samples. On this basis, we have also open-sourced the GeocodeLM model, laying a solid data and model foundation for subsequent research in this field.
SketchJudge: A Diagnostic Benchmark for Grading Hand-drawn Diagrams with Multimodal Large Language Models
Jan 11, 2026While Multimodal Large Language Models (MLLMs) have achieved remarkable progress in visual understanding, they often struggle when faced with the unstructured and ambiguous nature of human-generated sketches. This limitation is particularly pronounced in the underexplored task of visual grading, where models should not only solve a problem but also diagnose errors in hand-drawn diagrams. Such diagnostic capabilities depend on complex structural, semantic, and metacognitive reasoning. To bridge this gap, we introduce SketchJudge, a novel benchmark tailored for evaluating MLLMs as graders of hand-drawn STEM diagrams. SketchJudge encompasses 1,015 hand-drawn student responses across four domains: geometry, physics, charts, and flowcharts, featuring diverse stylistic variations and distinct error types. Evaluations on SketchJudge demonstrate that even advanced MLLMs lag significantly behind humans, validating the benchmark's effectiveness in exposing the fragility of current vision-language alignment in symbolic and noisy contexts. All data, code, and evaluation scripts are publicly available at https://github.com/yuhangsu82/SketchJudge.
Physics-Informed Video Flare Synthesis and Removal Leveraging Motion Independence between Flare and Scene
Dec 12, 2025Lens flare is a degradation phenomenon caused by strong light sources. Existing researches on flare removal have mainly focused on images, while the spatiotemporal characteristics of video flare remain largely unexplored. Video flare synthesis and removal pose significantly greater challenges than in image, owing to the complex and mutually independent motion of flare, light sources, and scene content. This motion independence further affects restoration performance, often resulting in flicker and artifacts. To address this issue, we propose a physics-informed dynamic flare synthesis pipeline, which simulates light source motion using optical flow and models the temporal behaviors of both scattering and reflective flares. Meanwhile, we design a video flare removal network that employs an attention module to spatially suppress flare regions and incorporates a Mamba-based temporal modeling component to capture long range spatio-temporal dependencies. This motion-independent spatiotemporal representation effectively eliminates the need for multi-frame alignment, alleviating temporal aliasing between flares and scene content and thereby improving video flare removal performance. Building upon this, we construct the first video flare dataset to comprehensively evaluate our method, which includes a large set of synthetic paired videos and additional real-world videos collected from the Internet to assess generalization capability. Extensive experiments demonstrate that our method consistently outperforms existing video-based restoration and image-based flare removal methods on both real and synthetic videos, effectively removing dynamic flares while preserving light source integrity and maintaining spatiotemporal consistency of scene.
GeoLoom: High-quality Geometric Diagram Generation from Textual Input
Dec 09, 2025High-quality geometric diagram generation presents both a challenge and an opportunity: it demands strict spatial accuracy while offering well-defined constraints to guide generation. Inspired by recent advances in geometry problem solving that employ formal languages and symbolic solvers for enhanced correctness and interpretability, we propose GeoLoom, a novel framework for text-to-diagram generation in geometric domains. GeoLoom comprises two core components: an autoformalization module that translates natural language into a specifically designed generation-oriented formal language GeoLingua, and a coordinate solver that maps formal constraints to precise coordinates using the efficient Monte Carlo optimization. To support this framework, we introduce GeoNF, a dataset aligning natural language geometric descriptions with formal GeoLingua descriptions. We further propose a constraint-based evaluation metric that quantifies structural deviation, offering mathematically grounded supervision for iterative refinement. Empirical results demonstrate that GeoLoom significantly outperforms state-of-the-art baselines in structural fidelity, providing a principled foundation for interpretable and scalable diagram generation.
NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model
Aug 21, 2025



We introduce Nemotron-Nano-9B-v2, a hybrid Mamba-Transformer language model designed to increase throughput for reasoning workloads while achieving state-of-the-art accuracy compared to similarly-sized models. Nemotron-Nano-9B-v2 builds on the Nemotron-H architecture, in which the majority of the self-attention layers in the common Transformer architecture are replaced with Mamba-2 layers, to achieve improved inference speed when generating the long thinking traces needed for reasoning. We create Nemotron-Nano-9B-v2 by first pre-training a 12-billion-parameter model (Nemotron-Nano-12B-v2-Base) on 20 trillion tokens using an FP8 training recipe. After aligning Nemotron-Nano-12B-v2-Base, we employ the Minitron strategy to compress and distill the model with the goal of enabling inference on up to 128k tokens on a single NVIDIA A10G GPU (22GiB of memory, bfloat16 precision). Compared to existing similarly-sized models (e.g., Qwen3-8B), we show that Nemotron-Nano-9B-v2 achieves on-par or better accuracy on reasoning benchmarks while achieving up to 6x higher inference throughput in reasoning settings like 8k input and 16k output tokens. We are releasing Nemotron-Nano-9B-v2, Nemotron-Nano12B-v2-Base, and Nemotron-Nano-9B-v2-Base checkpoints along with the majority of our pre- and post-training datasets on Hugging Face.
Revealing Latent Information: A Physics-inspired Self-supervised Pre-training Framework for Noisy and Sparse Events
Aug 07, 2025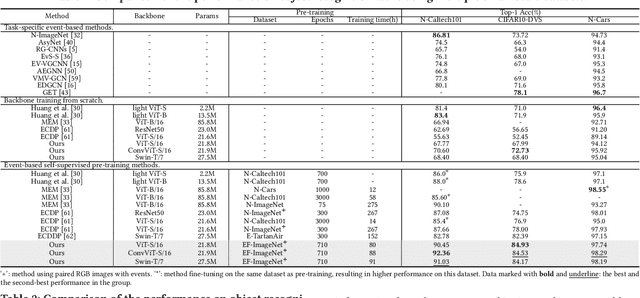

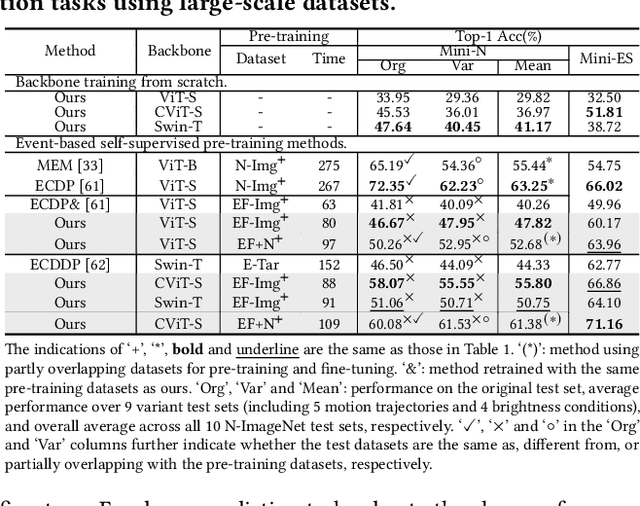
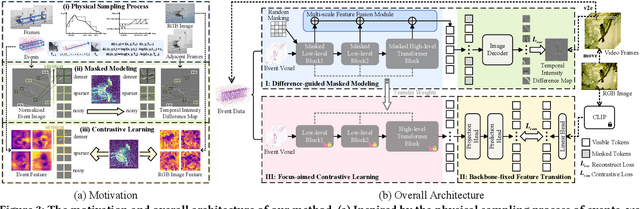
Event camera, a novel neuromorphic vision sensor, records data with high temporal resolution and wide dynamic range, offering new possibilities for accurate visual representation in challenging scenarios. However, event data is inherently sparse and noisy, mainly reflecting brightness changes, which complicates effective feature extraction. To address this, we propose a self-supervised pre-training framework to fully reveal latent information in event data, including edge information and texture cues. Our framework consists of three stages: Difference-guided Masked Modeling, inspired by the event physical sampling process, reconstructs temporal intensity difference maps to extract enhanced information from raw event data. Backbone-fixed Feature Transition contrasts event and image features without updating the backbone to preserve representations learned from masked modeling and stabilizing their effect on contrastive learning. Focus-aimed Contrastive Learning updates the entire model to improve semantic discrimination by focusing on high-value regions. Extensive experiments show our framework is robust and consistently outperforms state-of-the-art methods on various downstream tasks, including object recognition, semantic segmentation, and optical flow estimation. The code and dataset are available at https://github.com/BIT-Vision/EventPretrain.
VisioMath: Benchmarking Figure-based Mathematical Reasoning in LMMs
Jun 07, 2025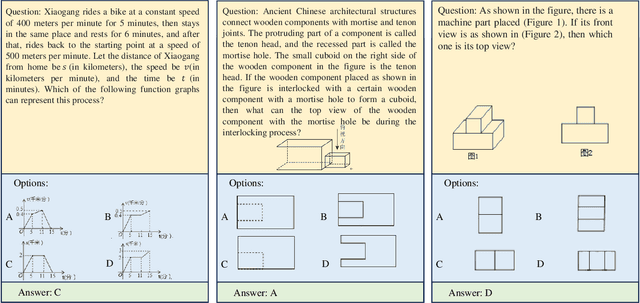
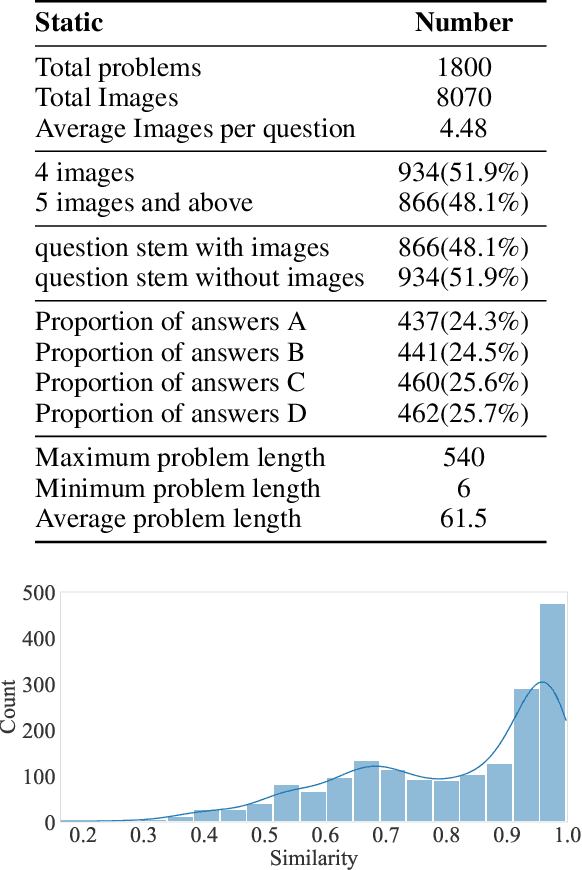
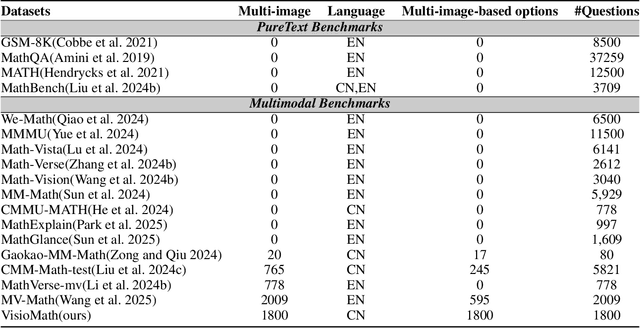
Large Multimodal Models (LMMs) have demonstrated remarkable problem-solving capabilities across various domains. However, their ability to perform mathematical reasoning when answer options are represented as images--an essential aspect of multi-image comprehension--remains underexplored. To bridge this gap, we introduce VisioMath, a benchmark designed to evaluate mathematical reasoning in multimodal contexts involving image-based answer choices. VisioMath comprises 8,070 images and 1,800 multiple-choice questions, where each answer option is an image, presenting unique challenges to existing LMMs. To the best of our knowledge, VisioMath is the first dataset specifically tailored for mathematical reasoning in image-based-option scenarios, where fine-grained distinctions between answer choices are critical for accurate problem-solving. We systematically evaluate state-of-the-art LMMs on VisioMath and find that even the most advanced models struggle with this task. Notably, GPT-4o achieves only 45.9% accuracy, underscoring the limitations of current models in reasoning over visually similar answer choices. By addressing a crucial gap in existing benchmarks, VisioMath establishes a rigorous testbed for future research, driving advancements in multimodal reasoning.
PDE: Gene Effect Inspired Parameter Dynamic Evolution for Low-light Image Enhancement
May 14, 2025



Low-light image enhancement (LLIE) is a fundamental task in computational photography, aiming to improve illumination, reduce noise, and enhance image quality. While recent advancements focus on designing increasingly complex neural network models, we observe a peculiar phenomenon: resetting certain parameters to random values unexpectedly improves enhancement performance for some images. Drawing inspiration from biological genes, we term this phenomenon the gene effect. The gene effect limits enhancement performance, as even random parameters can sometimes outperform learned ones, preventing models from fully utilizing their capacity. In this paper, we investigate the reason and propose a solution. Based on our observations, we attribute the gene effect to static parameters, analogous to how fixed genetic configurations become maladaptive when environments change. Inspired by biological evolution, where adaptation to new environments relies on gene mutation and recombination, we propose parameter dynamic evolution (PDE) to adapt to different images and mitigate the gene effect. PDE employs a parameter orthogonal generation technique and the corresponding generated parameters to simulate gene recombination and gene mutation, separately. Experiments validate the effectiveness of our techniques. The code will be released to the public.