 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing Latent Information: A Physics-inspired Self-supervised Pre-training Framework for Noisy and Sparse Events
Aug 07, 2025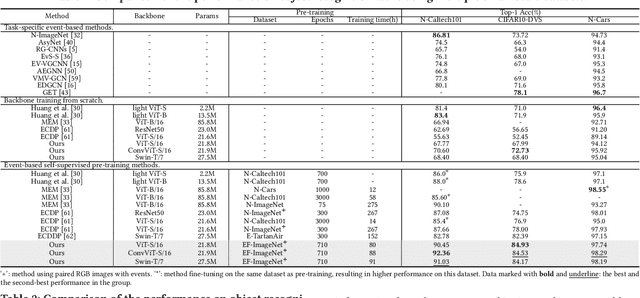

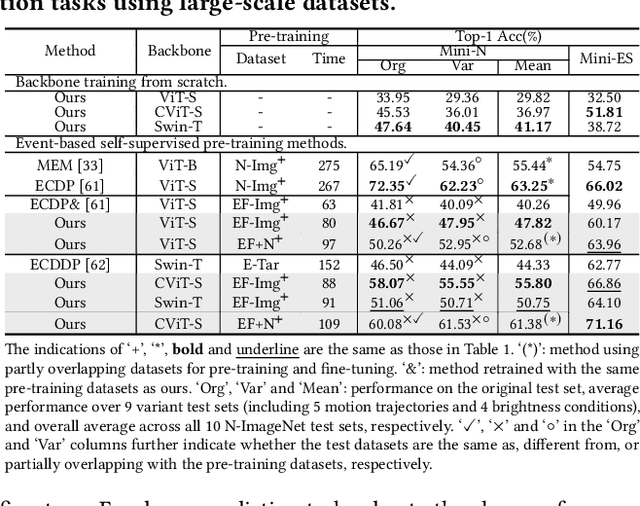
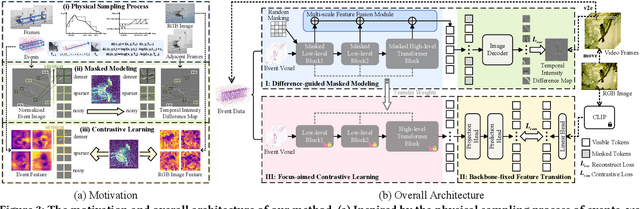
Event camera, a novel neuromorphic vision sensor, records data with high temporal resolution and wide dynamic range, offering new possibilities for accurate visual representation in challenging scenarios. However, event data is inherently sparse and noisy, mainly reflecting brightness changes, which complicates effective feature extraction. To address this, we propose a self-supervised pre-training framework to fully reveal latent information in event data, including edge information and texture cues. Our framework consists of three stages: Difference-guided Masked Modeling, inspired by the event physical sampling process, reconstructs temporal intensity difference maps to extract enhanced information from raw event data. Backbone-fixed Feature Transition contrasts event and image features without updating the backbone to preserve representations learned from masked modeling and stabilizing their effect on contrastive learning. Focus-aimed Contrastive Learning updates the entire model to improve semantic discrimination by focusing on high-value regions. Extensive experiments show our framework is robust and consistently outperforms state-of-the-art methods on various downstream tasks, including object recognition, semantic segmentation, and optical flow estimation. The code and dataset are available at https://github.com/BIT-Vision/EventPretrain.
PDE: Gene Effect Inspired Parameter Dynamic Evolution for Low-light Image Enhancement
May 14, 2025



Low-light image enhancement (LLIE) is a fundamental task in computational photography, aiming to improve illumination, reduce noise, and enhance image quality. While recent advancements focus on designing increasingly complex neural network models, we observe a peculiar phenomenon: resetting certain parameters to random values unexpectedly improves enhancement performance for some images. Drawing inspiration from biological genes, we term this phenomenon the gene effect. The gene effect limits enhancement performance, as even random parameters can sometimes outperform learned ones, preventing models from fully utilizing their capacity. In this paper, we investigate the reason and propose a solution. Based on our observations, we attribute the gene effect to static parameters, analogous to how fixed genetic configurations become maladaptive when environments change. Inspired by biological evolution, where adaptation to new environments relies on gene mutation and recombination, we propose parameter dynamic evolution (PDE) to adapt to different images and mitigate the gene effect. PDE employs a parameter orthogonal generation technique and the corresponding generated parameters to simulate gene recombination and gene mutation, separately. Experiments validate the effectiveness of our techniques. The code will be released to the public.
APG-MOS: Auditory Perception Guided-MOS Predictor for Synthetic Speech
Apr 29, 2025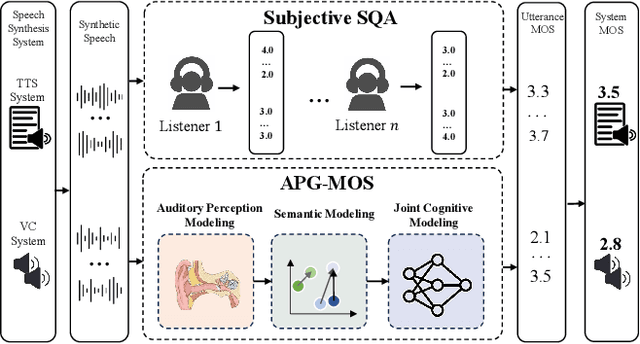
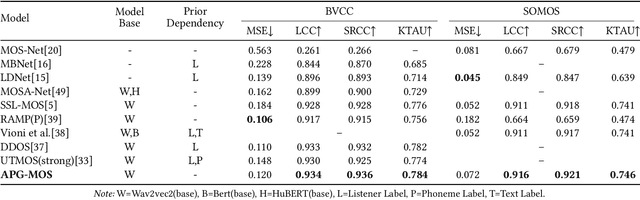
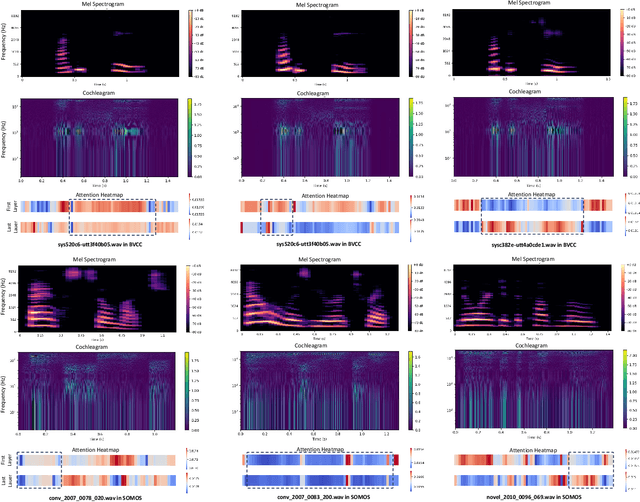
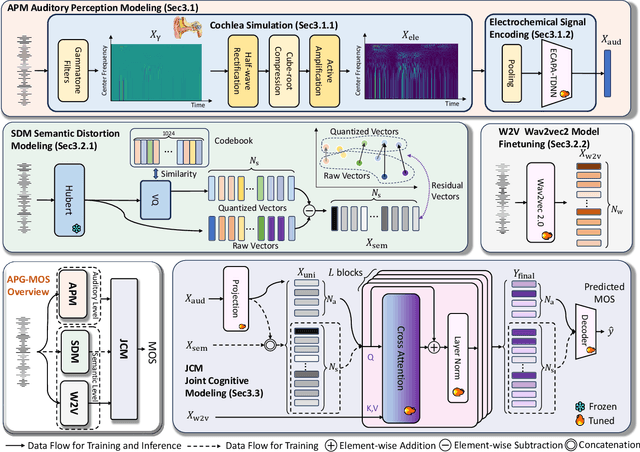
Automatic speech quality assessment aims to quantify subjective human perception of speech through computational models to reduce the need for labor-consuming manual evaluations. While models based on deep learning have achieved progress in predicting mean opinion scores (MOS) to assess synthetic speech, the neglect of fundamental auditory perception mechanisms limits consistency with human judgments. To address this issue, we propose an auditory perception guided-MOS prediction model (APG-MOS) that synergistically integrates auditory modeling with semantic analysis to enhance consistency with human judgments. Specifically, we first design a perceptual module, grounded in biological auditory mechanisms, to simulate cochlear functions, which encodes acoustic signals into biologically aligned electrochemical representations. Secondly, we propose a residual vector quantization (RVQ)-based semantic distortion modeling method to quantify the degradation of speech quality at the semantic level. Finally, we design a residual cross-attention architecture, coupled with a progressive learning strategy, to enable multimodal fusion of encoded electrochemical signals and semantic representations. Experiments demonstrate that APG-MOS achieves superior performance on two primary benchmarks. Our code and checkpoint will be available on a public repository upon publication.
Complementary Advantages: Exploiting Cross-Field Frequency Correlation for NIR-Assisted Image Denoising
Dec 21, 2024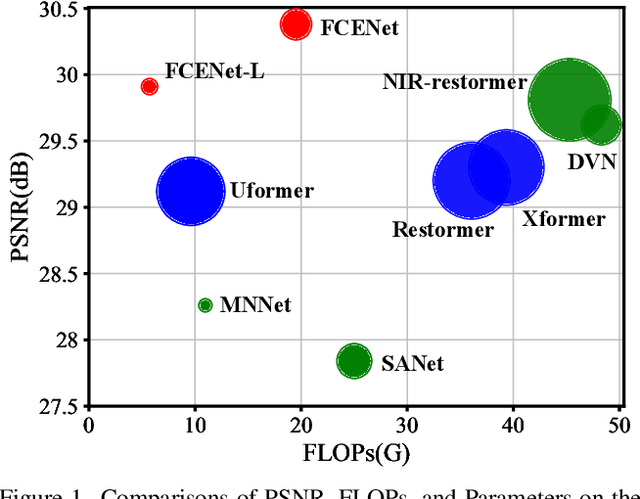
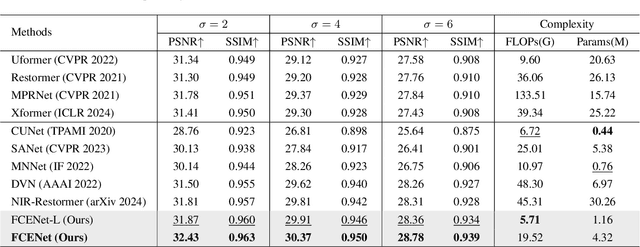

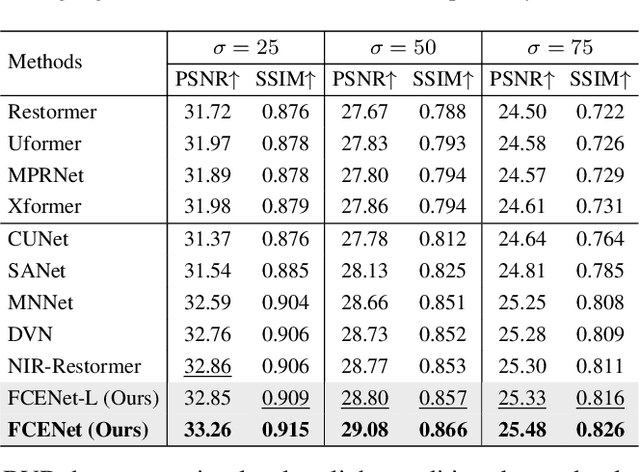
Existing single-image denoising algorithms often struggle to restore details when dealing with complex noisy images. The introduction of near-infrared (NIR) images offers new possibilities for RGB image denoising. However, due to the inconsistency between NIR and RGB images, the existing works still struggle to balance the contributions of two fields in the process of image fusion. In response to this, in this paper, we develop a cross-field Frequency Correlation Exploiting Network (FCENet) for NIR-assisted image denoising. We first propose the frequency correlation prior based on an in-depth statistical frequency analysis of NIR-RGB image pairs. The prior reveals the complementary correlation of NIR and RGB images in the frequency domain. Leveraging frequency correlation prior, we then establish a frequency learning framework composed of Frequency Dynamic Selection Mechanism (FDSM) and Frequency Exhaustive Fusion Mechanism (FEFM). FDSM dynamically selects complementary information from NIR and RGB images in the frequency domain, and FEFM strengthens the control of common and differential features during the fusion of NIR and RGB features. Extensive experiments on simulated and real data validate that our method outperforms various state-of-the-art methods in terms of image quality and computational efficiency. The code will be released to the public.
Rethinking Model Redundancy for Low-light Image Enhancement
Dec 21, 2024Low-light image enhancement (LLIE) is a fundamental task in computational photography, aiming to improve illumination, reduce noise, and enhance the image quality of low-light images. While recent advancements primarily focus on customizing complex neural network models, we have observed significant redundancy in these models, limiting further performance improvement. In this paper, we investigate and rethink the model redundancy for LLIE, identifying parameter harmfulness and parameter uselessness. Inspired by the rethinking, we propose two innovative techniques to mitigate model redundancy while improving the LLIE performance: Attention Dynamic Reallocation (ADR) and Parameter Orthogonal Generation (POG). ADR dynamically reallocates appropriate attention based on original attention, thereby mitigating parameter harmfulness. POG learns orthogonal basis embeddings of parameters and prevents degradation to static parameters, thereby mitigating parameter uselessness. Experiments validate the effectiveness of our techniques. We will release the code to the public.
Positive2Negative: Breaking the Information-Lossy Barrier in Self-Supervised Single Image Denoising
Dec 21, 2024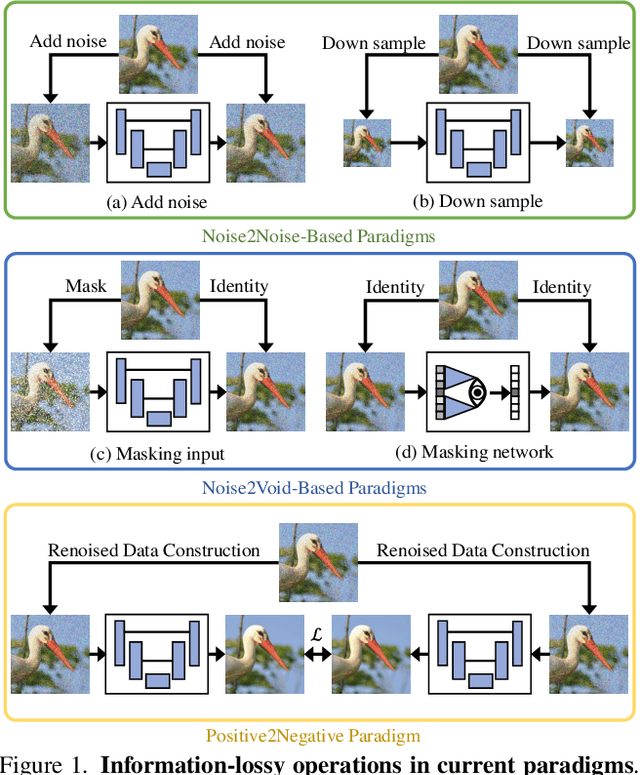
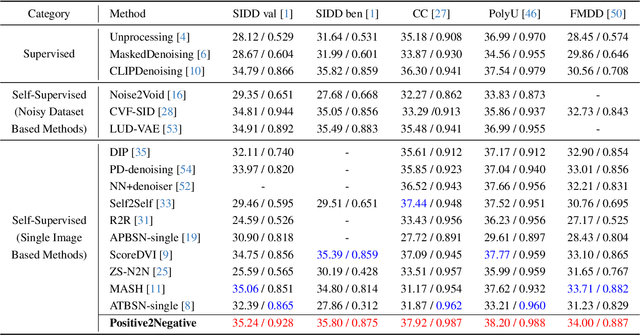


Image denoising enhances image quality, serving as a foundational technique across various computational photography applications. The obstacle to clean image acquisition in real scenarios necessitates the development of self-supervised image denoising methods only depending on noisy images, especially a single noisy image. Existing self-supervised image denoising paradigms (Noise2Noise and Noise2Void) rely heavily on information-lossy operations, such as downsampling and masking, culminating in low quality denoising performance. In this paper, we propose a novel self-supervised single image denoising paradigm, Positive2Negative, to break the information-lossy barrier. Our paradigm involves two key steps: Renoised Data Construction (RDC) and Denoised Consistency Supervision (DCS). RDC renoises the predicted denoised image by the predicted noise to construct multiple noisy images, preserving all the information of the original image. DCS ensures consistency across the multiple denoised images, supervising the network to learn robust denoising. Our Positive2Negative paradigm achieves state-of-the-art performance in self-supervised single image denoising with significant speed improvements. The code will be released to the public.
Unifying Event-based Flow, Stereo and Depth Estimation via Feature Similarity Matching
Jul 31, 2024
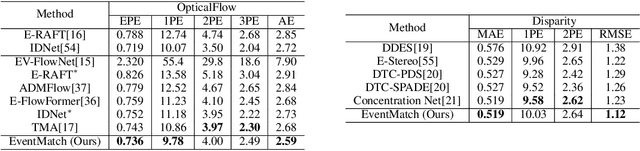


As an emerging vision sensor, the event camera has gained popularity in various vision tasks such as optical flow estimation, stereo matching, and depth estimation due to its high-speed, sparse, and asynchronous event streams. Unlike traditional approaches that use specialized architectures for each specific task, we propose a unified framework, EventMatch, that reformulates these tasks as an event-based dense correspondence matching problem, allowing them to be solved with a single model by directly comparing feature similarities. By utilizing a shared feature similarities module, which integrates knowledge from other event flows via temporal or spatial interactions, and distinct task heads, our network can concurrently perform optical flow estimation from temporal inputs (e.g., two segments of event streams in the temporal domain) and stereo matching from spatial inputs (e.g., two segments of event streams from different viewpoints in the spatial domain). Moreover, we further demonstrate that our unified model inherently supports cross-task transfer since the architecture and parameters are shared across tasks. Without the need for retraining on each task, our model can effectively handle both optical flow and disparity estimation simultaneously. The experiment conducted on the DSEC benchmark demonstrates that our model exhibits superior performance in both optical flow and disparity estimation tasks, outperforming existing state-of-the-art methods. Our unified approach not only advances event-based models but also opens new possibilities for cross-task transfer and inter-task fusion in both spatial and temporal dimensions. Our code will be available later.
Temporal Residual Guided Diffusion Framework for Event-Driven Video Reconstruction
Jul 15, 2024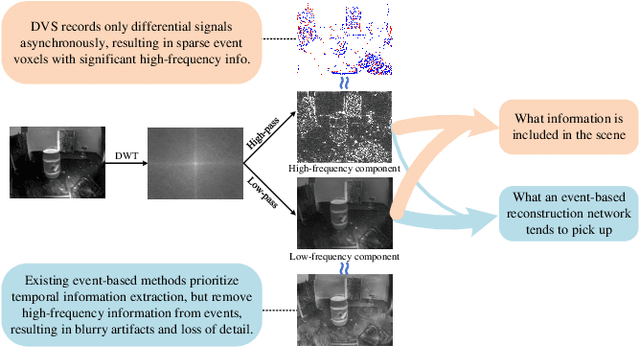
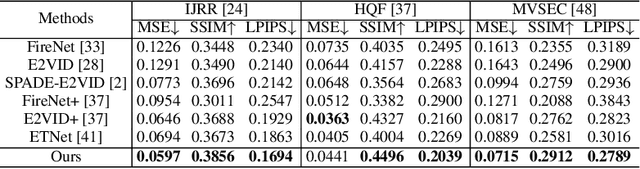
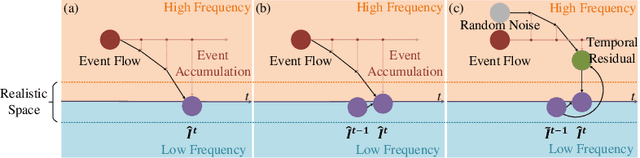
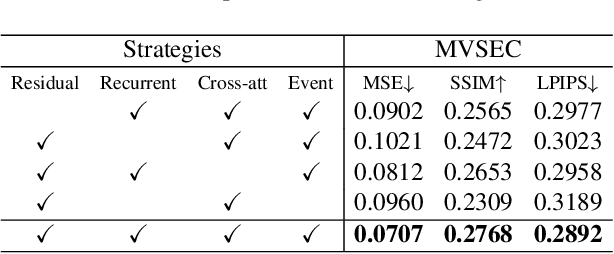
Event-based video reconstruction has garnered increasing attention due to its advantages, such as high dynamic range and rapid motion capture capabilities. However, current methods often prioritize the extraction of temporal information from continuous event flow, leading to an overemphasis on low-frequency texture features in the scene, resulting in over-smoothing and blurry artifacts. Addressing this challenge necessitates the integration of conditional information, encompassing temporal features, low-frequency texture, and high-frequency events, to guide the Denoising Diffusion Probabilistic Model (DDPM) in producing accurate and natural outputs. To tackle this issue, we introduce a novel approach, the Temporal Residual Guided Diffusion Framework, which effectively leverages both temporal and frequency-based event priors. Our framework incorporates three key conditioning modules: a pre-trained low-frequency intensity estimation module, a temporal recurrent encoder module, and an attention-based high-frequency prior enhancement module. In order to capture temporal scene variations from the events at the current moment, we employ a temporal-domain residual image as the target for the diffusion model. Through the combination of these three conditioning paths and the temporal residual framework, our framework excels in reconstructing high-quality videos from event flow, mitigating issues such as artifacts and over-smoothing commonly observed in previous approaches. Extensive experiments conducted on multiple benchmark datasets validate the superior performance of our framework compared to prior event-based reconstruction methods.
Diffusion-Promoted HDR Video Reconstruction
Jun 12, 2024



High dynamic range (HDR) video reconstruction aims to generate HDR videos from low dynamic range (LDR) frames captured with alternating exposures. Most existing works solely rely on the regression-based paradigm, leading to adverse effects such as ghosting artifacts and missing details in saturated regions. In this paper, we propose a diffusion-promoted method for HDR video reconstruction, termed HDR-V-Diff, which incorporates a diffusion model to capture the HDR distribution. As such, HDR-V-Diff can reconstruct HDR videos with realistic details while alleviating ghosting artifacts. However, the direct introduction of video diffusion models would impose massive computational burden. Instead, to alleviate this burden, we first propose an HDR Latent Diffusion Model (HDR-LDM) to learn the distribution prior of single HDR frames. Specifically, HDR-LDM incorporates a tonemapping strategy to compress HDR frames into the latent space and a novel exposure embedding to aggregate the exposure information into the diffusion process. We then propose a Temporal-Consistent Alignment Module (TCAM) to learn the temporal information as a complement for HDR-LDM, which conducts coarse-to-fine feature alignment at different scales among video frames. Finally, we design a Zero-Init Cross-Attention (ZiCA) mechanism to effectively integrate the learned distribution prior and temporal information for generating HDR frames. Extensive experiments validate that HDR-V-Diff achieves state-of-the-art results on several representative datasets.
Exploiting Frequency Correlation for Hyperspectral Image Reconstruction
Jun 02, 2024Deep priors have emerged as potent methods in hyperspectral image (HSI) reconstruction. While most methods emphasize space-domain learning using image space priors like non-local similarity, frequency-domain learning using image frequency priors remains neglected, limiting the reconstruction capability of networks. In this paper, we first propose a Hyperspectral Frequency Correlation (HFC) prior rooted in in-depth statistical frequency analyses of existent HSI datasets. Leveraging the HFC prior, we subsequently establish the frequency domain learning composed of a Spectral-wise self-Attention of Frequency (SAF) and a Spectral-spatial Interaction of Frequency (SIF) targeting low-frequency and high-frequency components, respectively. The outputs of SAF and SIF are adaptively merged by a learnable gating filter, thus achieving a thorough exploitation of image frequency priors. Integrating the frequency domain learning and the existing space domain learning, we finally develop the Correlation-driven Mixing Domains Transformer (CMDT) for HSI reconstruction. Extensive experiments highlight that our method surpasses various state-of-the-art (SOTA) methods in reconstruction quality and computational efficiency.