 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQMamba: Post-Training Quantization for Vision State Space Models
Jan 23, 2025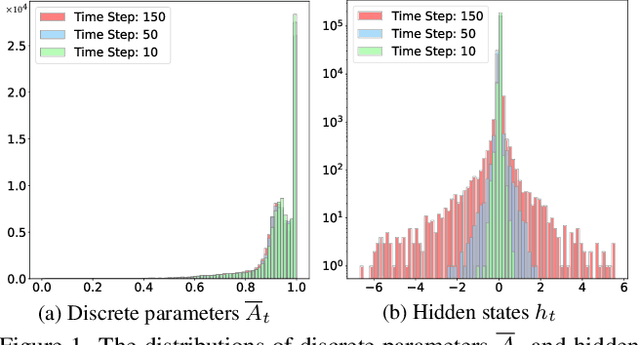

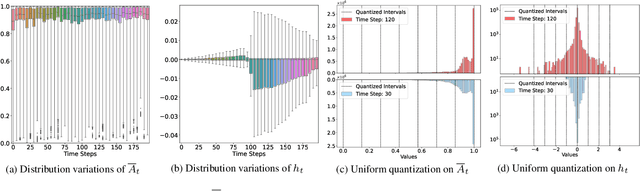

State Space Models (SSMs), as key components of Mamaba, have gained increasing attention for vision models recently, thanks to their efficient long sequence modeling capability. Given the computational cost of deploying SSMs on resource-limited edge devices, Post-Training Quantization (PTQ) is a technique with the potential for efficient deployment of SSMs. In this work, we propose QMamba, one of the first PTQ frameworks to our knowledge, designed for vision SSMs based on the analysis of the activation distributions in SSMs. We reveal that the distribution of discrete parameters exhibits long-tailed skewness and the distribution of the hidden state sequence exhibits highly dynamic variations. Correspondingly, we design Long-tailed Skewness Quantization (LtSQ) to quantize discrete parameters and Temporal Group Quantization (TGQ) to quantize hidden states, which reduces the quantization errors. Extensive experiments demonstrate that QMamba outperforms advanced PTQ methods on vision models across multiple model sizes and architectures. Notably, QMamba surpasses existing methods by 21.0% on ImageNet classification with 4-bit activations.
Event-boosted Deformable 3D Gaussians for Fast Dynamic Scene Reconstruction
Nov 25, 2024



3D Gaussian Splatting (3D-GS) enables real-time rendering but struggles with fast motion due to low temporal resolution of RGB cameras. To address this, we introduce the first approach combining event cameras, which capture high-temporal-resolution, continuous motion data, with deformable 3D-GS for fast dynamic scene reconstruction. We observe that threshold modeling for events plays a crucial role in achieving high-quality reconstruction. Therefore, we propose a GS-Threshold Joint Modeling (GTJM) strategy, creating a mutually reinforcing process that greatly improves both 3D reconstruction and threshold modeling. Moreover, we introduce a Dynamic-Static Decomposition (DSD) strategy that first identifies dynamic areas by exploiting the inability of static Gaussians to represent motions, then applies a buffer-based soft decomposition to separate dynamic and static areas. This strategy accelerates rendering by avoiding unnecessary deformation in static areas, and focuses on dynamic areas to enhance fidelity. Our approach achieves high-fidelity dynamic reconstruction at 156 FPS with a 400$\times$400 resolution on an RTX 3090 GPU.
Diffusion-Promoted HDR Video Reconstruction
Jun 12, 2024



High dynamic range (HDR) video reconstruction aims to generate HDR videos from low dynamic range (LDR) frames captured with alternating exposures. Most existing works solely rely on the regression-based paradigm, leading to adverse effects such as ghosting artifacts and missing details in saturated regions. In this paper, we propose a diffusion-promoted method for HDR video reconstruction, termed HDR-V-Diff, which incorporates a diffusion model to capture the HDR distribution. As such, HDR-V-Diff can reconstruct HDR videos with realistic details while alleviating ghosting artifacts. However, the direct introduction of video diffusion models would impose massive computational burden. Instead, to alleviate this burden, we first propose an HDR Latent Diffusion Model (HDR-LDM) to learn the distribution prior of single HDR frames. Specifically, HDR-LDM incorporates a tonemapping strategy to compress HDR frames into the latent space and a novel exposure embedding to aggregate the exposure information into the diffusion process. We then propose a Temporal-Consistent Alignment Module (TCAM) to learn the temporal information as a complement for HDR-LDM, which conducts coarse-to-fine feature alignment at different scales among video frames. Finally, we design a Zero-Init Cross-Attention (ZiCA) mechanism to effectively integrate the learned distribution prior and temporal information for generating HDR frames. Extensive experiments validate that HDR-V-Diff achieves state-of-the-art results on several representative datasets.
Neural Degradation Representation Learning for All-In-One Image Restoration
Oct 19, 2023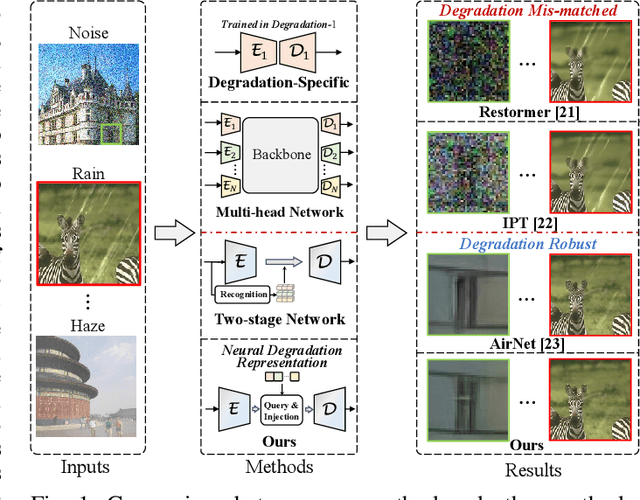
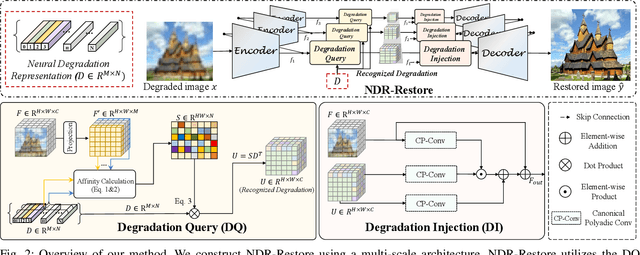
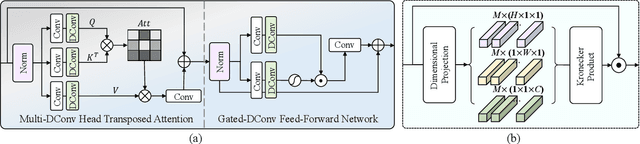
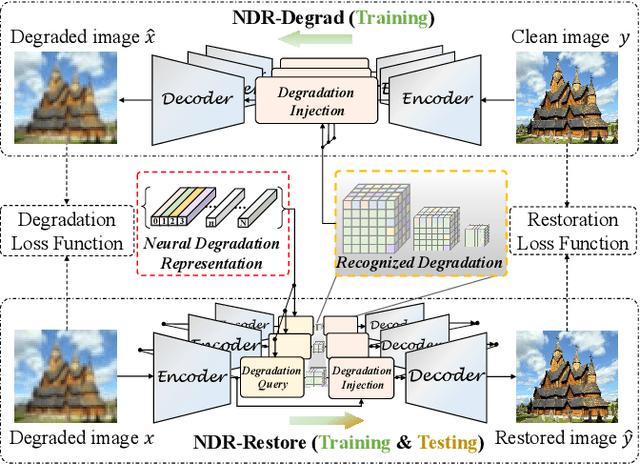
Existing methods have demonstrated effective performance on a single degradation type. In practical applications, however, the degradation is often unknown, and the mismatch between the model and the degradation will result in a severe performance drop. In this paper, we propose an all-in-one image restoration network that tackles multiple degradations. Due to the heterogeneous nature of different types of degradations, it is difficult to process multiple degradations in a single network. To this end, we propose to learn a neural degradation representation (NDR) that captures the underlying characteristics of various degradations. The learned NDR decomposes different types of degradations adaptively, similar to a neural dictionary that represents basic degradation components. Subsequently, we develop a degradation query module and a degradation injection module to effectively recognize and utilize the specific degradation based on NDR, enabling the all-in-one restoration ability for multiple degradations. Moreover, we propose a bidirectional optimization strategy to effectively drive NDR to learn the degradation representation by optimizing the degradation and restoration processes alternately. Comprehensive experiments on representative types of degradations (including noise, haze, rain, and downsampling) demonstrate the effectiveness and generalization capability of our method.
Mutual-Guided Dynamic Network for Image Fusion
Sep 01, 2023



Image fusion aims to generate a high-quality image from multiple images captured under varying conditions. The key problem of this task is to preserve complementary information while filtering out irrelevant information for the fused result. However, existing methods address this problem by leveraging static convolutional neural networks (CNNs), suffering two inherent limitations during feature extraction, i.e., being unable to handle spatial-variant contents and lacking guidance from multiple inputs. In this paper, we propose a novel mutual-guided dynamic network (MGDN) for image fusion, which allows for effective information utilization across different locations and inputs. Specifically, we design a mutual-guided dynamic filter (MGDF) for adaptive feature extraction, composed of a mutual-guided cross-attention (MGCA) module and a dynamic filter predictor, where the former incorporates additional guidance from different inputs and the latter generates spatial-variant kernels for different locations. In addition, we introduce a parallel feature fusion (PFF) module to effectively fuse local and global information of the extracted features. To further reduce the redundancy among the extracted features while simultaneously preserving their shared structural information, we devise a novel loss function that combines the minimization of normalized mutual information (NMI) with an estimated gradient mask. Experimental results on five benchmark datasets demonstrate that our proposed method outperforms existing methods on four image fusion tasks. The code and model are publicly available at: https://github.com/Guanys-dar/MGDN.
Generalized Lightness Adaptation with Channel Selective Normalization
Aug 26, 2023



Lightness adaptation is vital to the success of image processing to avoid unexpected visual deterioration, which covers multiple aspects, e.g., low-light image enhancement, image retouching, and inverse tone mapping. Existing methods typically work well on their trained lightness conditions but perform poorly in unknown ones due to their limited generalization ability. To address this limitation, we propose a novel generalized lightness adaptation algorithm that extends conventional normalization techniques through a channel filtering design, dubbed Channel Selective Normalization (CSNorm). The proposed CSNorm purposely normalizes the statistics of lightness-relevant channels and keeps other channels unchanged, so as to improve feature generalization and discrimination. To optimize CSNorm, we propose an alternating training strategy that effectively identifies lightness-relevant channels. The model equipped with our CSNorm only needs to be trained on one lightness condition and can be well generalized to unknown lightness conditions. Experimental results on multiple benchmark datasets demonstrate the effectiveness of CSNorm in enhancing the generalization ability for the existing lightness adaptation methods. Code is available at https://github.com/mdyao/CSNorm.
Continuous Spectral Reconstruction from RGB Images via Implicit Neural Representation
Dec 24, 2021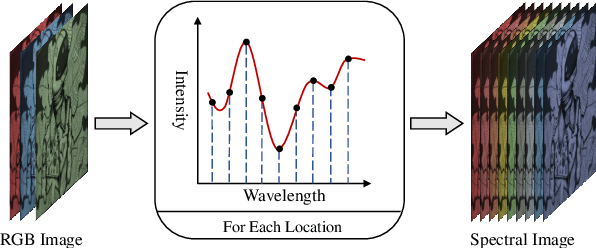
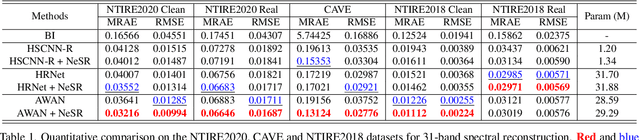
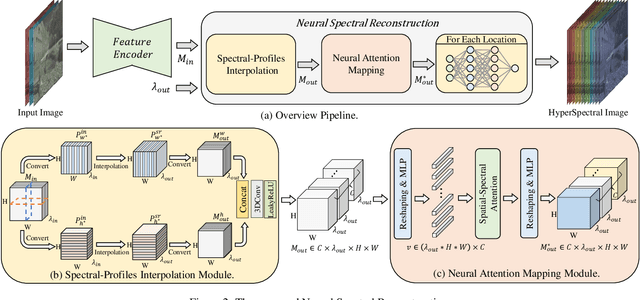

Existing methods for spectral reconstruction usually learn a discrete mapping from RGB images to a number of spectral bands. However, this modeling strategy ignores the continuous nature of spectral signature. In this paper, we propose Neural Spectral Reconstruction (NeSR) to lift this limitation, by introducing a novel continuous spectral representation. To this end, we embrace the concept of implicit function and implement a parameterized embodiment with a neural network. Specifically, we first adopt a backbone network to extract spatial features of RGB inputs. Based on it, we devise Spectral Profile Interpolation (SPI) module and Neural Attention Mapping (NAM) module to enrich deep features, where the spatial-spectral correlation is involved for a better representation. Then, we view the number of sampled spectral bands as the coordinate of continuous implicit function, so as to learn the projection from deep features to spectral intensities. Extensive experiments demonstrate the distinct advantage of NeSR in reconstruction accuracy over baseline methods. Moreover, NeSR extends the flexibility of spectral reconstruction by enabling an arbitrary number of spectral bands as the target output.
EDPN: Enhanced Deep Pyramid Network for Blurry Image Restoration
May 11, 2021
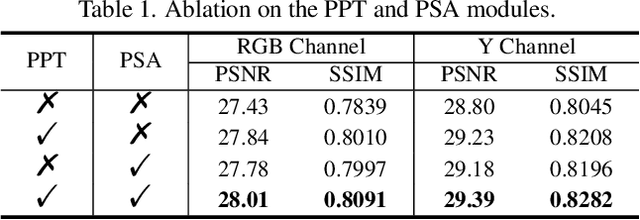

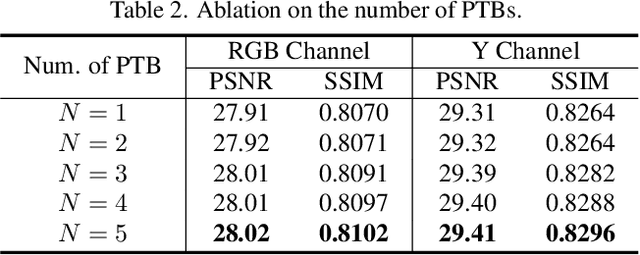
Image deblurring has seen a great improvement with the development of deep neural networks. In practice, however, blurry images often suffer from additional degradations such as downscaling and compression. To address these challenges, we propose an Enhanced Deep Pyramid Network (EDPN) for blurry image restoration from multiple degradations, by fully exploiting the self- and cross-scale similarities in the degraded image.Specifically, we design two pyramid-based modules, i.e., the pyramid progressive transfer (PPT) module and the pyramid self-attention (PSA) module, as the main components of the proposed network. By taking several replicated blurry images as inputs, the PPT module transfers both self- and cross-scale similarity information from the same degraded image in a progressive manner. Then, the PSA module fuses the above transferred features for subsequent restoration using self- and spatial-attention mechanisms. Experimental results demonstrate that our method significantly outperforms existing solutions for blurry image super-resolution and blurry image deblocking. In the NTIRE 2021 Image Deblurring Challenge, EDPN achieves the best PSNR/SSIM/LPIPS scores in Track 1 (Low Resolution) and the best SSIM/LPIPS scores in Track 2 (JPEG Artifacts).