 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoRe-MoE: Contrastive Reweighted Mixture of Experts for Multi-Terrain Humanoid Locomotion with Gait Adaptation
Jun 03, 2026Humans primarily rely on walking and running to traverse complex terrains, without resorting to unnecessarily complex motion patterns. Similarly, humanoid robots should achieve smooth transitions between walking and running while maintaining natural and stable locomotion. However, unifying gait transition and multi-terrain adaptation within a single policy remains challenging due to gradient interference and the distribution shift induced by terrain-dependent visual and dynamic variations. Although Mixture-of-Experts (MoE) architectures can alleviate multi-skill interference, naive joint training often fails to yield clear expert specialization, limiting their effectiveness. To address these challenges, we propose CoRe-MoE, a two-stage reinforcement learning framework that decouples gait generation from terrain adaptation. In the first stage, a stable locomotion policy is learned to produce natural walking and running behaviors with smooth transitions. In the second stage, a terrain-aware MoE branch is introduced and trained with a contrastive objective to shape the gating network, enabling it to capture structured terrain representations and promote expert specialization. The final action is obtained via weighted fusion of the base gait policy and the terrain-aware branch, allowing the policy to preserve stable locomotion patterns while adapting to complex terrains. Extensive simulation results demonstrate that the proposed method outperforms baseline approaches in terms of success rate, locomotion stability, and multi-terrain adaptability. Furthermore, zero-shot deployment on a Unitree G1 humanoid robot validates the effectiveness of our framework, achieving robust walking and running across stairs, slopes, steps, obstacles, and unstructured outdoor terrains, while maintaining accurate foothold placement and dynamic stability under external disturbances.
ParkourFormer: Integrating Predictive Supervision and Sequence Modeling into Parkour Locomotion
May 26, 2026Humanoid parkour requires locomotion policies to coordinate whole-body dynamics across rapidly changing terrains such as stairs, gaps, slopes, and obstacles. Existing reinforcement learning policies are largely reactive, mapping observations directly to actions without explicitly modeling future body states. Such modeling becomes critical in agile locomotion tasks where successful motion execution depends strongly on anticipating upcoming contact transitions and body dynamics. We present ParkourFormer, a Transformer-based sequence modeling framework that reformulates humanoid locomotion as a future-conditioned decision-making problem. The current robot state queries historical sensorimotor trajectories through cross-attention, while a lightweight prediction head forecasts short-horizon future proprioceptive states. The predicted future states, trained with supervised signals, are fused with temporal features to generate actions, enabling the policy to jointly reason over motion history and anticipated future dynamics. We evaluate ParkourFormer on a diverse multi-terrain humanoid parkour benchmark including stairs, gaps, slopes, rough terrain, and obstacle traversal. Experiments in simulation and on a real humanoid robot show that ParkourFormer achieves a 93.85% average traversal success rate on highly challenging terrains, with improvements of up to 42.73% over strong MLP, MoE-based MLP, and vanilla Transformer baselines, while maintaining a single unified policy across all terrain types. These results demonstrate that explicit future-state modeling significantly improves robustness and generalization for agile whole-body locomotion.
UI-Zoomer: Uncertainty-Driven Adaptive Zoom-In for GUI Grounding
Apr 15, 2026GUI grounding, which localizes interface elements from screenshots given natural language queries, remains challenging for small icons and dense layouts. Test-time zoom-in methods improve localization by cropping and re-running inference at higher resolution, but apply cropping uniformly across all instances with fixed crop sizes, ignoring whether the model is actually uncertain on each case. We propose \textbf{UI-Zoomer}, a training-free adaptive zoom-in framework that treats both the trigger and scale of zoom-in as a prediction uncertainty quantification problem. A confidence-aware gate fuses spatial consensus among stochastic candidates with token-level generation confidence to selectively trigger zoom-in only when localization is uncertain. When triggered, an uncertainty-driven crop sizing module decomposes prediction variance into inter-sample positional spread and intra-sample box extent, deriving a per-instance crop radius via the law of total variance. Extensive experiments on ScreenSpot-Pro, UI-Vision, and ScreenSpot-v2 demonstrate consistent improvements over strong baselines across multiple model architectures, achieving gains of up to +13.4\%, +10.3\%, and +4.2\% respectively, with no additional training required.
Modeling Cross-vision Synergy for Unified Large Vision Model
Mar 03, 2026Recent advances in large vision models (LVMs) have shifted from modality-specific designs toward unified architectures that jointly process images, videos, and 3D data. However, existing unified LVMs primarily pursue functional integration, while overlooking the deeper goal of cross-vision synergy: the ability to reason over complementary priors across visual modalities. To address this, we present PolyV, a unified LVM that achieves cross-vision synergy at both the architectural and training levels. Architecturally, PolyV adopts a sparse Mixture-of-Experts LVM coordinated by a dynamic modality router, allowing each expert to specialize in modality-specific priors while enabling bidirectional interaction and mutual refinement across modalities. Training-wise, a synergy-aware paradigm combines modality-specific pretraining with coarse-to-fine synergy tuning via knowledge distillation and object-/relation-level alignment. Extensive experiments on 10 benchmarks spanning image, video, and 3D understanding, including synergy-focused datasets requiring spatial or temporal priors, demonstrate that PolyV consistently outperforms existing models, achieving over 10% average improvement over its backbone. Overall, PolyV establishes a unified framework for synesthetic visual reasoning, advancing toward truly synergistic LVMs. Project page: https://sqwu.top/PolyV.
Judging by the Rules: Compliance-Aligned Framework for Modern Slavery Statement Monitoring
Nov 11, 2025Modern slavery affects millions of people worldwide, and regulatory frameworks such as Modern Slavery Acts now require companies to publish detailed disclosures. However, these statements are often vague and inconsistent, making manual review time-consuming and difficult to scale. While NLP offers a promising path forward, high-stakes compliance tasks require more than accurate classification: they demand transparent, rule-aligned outputs that legal experts can verify. Existing applications of large language models (LLMs) often reduce complex regulatory assessments to binary decisions, lacking the necessary structure for robust legal scrutiny. We argue that compliance verification is fundamentally a rule-matching problem: it requires evaluating whether textual statements adhere to well-defined regulatory rules. To this end, we propose a novel framework that harnesses AI for rule-level compliance verification while preserving expert oversight. At its core is the Compliance Alignment Judge (CA-Judge), which evaluates model-generated justifications based on their fidelity to statutory requirements. Using this feedback, we train the Compliance Alignment LLM (CALLM), a model that produces rule-consistent, human-verifiable outputs. CALLM improves predictive performance and generates outputs that are both transparent and legally grounded, offering a more verifiable and actionable solution for real-world compliance analysis.
CurriFlow: Curriculum-Guided Depth Fusion with Optical Flow-Based Temporal Alignment for 3D Semantic Scene Completion
Oct 14, 2025Semantic Scene Completion (SSC) aims to infer complete 3D geometry and semantics from monocular images, serving as a crucial capability for camera-based perception in autonomous driving. However, existing SSC methods relying on temporal stacking or depth projection often lack explicit motion reasoning and struggle with occlusions and noisy depth supervision. We propose CurriFlow, a novel semantic occupancy prediction framework that integrates optical flow-based temporal alignment with curriculum-guided depth fusion. CurriFlow employs a multi-level fusion strategy to align segmentation, visual, and depth features across frames using pre-trained optical flow, thereby improving temporal consistency and dynamic object understanding. To enhance geometric robustness, a curriculum learning mechanism progressively transitions from sparse yet accurate LiDAR depth to dense but noisy stereo depth during training, ensuring stable optimization and seamless adaptation to real-world deployment. Furthermore, semantic priors from the Segment Anything Model (SAM) provide category-agnostic supervision, strengthening voxel-level semantic learning and spatial consistency. Experiments on the SemanticKITTI benchmark demonstrate that CurriFlow achieves state-of-the-art performance with a mean IoU of 16.9, validating the effectiveness of our motion-guided and curriculum-aware design for camera-based 3D semantic scene completion.
STARS: A Unified Framework for Singing Transcription, Alignment, and Refined Style Annotation
Jul 09, 2025Recent breakthroughs in singing voice synthesis (SVS) have heightened the demand for high-quality annotated datasets, yet manual annotation remains prohibitively labor-intensive and resource-intensive. Existing automatic singing annotation (ASA) methods, however, primarily tackle isolated aspects of the annotation pipeline. To address this fundamental challenge, we present STARS, which is, to our knowledge, the first unified framework that simultaneously addresses singing transcription, alignment, and refined style annotation. Our framework delivers comprehensive multi-level annotations encompassing: (1) precise phoneme-audio alignment, (2) robust note transcription and temporal localization, (3) expressive vocal technique identification, and (4) global stylistic characterization including emotion and pace. The proposed architecture employs hierarchical acoustic feature processing across frame, word, phoneme, note, and sentence levels. The novel non-autoregressive local acoustic encoders enable structured hierarchical representation learning. Experimental validation confirms the framework's superior performance across multiple evaluation dimensions compared to existing annotation approaches. Furthermore, applications in SVS training demonstrate that models utilizing STARS-annotated data achieve significantly enhanced perceptual naturalness and precise style control. This work not only overcomes critical scalability challenges in the creation of singing datasets but also pioneers new methodologies for controllable singing voice synthesis. Audio samples are available at https://gwx314.github.io/stars-demo/.
SAMamba: Adaptive State Space Modeling with Hierarchical Vision for Infrared Small Target Detection
May 29, 2025Infrared small target detection (ISTD) is vital for long-range surveillance in military, maritime, and early warning applications. ISTD is challenged by targets occupying less than 0.15% of the image and low distinguishability from complex backgrounds. Existing deep learning methods often suffer from information loss during downsampling and inefficient global context modeling. This paper presents SAMamba, a novel framework integrating SAM2's hierarchical feature learning with Mamba's selective sequence modeling. Key innovations include: (1) A Feature Selection Adapter (FS-Adapter) for efficient natural-to-infrared domain adaptation via dual-stage selection (token-level with a learnable task embedding and channel-wise adaptive transformations); (2) A Cross-Channel State-Space Interaction (CSI) module for efficient global context modeling with linear complexity using selective state space modeling; and (3) A Detail-Preserving Contextual Fusion (DPCF) module that adaptively combines multi-scale features with a gating mechanism to balance high-resolution and low-resolution feature contributions. SAMamba addresses core ISTD challenges by bridging the domain gap, maintaining fine-grained details, and efficiently modeling long-range dependencies. Experiments on NUAA-SIRST, IRSTD-1k, and NUDT-SIRST datasets show SAMamba significantly outperforms state-of-the-art methods, especially in challenging scenarios with heterogeneous backgrounds and varying target scales. Code: https://github.com/zhengshuchen/SAMamba.
FDBPL: Faster Distillation-Based Prompt Learning for Region-Aware Vision-Language Models Adaptation
May 23, 2025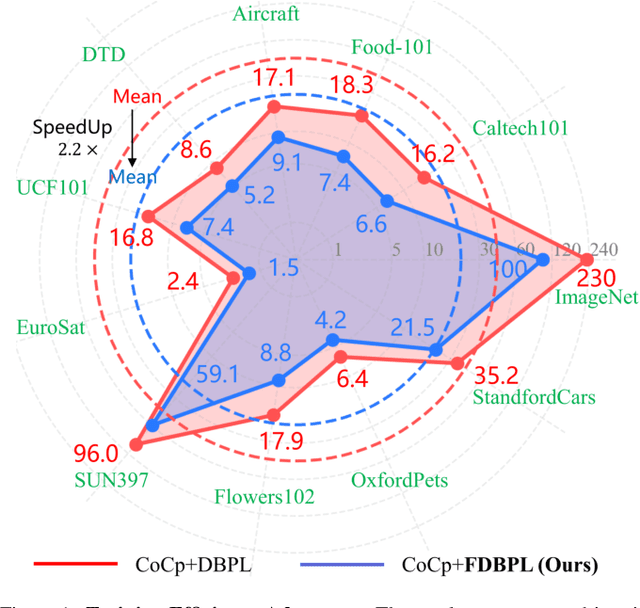
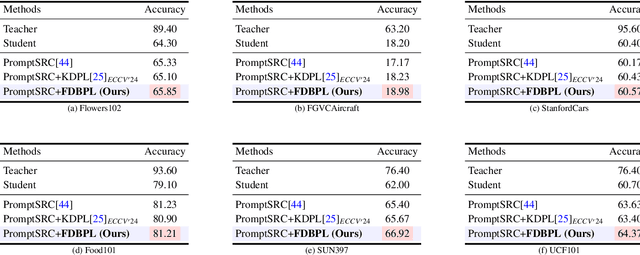
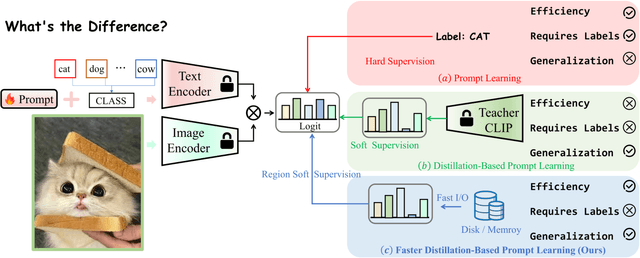
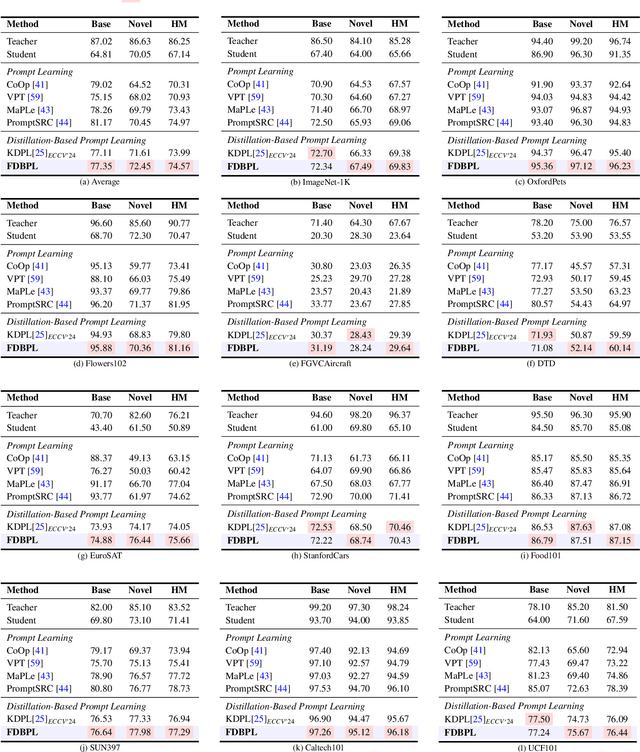
Prompt learning as a parameter-efficient method that has been widely adopted to adapt Vision-Language Models (VLMs) to downstream tasks. While hard-prompt design requires domain expertise and iterative optimization, soft-prompt methods rely heavily on task-specific hard labels, limiting their generalization to unseen categories. Recent popular distillation-based prompt learning methods improve generalization by exploiting larger teacher VLMs and unsupervised knowledge transfer, yet their repetitive teacher model online inference sacrifices the inherent training efficiency advantage of prompt learning. In this paper, we propose {{\large {\textbf{F}}}}aster {{\large {\textbf{D}}}}istillation-{{\large {\textbf{B}}}}ased {{\large {\textbf{P}}}}rompt {{\large {\textbf{L}}}}earning (\textbf{FDBPL}), which addresses these issues by sharing soft supervision contexts across multiple training stages and implementing accelerated I/O. Furthermore, FDBPL introduces a region-aware prompt learning paradigm with dual positive-negative prompt spaces to fully exploit randomly cropped regions that containing multi-level information. We propose a positive-negative space mutual learning mechanism based on similarity-difference learning, enabling student CLIP models to recognize correct semantics while learning to reject weakly related concepts, thereby improving zero-shot performance. Unlike existing distillation-based prompt learning methods that sacrifice parameter efficiency for generalization, FDBPL maintains dual advantages of parameter efficiency and strong downstream generalization. Comprehensive evaluations across 11 datasets demonstrate superior performance in base-to-new generalization, cross-dataset transfer, and robustness tests, achieving $2.2\times$ faster training speed.
Image Recognition with Online Lightweight Vision Transformer: A Survey
May 06, 2025The Transformer architecture has achieved significant success in natural language processing, motivating its adaptation to computer vision tasks. Unlike convolutional neural networks, vision transformers inherently capture long-range dependencies and enable parallel processing, yet lack inductive biases and efficiency benefits, facing significant computational and memory challenges that limit its real-world applicability. This paper surveys various online strategies for generating lightweight vision transformers for image recognition, focusing on three key areas: Efficient Component Design, Dynamic Network, and Knowledge Distillation. We evaluate the relevant exploration for each topic on the ImageNet-1K benchmark, analyzing trade-offs among precision, parameters, throughput, and more to highlight their respective advantages, disadvantages, and flexibility. Finally, we propose future research directions and potential challenges in the lightweighting of vision transformers with the aim of inspiring further exploration and providing practical guidance for the community. Project Page: https://github.com/ajxklo/Lightweight-VIT