 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing the Unseen: Zooming in the Dark with Event Cameras
Jan 05, 2026This paper addresses low-light video super-resolution (LVSR), aiming to restore high-resolution videos from low-light, low-resolution (LR) inputs. Existing LVSR methods often struggle to recover fine details due to limited contrast and insufficient high-frequency information. To overcome these challenges, we present RetinexEVSR, the first event-driven LVSR framework that leverages high-contrast event signals and Retinex-inspired priors to enhance video quality under low-light scenarios. Unlike previous approaches that directly fuse degraded signals, RetinexEVSR introduces a novel bidirectional cross-modal fusion strategy to extract and integrate meaningful cues from noisy event data and degraded RGB frames. Specifically, an illumination-guided event enhancement module is designed to progressively refine event features using illumination maps derived from the Retinex model, thereby suppressing low-light artifacts while preserving high-contrast details. Furthermore, we propose an event-guided reflectance enhancement module that utilizes the enhanced event features to dynamically recover reflectance details via a multi-scale fusion mechanism. Experimental results show that our RetinexEVSR achieves state-of-the-art performance on three datasets. Notably, on the SDSD benchmark, our method can get up to 2.95 dB gain while reducing runtime by 65% compared to prior event-based methods. Code: https://github.com/DachunKai/RetinexEVSR.
Mind Meets Space: Rethinking Agentic Spatial Intelligence from a Neuroscience-inspired Perspective
Sep 11, 2025Recent advances in agentic AI have led to systems capable of autonomous task execution and language-based reasoning, yet their spatial reasoning abilities remain limited and underexplored, largely constrained to symbolic and sequential processing. In contrast, human spatial intelligence, rooted in integrated multisensory perception, spatial memory, and cognitive maps, enables flexible, context-aware decision-making in unstructured environments. Therefore, bridging this gap is critical for advancing Agentic Spatial Intelligence toward better interaction with the physical 3D world. To this end, we first start from scrutinizing the spatial neural models as studied in computational neuroscience, and accordingly introduce a novel computational framework grounded in neuroscience principles. This framework maps core biological functions to six essential computation modules: bio-inspired multimodal sensing, multi-sensory integration, egocentric-allocentric conversion, an artificial cognitive map, spatial memory, and spatial reasoning. Together, these modules form a perspective landscape for agentic spatial reasoning capability across both virtual and physical environments. On top, we conduct a framework-guided analysis of recent methods, evaluating their relevance to each module and identifying critical gaps that hinder the development of more neuroscience-grounded spatial reasoning modules. We further examine emerging benchmarks and datasets and explore potential application domains ranging from virtual to embodied systems, such as robotics. Finally, we outline potential research directions, emphasizing the promising roadmap that can generalize spatial reasoning across dynamic or unstructured environments. We hope this work will benefit the research community with a neuroscience-grounded perspective and a structured pathway. Our project page can be found at Github.
Create Anything Anywhere: Layout-Controllable Personalized Diffusion Model for Multiple Subjects
May 27, 2025Diffusion models have significantly advanced text-to-image generation, laying the foundation for the development of personalized generative frameworks. However, existing methods lack precise layout controllability and overlook the potential of dynamic features of reference subjects in improving fidelity. In this work, we propose Layout-Controllable Personalized Diffusion (LCP-Diffusion) model, a novel framework that integrates subject identity preservation with flexible layout guidance in a tuning-free approach. Our model employs a Dynamic-Static Complementary Visual Refining module to comprehensively capture the intricate details of reference subjects, and introduces a Dual Layout Control mechanism to enforce robust spatial control across both training and inference stages. Extensive experiments validate that LCP-Diffusion excels in both identity preservation and layout controllability. To the best of our knowledge, this is a pioneering work enabling users to "create anything anywhere".
Event-Enhanced Blurry Video Super-Resolution
Apr 18, 2025In this paper, we tackle the task of blurry video super-resolution (BVSR), aiming to generate high-resolution (HR) videos from low-resolution (LR) and blurry inputs. Current BVSR methods often fail to restore sharp details at high resolutions, resulting in noticeable artifacts and jitter due to insufficient motion information for deconvolution and the lack of high-frequency details in LR frames. To address these challenges, we introduce event signals into BVSR and propose a novel event-enhanced network, Ev-DeblurVSR. To effectively fuse information from frames and events for feature deblurring, we introduce a reciprocal feature deblurring module that leverages motion information from intra-frame events to deblur frame features while reciprocally using global scene context from the frames to enhance event features. Furthermore, to enhance temporal consistency, we propose a hybrid deformable alignment module that fully exploits the complementary motion information from inter-frame events and optical flow to improve motion estimation in the deformable alignment process. Extensive evaluations demonstrate that Ev-DeblurVSR establishes a new state-of-the-art performance on both synthetic and real-world datasets. Notably, on real data, our method is +2.59 dB more accurate and 7.28$\times$ faster than the recent best BVSR baseline FMA-Net. Code: https://github.com/DachunKai/Ev-DeblurVSR.
Fine-Grained Evaluation of Large Vision-Language Models in Autonomous Driving
Mar 27, 2025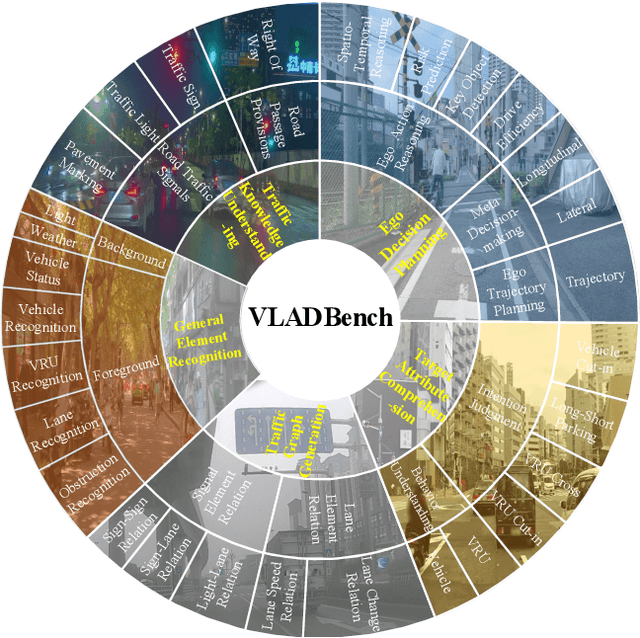

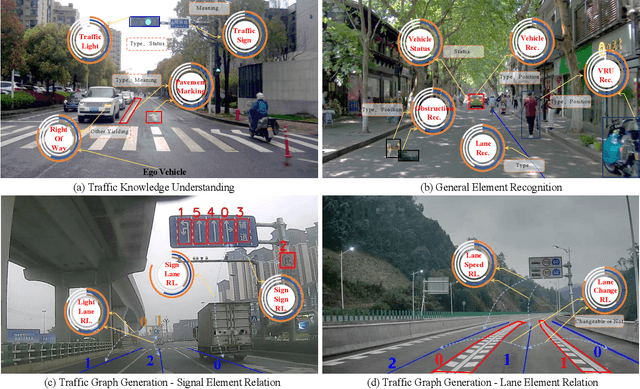

Existing benchmarks for Vision-Language Model (VLM) on autonomous driving (AD) primarily assess interpretability through open-form visual question answering (QA) within coarse-grained tasks, which remain insufficient to assess capabilities in complex driving scenarios. To this end, we introduce $\textbf{VLADBench}$, a challenging and fine-grained dataset featuring close-form QAs that progress from static foundational knowledge and elements to advanced reasoning for dynamic on-road situations. The elaborate $\textbf{VLADBench}$ spans 5 key domains: Traffic Knowledge Understanding, General Element Recognition, Traffic Graph Generation, Target Attribute Comprehension, and Ego Decision-Making and Planning. These domains are further broken down into 11 secondary aspects and 29 tertiary tasks for a granular evaluation. A thorough assessment of general and domain-specific (DS) VLMs on this benchmark reveals both their strengths and critical limitations in AD contexts. To further exploit the cognitive and reasoning interactions among the 5 domains for AD understanding, we start from a small-scale VLM and train the DS models on individual domain datasets (collected from 1.4M DS QAs across public sources). The experimental results demonstrate that the proposed benchmark provides a crucial step toward a more comprehensive assessment of VLMs in AD, paving the way for the development of more cognitively sophisticated and reasoning-capable AD systems.
Denoising Designs-inherited Search Framework for Image Denoising
Feb 19, 2025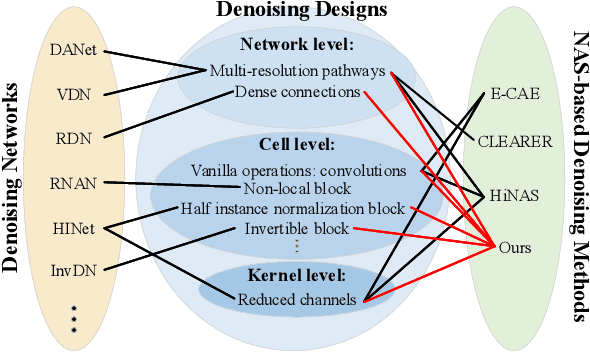
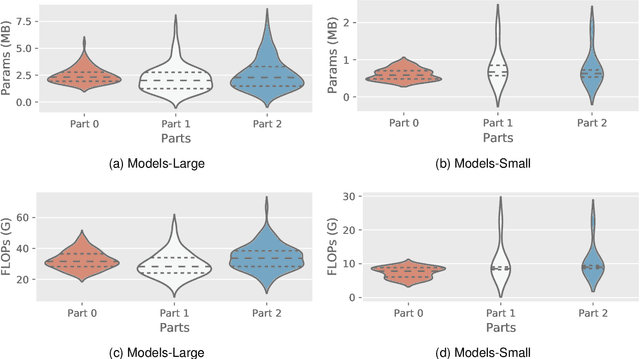
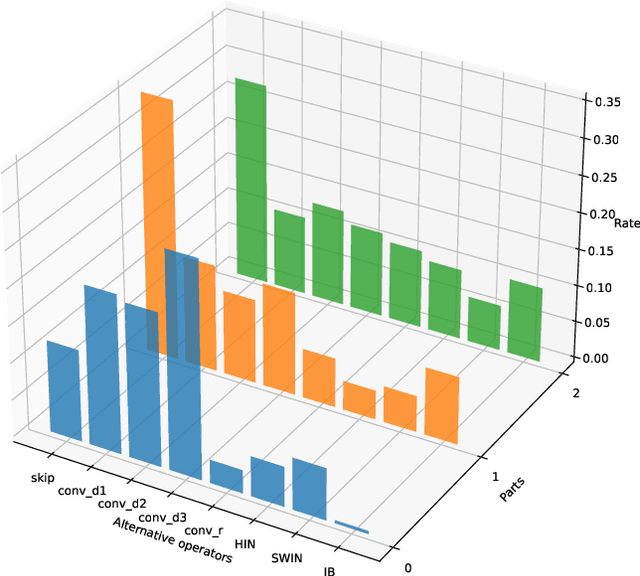
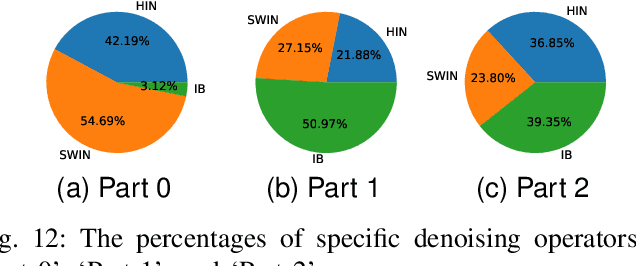
How to benefit from plenty of existing denoising designs? Few methods via Neural Architecture Search (NAS) intend to answer this question. However, these NAS-based denoising methods explore limited search space and are hard to extend in terms of search space due to high computational burden. To tackle these limitations, we propose the first search framework to explore mainstream denoising designs. In our framework, the search space consists of the network-level, the cell-level and the kernel-level search space, which aims to inherit as many denoising designs as possible. Coordinating search strategies are proposed to facilitate the extension of various denoising designs. In such a giant search space, it is laborious to search for an optimal architecture. To solve this dilemma, we introduce the first regularization, i.e., denoising prior-based regularization, which reduces the search difficulty. To get an efficient architecture, we introduce the other regularization, i.e., inference time-based regularization, optimizes the search process on model complexity. Based on our framework, our searched architecture achieves state-of-the-art results for image denoising on multiple real-world and synthetic datasets. The parameters of our searched architecture are $1/3$ of Restormer's, and our method surpasses existing NAS-based denoising methods by $1.50$ dB in the real-world dataset. Moreover, we discuss the preferences of $\textbf{200}$ searched architectures, and provide directions for further work.
Spiking Point Transformer for Point Cloud Classification
Feb 19, 2025Spiking Neural Networks (SNNs) offer an attractive and energy-efficient alternative to conventional Artificial Neural Networks (ANNs) due to their sparse binary activation. When SNN meets Transformer, it shows great potential in 2D image processing. However, their application for 3D point cloud remains underexplored. To this end, we present Spiking Point Transformer (SPT), the first transformer-based SNN framework for point cloud classification. Specifically, we first design Queue-Driven Sampling Direct Encoding for point cloud to reduce computational costs while retaining the most effective support points at each time step. We introduce the Hybrid Dynamics Integrate-and-Fire Neuron (HD-IF), designed to simulate selective neuron activation and reduce over-reliance on specific artificial neurons. SPT attains state-of-the-art results on three benchmark datasets that span both real-world and synthetic datasets in the SNN domain. Meanwhile, the theoretical energy consumption of SPT is at least 6.4$\times$ less than its ANN counterpart.
Event-boosted Deformable 3D Gaussians for Fast Dynamic Scene Reconstruction
Nov 25, 2024



3D Gaussian Splatting (3D-GS) enables real-time rendering but struggles with fast motion due to low temporal resolution of RGB cameras. To address this, we introduce the first approach combining event cameras, which capture high-temporal-resolution, continuous motion data, with deformable 3D-GS for fast dynamic scene reconstruction. We observe that threshold modeling for events plays a crucial role in achieving high-quality reconstruction. Therefore, we propose a GS-Threshold Joint Modeling (GTJM) strategy, creating a mutually reinforcing process that greatly improves both 3D reconstruction and threshold modeling. Moreover, we introduce a Dynamic-Static Decomposition (DSD) strategy that first identifies dynamic areas by exploiting the inability of static Gaussians to represent motions, then applies a buffer-based soft decomposition to separate dynamic and static areas. This strategy accelerates rendering by avoiding unnecessary deformation in static areas, and focuses on dynamic areas to enhance fidelity. Our approach achieves high-fidelity dynamic reconstruction at 156 FPS with a 400$\times$400 resolution on an RTX 3090 GPU.
D-FINE: Redefine Regression Task in DETRs as Fine-grained Distribution Refinement
Oct 17, 2024



We introduce D-FINE, a powerful real-time object detector that achieves outstanding localization precision by redefining the bounding box regression task in DETR models. D-FINE comprises two key components: Fine-grained Distribution Refinement (FDR) and Global Optimal Localization Self-Distillation (GO-LSD). FDR transforms the regression process from predicting fixed coordinates to iteratively refining probability distributions, providing a fine-grained intermediate representation that significantly enhances localization accuracy. GO-LSD is a bidirectional optimization strategy that transfers localization knowledge from refined distributions to shallower layers through self-distillation, while also simplifying the residual prediction tasks for deeper layers. Additionally, D-FINE incorporates lightweight optimizations in computationally intensive modules and operations, achieving a better balance between speed and accuracy. Specifically, D-FINE-L / X achieves 54.0% / 55.8% AP on the COCO dataset at 124 / 78 FPS on an NVIDIA T4 GPU. When pretrained on Objects365, D-FINE-L / X attains 57.1% / 59.3% AP, surpassing all existing real-time detectors. Furthermore, our method significantly enhances the performance of a wide range of DETR models by up to 5.3% AP with negligible extra parameters and training costs. Our code and pretrained models: https://github.com/Peterande/D-FINE.
Generalizable Non-Line-of-Sight Imaging with Learnable Physical Priors
Sep 21, 2024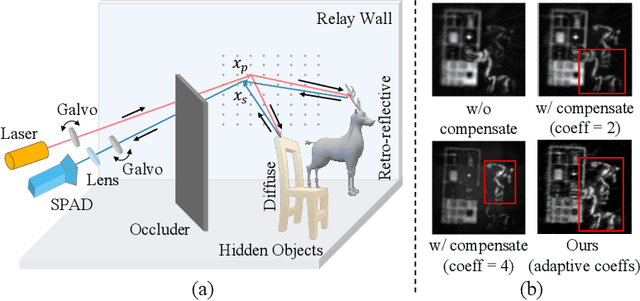
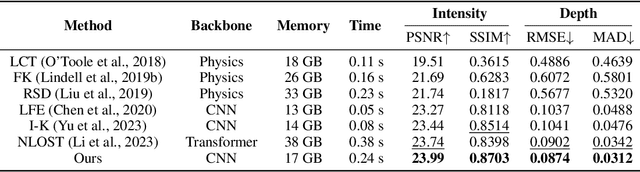
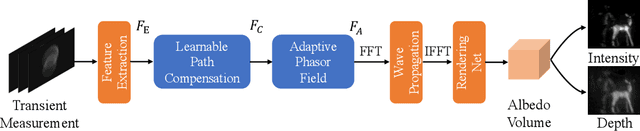
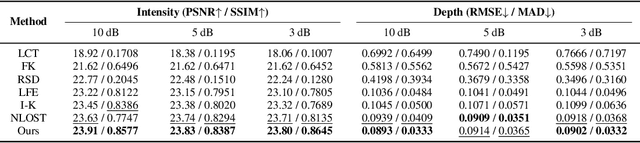
Non-line-of-sight (NLOS) imaging, recovering the hidden volume from indirect reflections, has attracted increasing attention due to its potential applications. Despite promising results, existing NLOS reconstruction approaches are constrained by the reliance on empirical physical priors, e.g., single fixed path compensation. Moreover, these approaches still possess limited generalization ability, particularly when dealing with scenes at a low signal-to-noise ratio (SNR). To overcome the above problems, we introduce a novel learning-based solution, comprising two key designs: Learnable Path Compensation (LPC) and Adaptive Phasor Field (APF). The LPC applies tailored path compensation coefficients to adapt to different objects in the scene, effectively reducing light wave attenuation, especially in distant regions. Meanwhile, the APF learns the precise Gaussian window of the illumination function for the phasor field, dynamically selecting the relevant spectrum band of the transient measurement. Experimental validations demonstrate that our proposed approach, only trained on synthetic data, exhibits the capability to seamlessly generalize across various real-world datasets captured by different imaging systems and characterized by low SNRs.