 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizable and Interpretable RF Fingerprinting with Shapelet-Enhanced Large Language Models
Feb 03, 2026Deep neural networks (DNNs) have achieved remarkable success in radio frequency (RF) fingerprinting for wireless device authentication. However, their practical deployment faces two major limitations: domain shift, where models trained in one environment struggle to generalize to others, and the black-box nature of DNNs, which limits interpretability. To address these issues, we propose a novel framework that integrates a group of variable-length two-dimensional (2D) shapelets with a pre-trained large language model (LLM) to achieve efficient, interpretable, and generalizable RF fingerprinting. The 2D shapelets explicitly capture diverse local temporal patterns across the in-phase and quadrature (I/Q) components, providing compact and interpretable representations. Complementarily, the pre-trained LLM captures more long-range dependencies and global contextual information, enabling strong generalization with minimal training overhead. Moreover, our framework also supports prototype generation for few-shot inference, enhancing cross-domain performance without additional retraining. To evaluate the effectiveness of our proposed method, we conduct extensive experiments on six datasets across various protocols and domains. The results show that our method achieves superior standard and few-shot performance across both source and unseen domains.
TALON: Confidence-Aware Speculative Decoding with Adaptive Token Trees
Jan 12, 2026Speculative decoding (SD) has become a standard technique for accelerating LLM inference without sacrificing output quality. Recent advances in speculative decoding have shifted from sequential chain-based drafting to tree-structured generation, where the draft model constructs a tree of candidate tokens to explore multiple possible drafts in parallel. However, existing tree-based SD methods typically build a fixed-width, fixed-depth draft tree, which fails to adapt to the varying difficulty of tokens and contexts. As a result, the draft model cannot dynamically adjust the tree structure to early stop on difficult tokens and extend generation for simple ones. To address these challenges, we introduce TALON, a training-free, budget-driven adaptive tree expansion framework that can be plugged into existing tree-based methods. Unlike static methods, TALON constructs the draft tree iteratively until a fixed token budget is met, using a hybrid expansion strategy that adaptively allocates the node budget to each layer of the draft tree. This framework naturally shapes the draft tree into a "deep-and-narrow" form for deterministic contexts and a "shallow-and-wide" form for uncertain branches, effectively optimizing the trade-off between exploration width and generation depth under a given budget. Extensive experiments across 5 models and 6 datasets demonstrate that TALON consistently outperforms state-of-the-art EAGLE-3, achieving up to 5.16x end-to-end speedup over auto-regressive decoding.
MAFS: Multi-head Attention Feature Selection for High-Dimensional Data via Deep Fusion of Filter Methods
Jan 06, 2026Feature selection is essential for high-dimensional biomedical data, enabling stronger predictive performance, reduced computational cost, and improved interpretability in precision medicine applications. Existing approaches face notable challenges. Filter methods are highly scalable but cannot capture complex relationships or eliminate redundancy. Deep learning-based approaches can model nonlinear patterns but often lack stability, interpretability, and efficiency at scale. Single-head attention improves interpretability but is limited in capturing multi-level dependencies and remains sensitive to initialization, reducing reproducibility. Most existing methods rarely combine statistical interpretability with the representational power of deep learning, particularly in ultra-high-dimensional settings. Here, we introduce MAFS (Multi-head Attention-based Feature Selection), a hybrid framework that integrates statistical priors with deep learning capabilities. MAFS begins with filter-based priors for stable initialization and guide learning. It then uses multi-head attention to examine features from multiple perspectives in parallel, capturing complex nonlinear relationships and interactions. Finally, a reordering module consolidates outputs across attention heads, resolving conflicts and minimizing information loss to generate robust and consistent feature rankings. This design combines statistical guidance with deep modeling capacity, yielding interpretable importance scores while maximizing retention of informative signals. Across simulated and real-world datasets, including cancer gene expression and Alzheimer's disease data, MAFS consistently achieves superior coverage and stability compared with existing filter-based and deep learning-based alternatives, offering a scalable, interpretable, and robust solution for feature selection in high-dimensional biomedical data.
Seeing the Unseen: Zooming in the Dark with Event Cameras
Jan 05, 2026This paper addresses low-light video super-resolution (LVSR), aiming to restore high-resolution videos from low-light, low-resolution (LR) inputs. Existing LVSR methods often struggle to recover fine details due to limited contrast and insufficient high-frequency information. To overcome these challenges, we present RetinexEVSR, the first event-driven LVSR framework that leverages high-contrast event signals and Retinex-inspired priors to enhance video quality under low-light scenarios. Unlike previous approaches that directly fuse degraded signals, RetinexEVSR introduces a novel bidirectional cross-modal fusion strategy to extract and integrate meaningful cues from noisy event data and degraded RGB frames. Specifically, an illumination-guided event enhancement module is designed to progressively refine event features using illumination maps derived from the Retinex model, thereby suppressing low-light artifacts while preserving high-contrast details. Furthermore, we propose an event-guided reflectance enhancement module that utilizes the enhanced event features to dynamically recover reflectance details via a multi-scale fusion mechanism. Experimental results show that our RetinexEVSR achieves state-of-the-art performance on three datasets. Notably, on the SDSD benchmark, our method can get up to 2.95 dB gain while reducing runtime by 65% compared to prior event-based methods. Code: https://github.com/DachunKai/RetinexEVSR.
DeCo-VAE: Learning Compact Latents for Video Reconstruction via Decoupled Representation
Nov 18, 2025Existing video Variational Autoencoders (VAEs) generally overlook the similarity between frame contents, leading to redundant latent modeling. In this paper, we propose decoupled VAE (DeCo-VAE) to achieve compact latent representation. Instead of encoding RGB pixels directly, we decompose video content into distinct components via explicit decoupling: keyframe, motion and residual, and learn dedicated latent representation for each. To avoid cross-component interference, we design dedicated encoders for each decoupled component and adopt a shared 3D decoder to maintain spatiotemporal consistency during reconstruction. We further utilize a decoupled adaptation strategy that freezes partial encoders while training the others sequentially, ensuring stable training and accurate learning of both static and dynamic features. Extensive quantitative and qualitative experiments demonstrate that DeCo-VAE achieves superior video reconstruction performance.
LLaDA-VLA: Vision Language Diffusion Action Models
Sep 10, 2025The rapid progress of auto-regressive vision-language models (VLMs) has inspired growing interest in vision-language-action models (VLA) for robotic manipulation. Recently, masked diffusion models, a paradigm distinct from autoregressive models, have begun to demonstrate competitive performance in text generation and multimodal applications, leading to the development of a series of diffusion-based VLMs (d-VLMs). However, leveraging such models for robot policy learning remains largely unexplored. In this work, we present LLaDA-VLA, the first Vision-Language-Diffusion-Action model built upon pretrained d-VLMs for robotic manipulation. To effectively adapt d-VLMs to robotic domain, we introduce two key designs: (1) a localized special-token classification strategy that replaces full-vocabulary classification with special action token classification, reducing adaptation difficulty; (2) a hierarchical action-structured decoding strategy that decodes action sequences hierarchically considering the dependencies within and across actions. Extensive experiments demonstrate that LLaDA-VLA significantly outperforms state-of-the-art VLAs on both simulation and real-world robots.
EHVC: Efficient Hierarchical Reference and Quality Structure for Neural Video Coding
Sep 04, 2025Neural video codecs (NVCs), leveraging the power of end-to-end learning, have demonstrated remarkable coding efficiency improvements over traditional video codecs. Recent research has begun to pay attention to the quality structures in NVCs, optimizing them by introducing explicit hierarchical designs. However, less attention has been paid to the reference structure design, which fundamentally should be aligned with the hierarchical quality structure. In addition, there is still significant room for further optimization of the hierarchical quality structure. To address these challenges in NVCs, we propose EHVC, an efficient hierarchical neural video codec featuring three key innovations: (1) a hierarchical multi-reference scheme that draws on traditional video codec design to align reference and quality structures, thereby addressing the reference-quality mismatch; (2) a lookahead strategy to utilize an encoder-side context from future frames to enhance the quality structure; (3) a layer-wise quality scale with random quality training strategy to stabilize quality structures during inference. With these improvements, EHVC achieves significantly superior performance to the state-of-the-art NVCs. Code will be released in: https://github.com/bytedance/NEVC.
ROSA: Harnessing Robot States for Vision-Language and Action Alignment
Jun 16, 2025Vision-Language-Action (VLA) models have recently made significant advance in multi-task, end-to-end robotic control, due to the strong generalization capabilities of Vision-Language Models (VLMs). A fundamental challenge in developing such models is effectively aligning the vision-language space with the robotic action space. Existing approaches typically rely on directly fine-tuning VLMs using expert demonstrations. However, this strategy suffers from a spatio-temporal gap, resulting in considerable data inefficiency and heavy reliance on human labor. Spatially, VLMs operate within a high-level semantic space, whereas robotic actions are grounded in low-level 3D physical space; temporally, VLMs primarily interpret the present, while VLA models anticipate future actions. To overcome these challenges, we propose a novel training paradigm, ROSA, which leverages robot state estimation to improve alignment between vision-language and action spaces. By integrating robot state estimation data obtained via an automated process, ROSA enables the VLA model to gain enhanced spatial understanding and self-awareness, thereby boosting performance and generalization. Extensive experiments in both simulated and real-world environments demonstrate the effectiveness of ROSA, particularly in low-data regimes.
Create Anything Anywhere: Layout-Controllable Personalized Diffusion Model for Multiple Subjects
May 27, 2025Diffusion models have significantly advanced text-to-image generation, laying the foundation for the development of personalized generative frameworks. However, existing methods lack precise layout controllability and overlook the potential of dynamic features of reference subjects in improving fidelity. In this work, we propose Layout-Controllable Personalized Diffusion (LCP-Diffusion) model, a novel framework that integrates subject identity preservation with flexible layout guidance in a tuning-free approach. Our model employs a Dynamic-Static Complementary Visual Refining module to comprehensively capture the intricate details of reference subjects, and introduces a Dual Layout Control mechanism to enforce robust spatial control across both training and inference stages. Extensive experiments validate that LCP-Diffusion excels in both identity preservation and layout controllability. To the best of our knowledge, this is a pioneering work enabling users to "create anything anywhere".
Dome-DETR: DETR with Density-Oriented Feature-Query Manipulation for Efficient Tiny Object Detection
May 09, 2025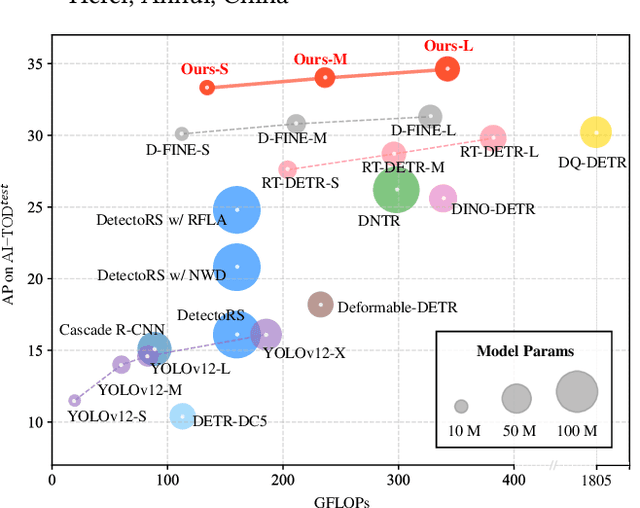
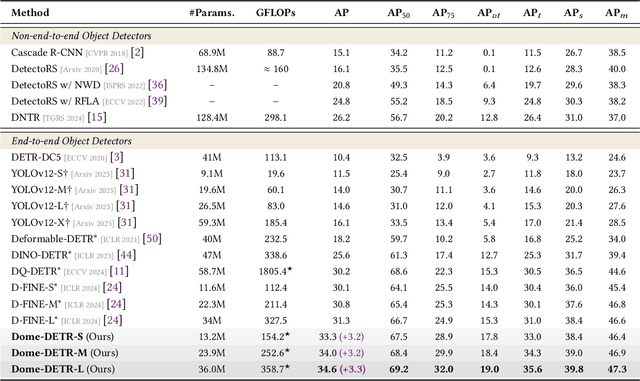
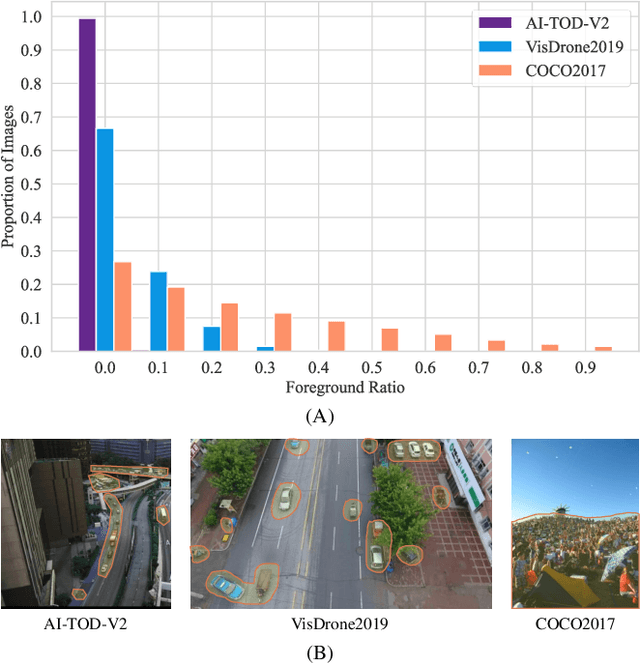
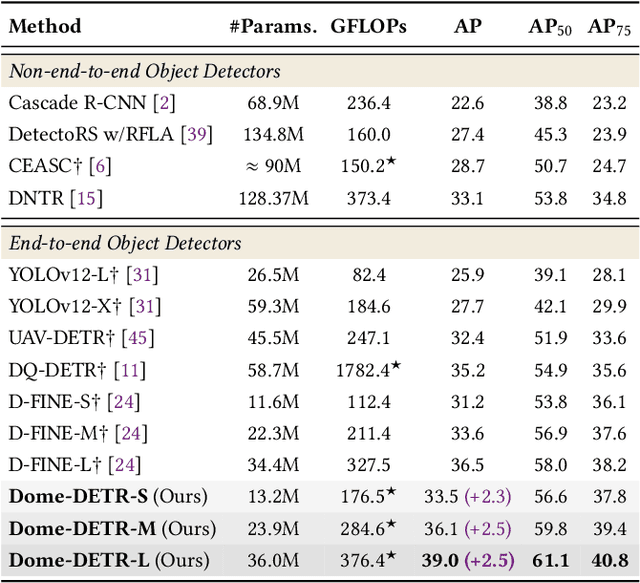
Tiny object detection plays a vital role in drone surveillance, remote sensing, and autonomous systems, enabling the identification of small targets across vast landscapes. However, existing methods suffer from inefficient feature leverage and high computational costs due to redundant feature processing and rigid query allocation. To address these challenges, we propose Dome-DETR, a novel framework with Density-Oriented Feature-Query Manipulation for Efficient Tiny Object Detection. To reduce feature redundancies, we introduce a lightweight Density-Focal Extractor (DeFE) to produce clustered compact foreground masks. Leveraging these masks, we incorporate Masked Window Attention Sparsification (MWAS) to focus computational resources on the most informative regions via sparse attention. Besides, we propose Progressive Adaptive Query Initialization (PAQI), which adaptively modulates query density across spatial areas for better query allocation. Extensive experiments demonstrate that Dome-DETR achieves state-of-the-art performance (+3.3 AP on AI-TOD-V2 and +2.5 AP on VisDrone) while maintaining low computational complexity and a compact model size. Code will be released upon acceptance.