 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-based Prompt Injection: Hijacking Multimodal LLMs through Visually Embedded Adversarial Instructions
Mar 04, 2026Multimodal Large Language Models (MLLMs) integrate vision and text to power applications, but this integration introduces new vulnerabilities. We study Image-based Prompt Injection (IPI), a black-box attack in which adversarial instructions are embedded into natural images to override model behavior. Our end-to-end IPI pipeline incorporates segmentation-based region selection, adaptive font scaling, and background-aware rendering to conceal prompts from human perception while preserving model interpretability. Using the COCO dataset and GPT-4-turbo, we evaluate 12 adversarial prompt strategies and multiple embedding configurations. The results show that IPI can reliably manipulate the output of the model, with the most effective configuration achieving up to 64\% attack success under stealth constraints. These findings highlight IPI as a practical threat in black-box settings and underscore the need for defenses against multimodal prompt injection.
* 7 pages, published in 2025 3rd International Conference on Foundation and Large Language Models (FLLM), Vienna, Austria
To Protect the LLM Agent Against the Prompt Injection Attack with Polymorphic Prompt
Jun 06, 2025LLM agents are widely used as agents for customer support, content generation, and code assistance. However, they are vulnerable to prompt injection attacks, where adversarial inputs manipulate the model's behavior. Traditional defenses like input sanitization, guard models, and guardrails are either cumbersome or ineffective. In this paper, we propose a novel, lightweight defense mechanism called Polymorphic Prompt Assembling (PPA), which protects against prompt injection with near-zero overhead. The approach is based on the insight that prompt injection requires guessing and breaking the structure of the system prompt. By dynamically varying the structure of system prompts, PPA prevents attackers from predicting the prompt structure, thereby enhancing security without compromising performance. We conducted experiments to evaluate the effectiveness of PPA against existing attacks and compared it with other defense methods.
NovelSeek: When Agent Becomes the Scientist -- Building Closed-Loop System from Hypothesis to Verification
May 22, 2025
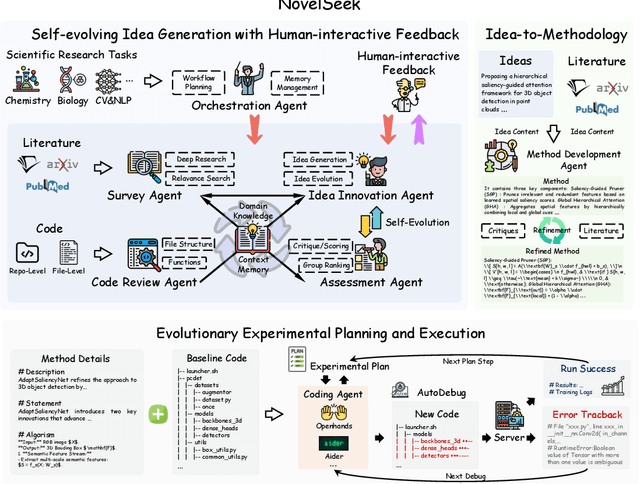

Artificial Intelligence (AI) is accelerating the transformation of scientific research paradigms, not only enhancing research efficiency but also driving innovation. We introduce NovelSeek, a unified closed-loop multi-agent framework to conduct Autonomous Scientific Research (ASR) across various scientific research fields, enabling researchers to tackle complicated problems in these fields with unprecedented speed and precision. NovelSeek highlights three key advantages: 1) Scalability: NovelSeek has demonstrated its versatility across 12 scientific research tasks, capable of generating innovative ideas to enhance the performance of baseline code. 2) Interactivity: NovelSeek provides an interface for human expert feedback and multi-agent interaction in automated end-to-end processes, allowing for the seamless integration of domain expert knowledge. 3) Efficiency: NovelSeek has achieved promising performance gains in several scientific fields with significantly less time cost compared to human efforts. For instance, in reaction yield prediction, it increased from 27.6% to 35.4% in just 12 hours; in enhancer activity prediction, accuracy rose from 0.52 to 0.79 with only 4 hours of processing; and in 2D semantic segmentation, precision advanced from 78.8% to 81.0% in a mere 30 hours.
Hide Your Malicious Goal Into Benign Narratives: Jailbreak Large Language Models through Neural Carrier Articles
Aug 20, 2024



Jailbreak attacks on Language Model Models (LLMs) entail crafting prompts aimed at exploiting the models to generate malicious content. This paper proposes a new type of jailbreak attacks which shift the attention of the LLM by inserting a prohibited query into a carrier article. The proposed attack leverage the knowledge graph and a composer LLM to automatically generating a carrier article that is similar to the topic of the prohibited query but does not violate LLM's safeguards. By inserting the malicious query to the carrier article, the assembled attack payload can successfully jailbreak LLM. To evaluate the effectiveness of our method, we leverage 4 popular categories of ``harmful behaviors'' adopted by related researches to attack 6 popular LLMs. Our experiment results show that the proposed attacking method can successfully jailbreak all the target LLMs which high success rate, except for Claude-3.
Hidden You Malicious Goal Into Benign Narratives: Jailbreak Large Language Models through Logic Chain Injection
Apr 16, 2024

Jailbreak attacks on Language Model Models (LLMs) entail crafting prompts aimed at exploiting the models to generate malicious content. Existing jailbreak attacks can successfully deceive the LLMs, however they cannot deceive the human. This paper proposes a new type of jailbreak attacks which can deceive both the LLMs and human (i.e., security analyst). The key insight of our idea is borrowed from the social psychology - that is human are easily deceived if the lie is hidden in truth. Based on this insight, we proposed the logic-chain injection attacks to inject malicious intention into benign truth. Logic-chain injection attack firstly dissembles its malicious target into a chain of benign narrations, and then distribute narrations into a related benign article, with undoubted facts. In this way, newly generate prompt cannot only deceive the LLMs, but also deceive human.
Hidden You Malicious Goal Into Benigh Narratives: Jailbreak Large Language Models through Logic Chain Injection
Apr 07, 2024Jailbreak attacks on Language Model Models (LLMs) entail crafting prompts aimed at exploiting the models to generate malicious content. Existing jailbreak attacks can successfully deceive the LLMs, however they cannot deceive the human. This paper proposes a new type of jailbreak attacks which can deceive both the LLMs and human (i.e., security analyst). The key insight of our idea is borrowed from the social psychology - that is human are easily deceived if the lie is hidden in truth. Based on this insight, we proposed the logic-chain injection attacks to inject malicious intention into benign truth. Logic-chain injection attack firstly dissembles its malicious target into a chain of benign narrations, and then distribute narrations into a related benign article, with undoubted facts. In this way, newly generate prompt cannot only deceive the LLMs, but also deceive human.
ChatGPT for Software Security: Exploring the Strengths and Limitations of ChatGPT in the Security Applications
Aug 10, 2023


ChatGPT, as a versatile large language model, has demonstrated remarkable potential in addressing inquiries across various domains. Its ability to analyze, comprehend, and synthesize information from both online sources and user inputs has garnered significant attention. Previous research has explored ChatGPT's competence in code generation and code reviews. In this paper, we delve into ChatGPT's capabilities in security-oriented program analysis, focusing on perspectives from both attackers and security analysts. We present a case study involving several security-oriented program analysis tasks while deliberately introducing challenges to assess ChatGPT's responses. Through an examination of the quality of answers provided by ChatGPT, we gain a clearer understanding of its strengths and limitations in the realm of security-oriented program analysis.
Which Features are Learned by CodeBert: An Empirical Study of the BERT-based Source Code Representation Learning
Jan 20, 2023

The Bidirectional Encoder Representations from Transformers (BERT) were proposed in the natural language process (NLP) and shows promising results. Recently researchers applied the BERT to source-code representation learning and reported some good news on several downstream tasks. However, in this paper, we illustrated that current methods cannot effectively understand the logic of source codes. The representation of source code heavily relies on the programmer-defined variable and function names. We design and implement a set of experiments to demonstrate our conjecture and provide some insights for future works.