 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIM: Intent-Aware Unified world action Modeling with Spatial Value Maps
Apr 13, 2026Pretrained video generation models provide strong priors for robot control, but existing unified world action models still struggle to decode reliable actions without substantial robot-specific training. We attribute this limitation to a structural mismatch: while video models capture how scenes evolve, action generation requires explicit reasoning about where to interact and the underlying manipulation intent. We introduce AIM, an intent-aware unified world action model that bridges this gap via an explicit spatial interface. Instead of decoding actions directly from future visual representations, AIM predicts an aligned spatial value map that encodes task-relevant interaction structure, enabling a control-oriented abstraction of future dynamics. Built on a pretrained video generation model, AIM jointly models future observations and value maps within a shared mixture-of-transformers architecture. It employs intent-causal attention to route future information to the action branch exclusively through the value representation. We further propose a self-distillation reinforcement learning stage that freezes the video and value branches and optimizes only the action head using dense rewards derived from projected value-map responses together with sparse task-level signals. To support training and evaluation, we construct a simulation dataset of 30K manipulation trajectories with synchronized multi-view observations, actions, and value-map annotations. Experiments on RoboTwin 2.0 benchmark show that AIM achieves a 94.0% average success rate, significantly outperforming prior unified world action baselines. Notably, the improvement is more pronounced in long-horizon and contact-sensitive manipulation tasks, demonstrating the effectiveness of explicit spatial-intent modeling as a bridge between visual world modeling and robot control.
Large-scale Codec Avatars: The Unreasonable Effectiveness of Large-scale Avatar Pretraining
Apr 02, 2026High-quality 3D avatar modeling faces a critical trade-off between fidelity and generalization. On the one hand, multi-view studio data enables high-fidelity modeling of humans with precise control over expressions and poses, but it struggles to generalize to real-world data due to limited scale and the domain gap between the studio environment and the real world. On the other hand, recent large-scale avatar models trained on millions of in-the-wild samples show promise for generalization across a wide range of identities, yet the resulting avatars are often of low-quality due to inherent 3D ambiguities. To address this, we present Large-Scale Codec Avatars (LCA), a high-fidelity, full-body 3D avatar model that generalizes to world-scale populations in a feedforward manner, enabling efficient inference. Inspired by the success of large language models and vision foundation models, we present, for the first time, a pre/post-training paradigm for 3D avatar modeling at scale: we pretrain on 1M in-the-wild videos to learn broad priors over appearance and geometry, then post-train on high-quality curated data to enhance expressivity and fidelity. LCA generalizes across hair styles, clothing, and demographics while providing precise, fine-grained facial expressions and finger-level articulation control, with strong identity preservation. Notably, we observe emergent generalization to relightability and loose garment support to unconstrained inputs, and zero-shot robustness to stylized imagery, despite the absence of direct supervision.
AtomVLA: Scalable Post-Training for Robotic Manipulation via Predictive Latent World Models
Mar 09, 2026Vision-Language-Action (VLA) models demonstrate remarkable potential for generalizable robotic manipulation. The execution of complex multi-step behaviors in VLA models can be improved by robust instruction grounding, a critical component for effective control. However, current paradigms predominantly rely on coarse, high-level task instructions during supervised fine-tuning. This instruction grounding gap leaves models without explicit intermediate guidance, leading to severe compounding errors in long-horizon tasks. Therefore, bridging this instruction gap and providing scalable post-training for VLA models is urgent. To tackle this problem, we propose \method, the first subtask-aware VLA framework integrated with a scalable offline post-training pipeline. Our framework leverages a large language model to decompose high-level demonstrations into fine-grained atomic subtasks. This approach utilizes a pretrained predictive world model to score candidate action chunks against subtask goals in the latent space, mitigating error accumulation while significantly improving long-horizon robustness. Furthermore, this approach enables highly efficient Group Relative Policy Optimization without the prohibitive expenses associated with online rollouts on physical robots. Extensive simulations validate that our AtomVLA maintains strong robustness under perturbations. When evaluated against fundamental baseline models, it achieves an average success rate of 97.0\% on the LIBERO benchmark and 48.0\% on the LIBERO-PRO benchmark. Finally, experiments conducted in the real world using the Galaxea R1 Lite platform confirm its broad applicability across diverse tasks, especially long-horizon tasks. All datasets, checkpoints, and code will be released to the public domain following the acceptance of this work for future research.
3DGH: 3D Head Generation with Composable Hair and Face
Jun 25, 2025We present 3DGH, an unconditional generative model for 3D human heads with composable hair and face components. Unlike previous work that entangles the modeling of hair and face, we propose to separate them using a novel data representation with template-based 3D Gaussian Splatting, in which deformable hair geometry is introduced to capture the geometric variations across different hairstyles. Based on this data representation, we design a 3D GAN-based architecture with dual generators and employ a cross-attention mechanism to model the inherent correlation between hair and face. The model is trained on synthetic renderings using carefully designed objectives to stabilize training and facilitate hair-face separation. We conduct extensive experiments to validate the design choice of 3DGH, and evaluate it both qualitatively and quantitatively by comparing with several state-of-the-art 3D GAN methods, demonstrating its effectiveness in unconditional full-head image synthesis and composable 3D hairstyle editing. More details will be available on our project page: https://c-he.github.io/projects/3dgh/.
Vid2Avatar-Pro: Authentic Avatar from Videos in the Wild via Universal Prior
Mar 03, 2025We present Vid2Avatar-Pro, a method to create photorealistic and animatable 3D human avatars from monocular in-the-wild videos. Building a high-quality avatar that supports animation with diverse poses from a monocular video is challenging because the observation of pose diversity and view points is inherently limited. The lack of pose variations typically leads to poor generalization to novel poses, and avatars can easily overfit to limited input view points, producing artifacts and distortions from other views. In this work, we address these limitations by leveraging a universal prior model (UPM) learned from a large corpus of multi-view clothed human performance capture data. We build our representation on top of expressive 3D Gaussians with canonical front and back maps shared across identities. Once the UPM is learned to accurately reproduce the large-scale multi-view human images, we fine-tune the model with an in-the-wild video via inverse rendering to obtain a personalized photorealistic human avatar that can be faithfully animated to novel human motions and rendered from novel views. The experiments show that our approach based on the learned universal prior sets a new state-of-the-art in monocular avatar reconstruction by substantially outperforming existing approaches relying only on heuristic regularization or a shape prior of minimally clothed bodies (e.g., SMPL) on publicly available datasets.
LUCAS: Layered Universal Codec Avatars
Feb 27, 2025



Photorealistic 3D head avatar reconstruction faces critical challenges in modeling dynamic face-hair interactions and achieving cross-identity generalization, particularly during expressions and head movements. We present LUCAS, a novel Universal Prior Model (UPM) for codec avatar modeling that disentangles face and hair through a layered representation. Unlike previous UPMs that treat hair as an integral part of the head, our approach separates the modeling of the hairless head and hair into distinct branches. LUCAS is the first to introduce a mesh-based UPM, facilitating real-time rendering on devices. Our layered representation also improves the anchor geometry for precise and visually appealing Gaussian renderings. Experimental results indicate that LUCAS outperforms existing single-mesh and Gaussian-based avatar models in both quantitative and qualitative assessments, including evaluations on held-out subjects in zero-shot driving scenarios. LUCAS demonstrates superior dynamic performance in managing head pose changes, expression transfer, and hairstyle variations, thereby advancing the state-of-the-art in 3D head avatar reconstruction.
URAvatar: Universal Relightable Gaussian Codec Avatars
Oct 31, 2024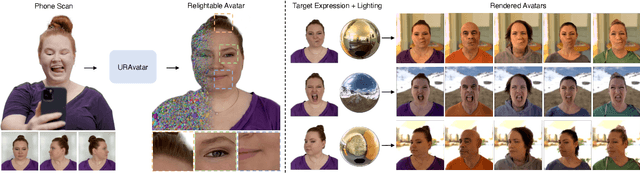

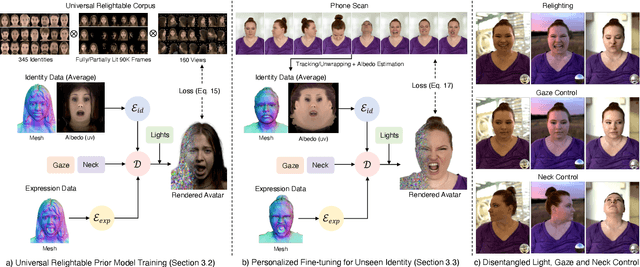
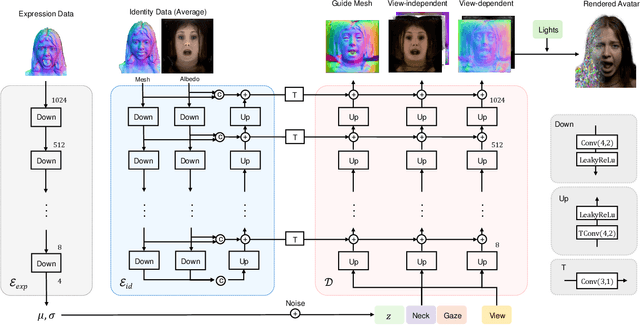
We present a new approach to creating photorealistic and relightable head avatars from a phone scan with unknown illumination. The reconstructed avatars can be animated and relit in real time with the global illumination of diverse environments. Unlike existing approaches that estimate parametric reflectance parameters via inverse rendering, our approach directly models learnable radiance transfer that incorporates global light transport in an efficient manner for real-time rendering. However, learning such a complex light transport that can generalize across identities is non-trivial. A phone scan in a single environment lacks sufficient information to infer how the head would appear in general environments. To address this, we build a universal relightable avatar model represented by 3D Gaussians. We train on hundreds of high-quality multi-view human scans with controllable point lights. High-resolution geometric guidance further enhances the reconstruction accuracy and generalization. Once trained, we finetune the pretrained model on a phone scan using inverse rendering to obtain a personalized relightable avatar. Our experiments establish the efficacy of our design, outperforming existing approaches while retaining real-time rendering capability.
A Systematic Review on Prompt Engineering in Large Language Models for K-12 STEM Education
Oct 14, 2024
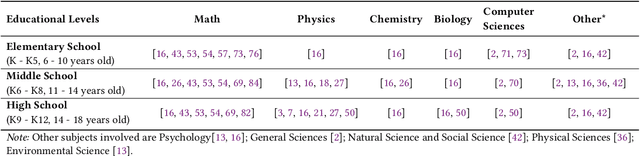
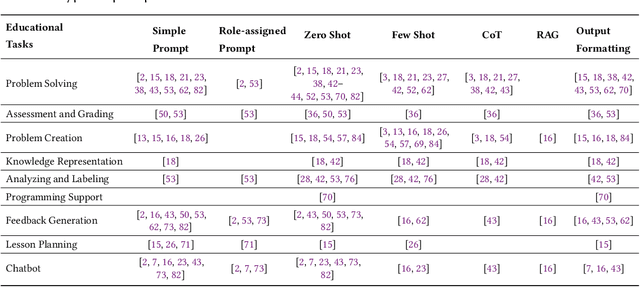
Large language models (LLMs) have the potential to enhance K-12 STEM education by improving both teaching and learning processes. While previous studies have shown promising results, there is still a lack of comprehensive understanding regarding how LLMs are effectively applied, specifically through prompt engineering-the process of designing prompts to generate desired outputs. To address this gap, our study investigates empirical research published between 2021 and 2024 that explores the use of LLMs combined with prompt engineering in K-12 STEM education. Following the PRISMA protocol, we screened 2,654 papers and selected 30 studies for analysis. Our review identifies the prompting strategies employed, the types of LLMs used, methods of evaluating effectiveness, and limitations in prior work. Results indicate that while simple and zero-shot prompting are commonly used, more advanced techniques like few-shot and chain-of-thought prompting have demonstrated positive outcomes for various educational tasks. GPT-series models are predominantly used, but smaller and fine-tuned models (e.g., Blender 7B) paired with effective prompt engineering outperform prompting larger models (e.g., GPT-3) in specific contexts. Evaluation methods vary significantly, with limited empirical validation in real-world settings.
Bridging the Gap: Studio-like Avatar Creation from a Monocular Phone Capture
Jul 28, 2024Creating photorealistic avatars for individuals traditionally involves extensive capture sessions with complex and expensive studio devices like the LightStage system. While recent strides in neural representations have enabled the generation of photorealistic and animatable 3D avatars from quick phone scans, they have the capture-time lighting baked-in, lack facial details and have missing regions in areas such as the back of the ears. Thus, they lag in quality compared to studio-captured avatars. In this paper, we propose a method that bridges this gap by generating studio-like illuminated texture maps from short, monocular phone captures. We do this by parameterizing the phone texture maps using the $W^+$ space of a StyleGAN2, enabling near-perfect reconstruction. Then, we finetune a StyleGAN2 by sampling in the $W^+$ parameterized space using a very small set of studio-captured textures as an adversarial training signal. To further enhance the realism and accuracy of facial details, we super-resolve the output of the StyleGAN2 using carefully designed diffusion model that is guided by image gradients of the phone-captured texture map. Once trained, our method excels at producing studio-like facial texture maps from casual monocular smartphone videos. Demonstrating its capabilities, we showcase the generation of photorealistic, uniformly lit, complete avatars from monocular phone captures. \href{http://shahrukhathar.github.io/2024/07/22/Bridging.html}{The project page can be found here.}
Universal Facial Encoding of Codec Avatars from VR Headsets
Jul 17, 2024



Faithful real-time facial animation is essential for avatar-mediated telepresence in Virtual Reality (VR). To emulate authentic communication, avatar animation needs to be efficient and accurate: able to capture both extreme and subtle expressions within a few milliseconds to sustain the rhythm of natural conversations. The oblique and incomplete views of the face, variability in the donning of headsets, and illumination variation due to the environment are some of the unique challenges in generalization to unseen faces. In this paper, we present a method that can animate a photorealistic avatar in realtime from head-mounted cameras (HMCs) on a consumer VR headset. We present a self-supervised learning approach, based on a cross-view reconstruction objective, that enables generalization to unseen users. We present a lightweight expression calibration mechanism that increases accuracy with minimal additional cost to run-time efficiency. We present an improved parameterization for precise ground-truth generation that provides robustness to environmental variation. The resulting system produces accurate facial animation for unseen users wearing VR headsets in realtime. We compare our approach to prior face-encoding methods demonstrating significant improvements in both quantitative metrics and qualitative results.
* SIGGRAPH 2024 (ACM Transactions on Graphics (TOG))