 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Stopping Chain-of-thoughts in Large Language Models
Sep 17, 2025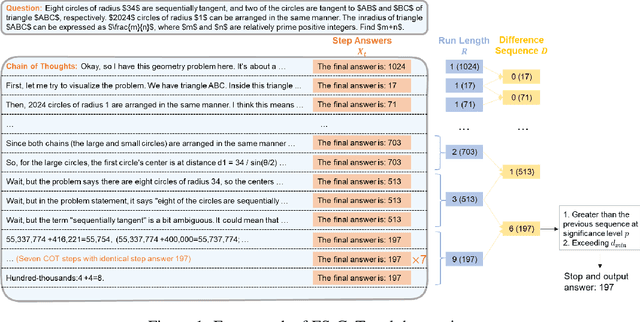
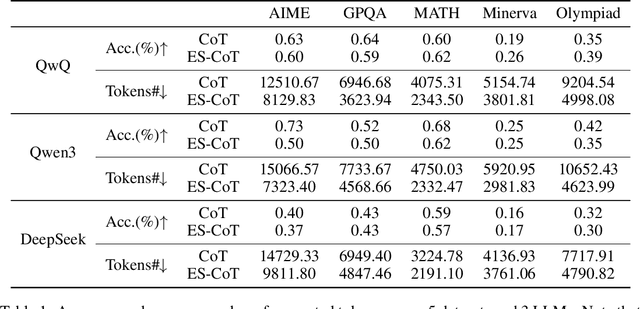
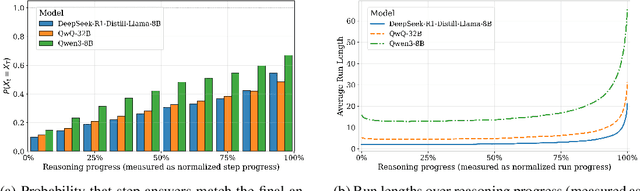
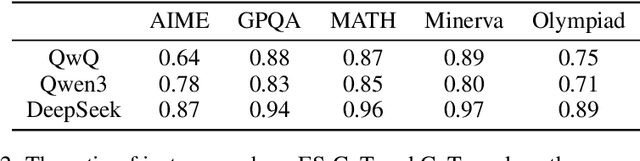
Reasoning large language models (LLMs) have demonstrated superior capacities in solving complicated problems by generating long chain-of-thoughts (CoT), but such a lengthy CoT incurs high inference costs. In this study, we introduce ES-CoT, an inference-time method that shortens CoT generation by detecting answer convergence and stopping early with minimal performance loss. At the end of each reasoning step, we prompt the LLM to output its current final answer, denoted as a step answer. We then track the run length of consecutive identical step answers as a measure of answer convergence. Once the run length exhibits a sharp increase and exceeds a minimum threshold, the generation is terminated. We provide both empirical and theoretical support for this heuristic: step answers steadily converge to the final answer, and large run-length jumps reliably mark this convergence. Experiments on five reasoning datasets across three LLMs show that ES-CoT reduces the number of inference tokens by about 41\% on average while maintaining accuracy comparable to standard CoT. Further, ES-CoT integrates seamlessly with self-consistency prompting and remains robust across hyperparameter choices, highlighting it as a practical and effective approach for efficient reasoning.
Adapting Vehicle Detectors for Aerial Imagery to Unseen Domains with Weak Supervision
Jul 28, 2025Detecting vehicles in aerial imagery is a critical task with applications in traffic monitoring, urban planning, and defense intelligence. Deep learning methods have provided state-of-the-art (SOTA) results for this application. However, a significant challenge arises when models trained on data from one geographic region fail to generalize effectively to other areas. Variability in factors such as environmental conditions, urban layouts, road networks, vehicle types, and image acquisition parameters (e.g., resolution, lighting, and angle) leads to domain shifts that degrade model performance. This paper proposes a novel method that uses generative AI to synthesize high-quality aerial images and their labels, improving detector training through data augmentation. Our key contribution is the development of a multi-stage, multi-modal knowledge transfer framework utilizing fine-tuned latent diffusion models (LDMs) to mitigate the distribution gap between the source and target environments. Extensive experiments across diverse aerial imagery domains show consistent performance improvements in AP50 over supervised learning on source domain data, weakly supervised adaptation methods, unsupervised domain adaptation methods, and open-set object detectors by 4-23%, 6-10%, 7-40%, and more than 50%, respectively. Furthermore, we introduce two newly annotated aerial datasets from New Zealand and Utah to support further research in this field. Project page is available at: https://humansensinglab.github.io/AGenDA
A Systematic Review on Prompt Engineering in Large Language Models for K-12 STEM Education
Oct 14, 2024
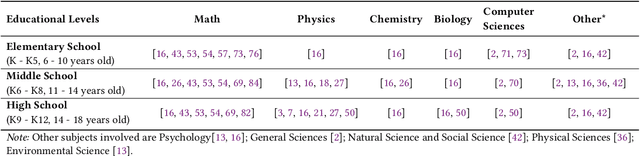
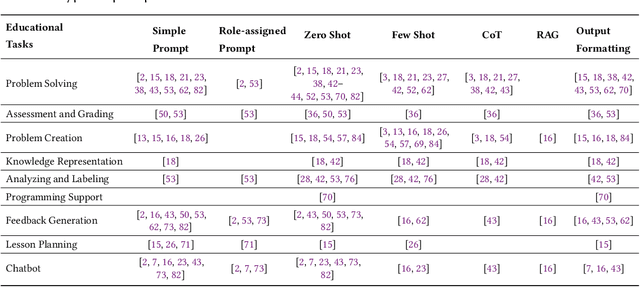
Large language models (LLMs) have the potential to enhance K-12 STEM education by improving both teaching and learning processes. While previous studies have shown promising results, there is still a lack of comprehensive understanding regarding how LLMs are effectively applied, specifically through prompt engineering-the process of designing prompts to generate desired outputs. To address this gap, our study investigates empirical research published between 2021 and 2024 that explores the use of LLMs combined with prompt engineering in K-12 STEM education. Following the PRISMA protocol, we screened 2,654 papers and selected 30 studies for analysis. Our review identifies the prompting strategies employed, the types of LLMs used, methods of evaluating effectiveness, and limitations in prior work. Results indicate that while simple and zero-shot prompting are commonly used, more advanced techniques like few-shot and chain-of-thought prompting have demonstrated positive outcomes for various educational tasks. GPT-series models are predominantly used, but smaller and fine-tuned models (e.g., Blender 7B) paired with effective prompt engineering outperform prompting larger models (e.g., GPT-3) in specific contexts. Evaluation methods vary significantly, with limited empirical validation in real-world settings.
Aligning Medical Images with General Knowledge from Large Language Models
Aug 31, 2024



Pre-trained large vision-language models (VLMs) like CLIP have revolutionized visual representation learning using natural language as supervisions, and demonstrated promising generalization ability. In this work, we propose ViP, a novel visual symptom-guided prompt learning framework for medical image analysis, which facilitates general knowledge transfer from CLIP. ViP consists of two key components: a visual symptom generator (VSG) and a dual-prompt network. Specifically, VSG aims to extract explicable visual symptoms from pre-trained large language models, while the dual-prompt network utilizes these visual symptoms to guide the training on two learnable prompt modules, i.e., context prompt and merge prompt, which effectively adapts our framework to medical image analysis via large VLMs. Extensive experimental results demonstrate that ViP can outperform state-of-the-art methods on two challenging datasets.
Applying and Evaluating Large Language Models in Mental Health Care: A Scoping Review of Human-Assessed Generative Tasks
Aug 21, 2024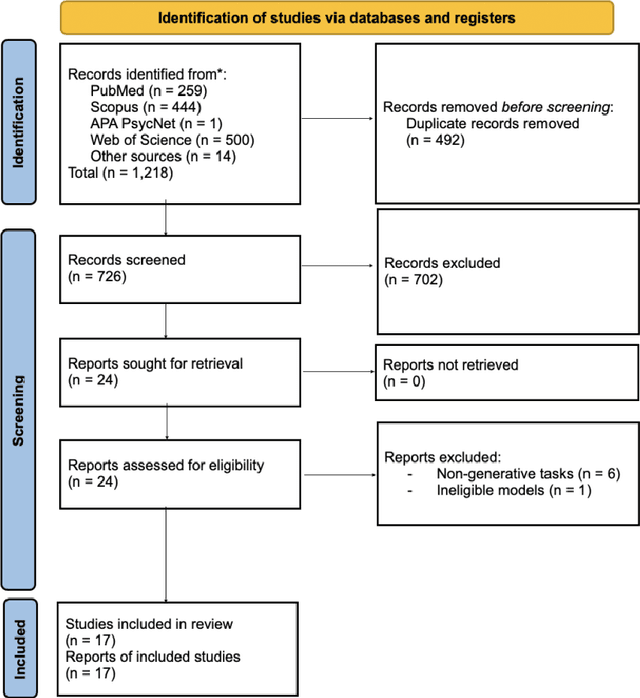


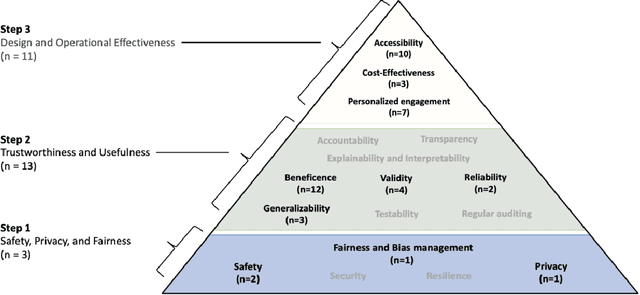
Large language models (LLMs) are emerging as promising tools for mental health care, offering scalable support through their ability to generate human-like responses. However, the effectiveness of these models in clinical settings remains unclear. This scoping review aimed to assess the current generative applications of LLMs in mental health care, focusing on studies where these models were tested with human participants in real-world scenarios. A systematic search across APA PsycNet, Scopus, PubMed, and Web of Science identified 726 unique articles, of which 17 met the inclusion criteria. These studies encompassed applications such as clinical assistance, counseling, therapy, and emotional support. However, the evaluation methods were often non-standardized, with most studies relying on ad hoc scales that limit comparability and robustness. Privacy, safety, and fairness were also frequently underexplored. Moreover, reliance on proprietary models, such as OpenAI's GPT series, raises concerns about transparency and reproducibility. While LLMs show potential in expanding mental health care access, especially in underserved areas, the current evidence does not fully support their use as standalone interventions. More rigorous, standardized evaluations and ethical oversight are needed to ensure these tools can be safely and effectively integrated into clinical practice.
A Watermark for Low-entropy and Unbiased Generation in Large Language Models
May 23, 2024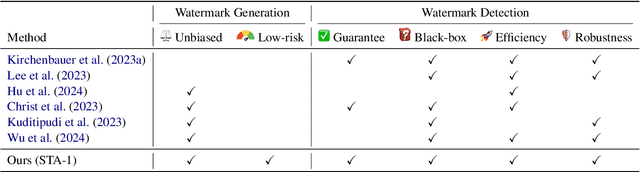
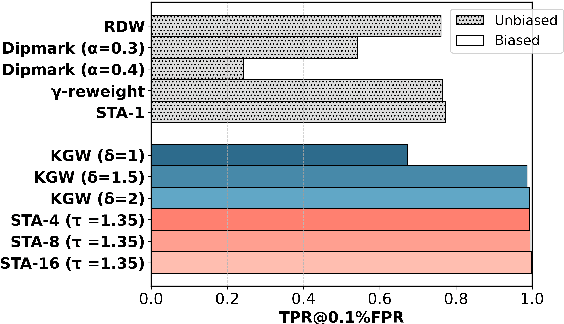
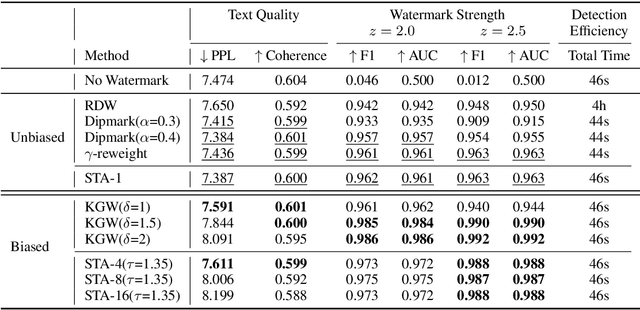
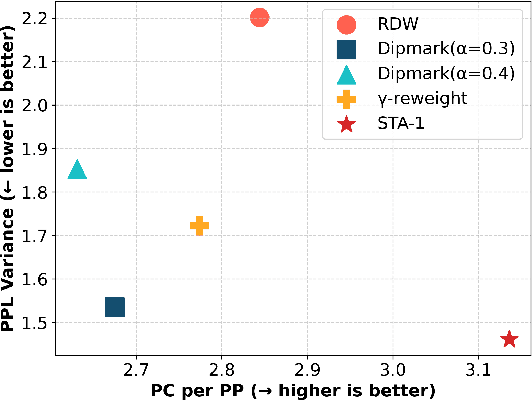
Recent advancements in large language models (LLMs) have highlighted the risk of misuse, raising concerns about accurately detecting LLM-generated content. A viable solution for the detection problem is to inject imperceptible identifiers into LLMs, known as watermarks. Previous work demonstrates that unbiased watermarks ensure unforgeability and preserve text quality by maintaining the expectation of the LLM output probability distribution. However, previous unbiased watermarking methods are impractical for local deployment because they rely on accesses to white-box LLMs and input prompts during detection. Moreover, these methods fail to provide statistical guarantees for the type II error of watermark detection. This study proposes the Sampling One Then Accepting (STA-1) method, an unbiased watermark that does not require access to LLMs nor prompts during detection and has statistical guarantees for the type II error. Moreover, we propose a novel tradeoff between watermark strength and text quality in unbiased watermarks. We show that in low-entropy scenarios, unbiased watermarks face a tradeoff between watermark strength and the risk of unsatisfactory outputs. Experimental results on low-entropy and high-entropy datasets demonstrate that STA-1 achieves text quality and watermark strength comparable to existing unbiased watermarks, with a low risk of unsatisfactory outputs. Implementation codes for this study are available online.
Federated Adaptation for Foundation Model-based Recommendations
May 08, 2024



With the recent success of large language models, particularly foundation models with generalization abilities, applying foundation models for recommendations becomes a new paradigm to improve existing recommendation systems. It becomes a new open challenge to enable the foundation model to capture user preference changes in a timely manner with reasonable communication and computation costs while preserving privacy. This paper proposes a novel federated adaptation mechanism to enhance the foundation model-based recommendation system in a privacy-preserving manner. Specifically, each client will learn a lightweight personalized adapter using its private data. The adapter then collaborates with pre-trained foundation models to provide recommendation service efficiently with fine-grained manners. Importantly, users' private behavioral data remains secure as it is not shared with the server. This data localization-based privacy preservation is embodied via the federated learning framework. The model can ensure that shared knowledge is incorporated into all adapters while simultaneously preserving each user's personal preferences. Experimental results on four benchmark datasets demonstrate our method's superior performance. Implementation code is available to ease reproducibility.
A Non-Uniform Low-Light Image Enhancement Method with Multi-Scale Attention Transformer and Luminance Consistency Loss
Dec 27, 2023Low-light image enhancement aims to improve the perception of images collected in dim environments and provide high-quality data support for image recognition tasks. When dealing with photos captured under non-uniform illumination, existing methods cannot adaptively extract the differentiated luminance information, which will easily cause over-exposure and under-exposure. From the perspective of unsupervised learning, we propose a multi-scale attention Transformer named MSATr, which sufficiently extracts local and global features for light balance to improve the visual quality. Specifically, we present a multi-scale window division scheme, which uses exponential sequences to adjust the window size of each layer. Within different-sized windows, the self-attention computation can be refined, ensuring the pixel-level feature processing capability of the model. For feature interaction across windows, a global transformer branch is constructed to provide comprehensive brightness perception and alleviate exposure problems. Furthermore, we propose a loop training strategy, using the diverse images generated by weighted mixing and a luminance consistency loss to improve the model's generalization ability effectively. Extensive experiments on several benchmark datasets quantitatively and qualitatively prove that our MSATr is superior to state-of-the-art low-light image enhancement methods, and the enhanced images have more natural brightness and outstanding details. The code is released at https://github.com/fang001021/MSATr.
Bias of AI-Generated Content: An Examination of News Produced by Large Language Models
Sep 19, 2023Large language models (LLMs) have the potential to transform our lives and work through the content they generate, known as AI-Generated Content (AIGC). To harness this transformation, we need to understand the limitations of LLMs. Here, we investigate the bias of AIGC produced by seven representative LLMs, including ChatGPT and LLaMA. We collect news articles from The New York Times and Reuters, both known for their dedication to provide unbiased news. We then apply each examined LLM to generate news content with headlines of these news articles as prompts, and evaluate the gender and racial biases of the AIGC produced by the LLM by comparing the AIGC and the original news articles. We further analyze the gender bias of each LLM under biased prompts by adding gender-biased messages to prompts constructed from these news headlines. Our study reveals that the AIGC produced by each examined LLM demonstrates substantial gender and racial biases. Moreover, the AIGC generated by each LLM exhibits notable discrimination against females and individuals of the Black race. Among the LLMs, the AIGC generated by ChatGPT demonstrates the lowest level of bias, and ChatGPT is the sole model capable of declining content generation when provided with biased prompts.
Proactive Resource Request for Disaster Response: A Deep Learning-based Optimization Model
Jul 31, 2023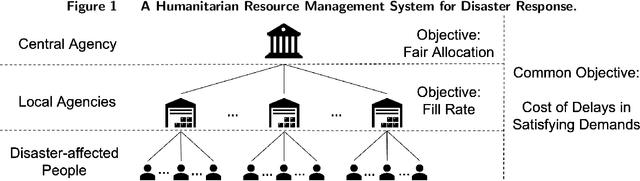

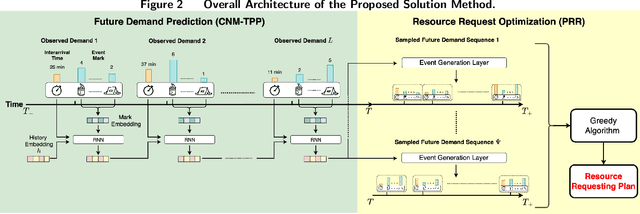
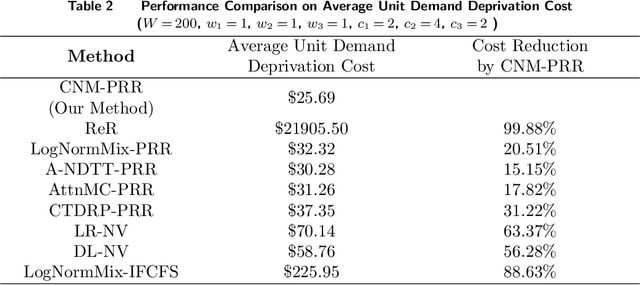
Disaster response is critical to save lives and reduce damages in the aftermath of a disaster. Fundamental to disaster response operations is the management of disaster relief resources. To this end, a local agency (e.g., a local emergency resource distribution center) collects demands from local communities affected by a disaster, dispatches available resources to meet the demands, and requests more resources from a central emergency management agency (e.g., Federal Emergency Management Agency in the U.S.). Prior resource management research for disaster response overlooks the problem of deciding optimal quantities of resources requested by a local agency. In response to this research gap, we define a new resource management problem that proactively decides optimal quantities of requested resources by considering both currently unfulfilled demands and future demands. To solve the problem, we take salient characteristics of the problem into consideration and develop a novel deep learning method for future demand prediction. We then formulate the problem as a stochastic optimization model, analyze key properties of the model, and propose an effective solution method to the problem based on the analyzed properties. We demonstrate the superior performance of our method over prevalent existing methods using both real world and simulated data. We also show its superiority over prevalent existing methods in a multi-stakeholder and multi-objective setting through simulations.