 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Watermark for Low-entropy and Unbiased Generation in Large Language Models
May 23, 2024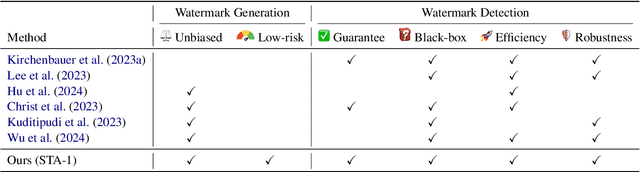
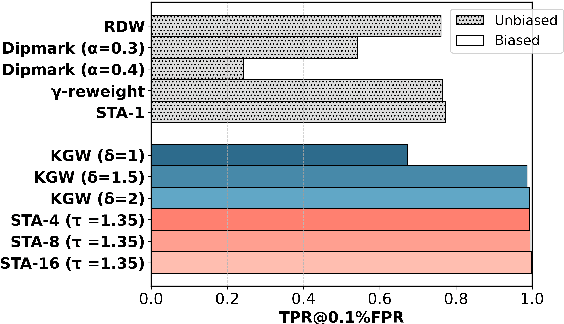
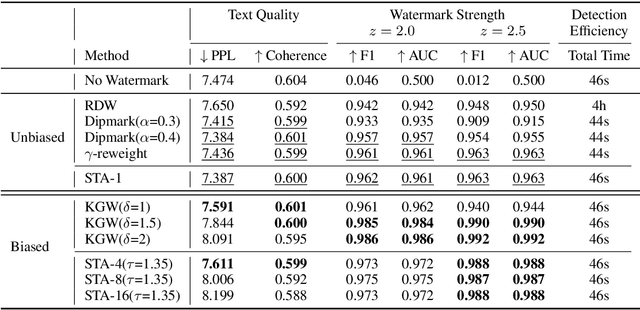
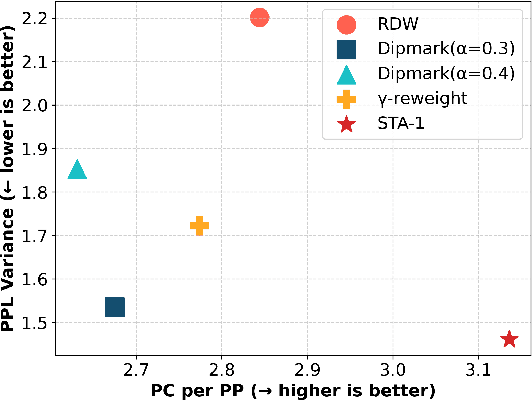
Recent advancements in large language models (LLMs) have highlighted the risk of misuse, raising concerns about accurately detecting LLM-generated content. A viable solution for the detection problem is to inject imperceptible identifiers into LLMs, known as watermarks. Previous work demonstrates that unbiased watermarks ensure unforgeability and preserve text quality by maintaining the expectation of the LLM output probability distribution. However, previous unbiased watermarking methods are impractical for local deployment because they rely on accesses to white-box LLMs and input prompts during detection. Moreover, these methods fail to provide statistical guarantees for the type II error of watermark detection. This study proposes the Sampling One Then Accepting (STA-1) method, an unbiased watermark that does not require access to LLMs nor prompts during detection and has statistical guarantees for the type II error. Moreover, we propose a novel tradeoff between watermark strength and text quality in unbiased watermarks. We show that in low-entropy scenarios, unbiased watermarks face a tradeoff between watermark strength and the risk of unsatisfactory outputs. Experimental results on low-entropy and high-entropy datasets demonstrate that STA-1 achieves text quality and watermark strength comparable to existing unbiased watermarks, with a low risk of unsatisfactory outputs. Implementation codes for this study are available online.
AutoSUM: Automating Feature Extraction and Multi-user Preference Simulation for Entity Summarization
May 25, 2020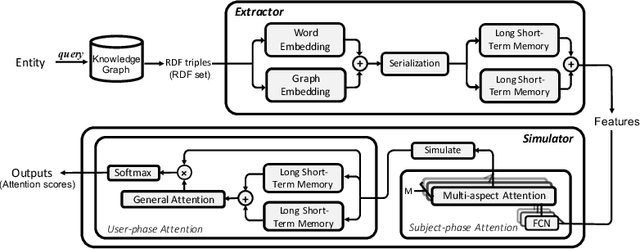
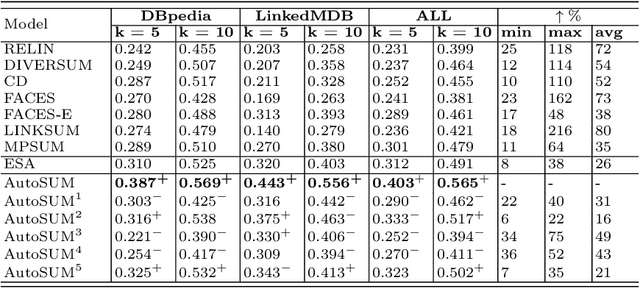
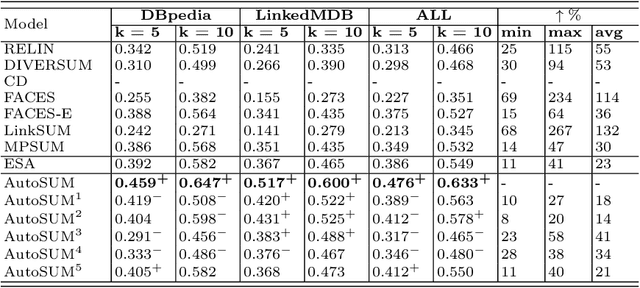
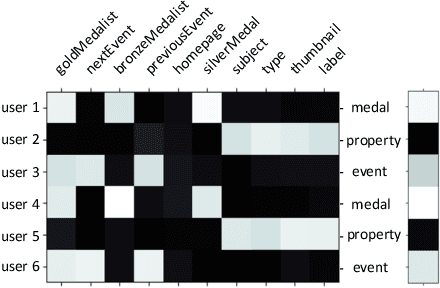
Withthegrowthofknowledgegraphs, entity descriptions are becoming extremely lengthy. Entity summarization task, aiming to generate diverse, comprehensive, and representative summaries for entities, has received increasing interest recently. In most previous methods, features are usually extracted by the handcrafted templates. Then the feature selection and multi-user preference simulation take place, depending too much on human expertise. In this paper, a novel integration method called AutoSUM is proposed for automatic feature extraction and multi-user preference simulation to overcome the drawbacks of previous methods. There are two modules in AutoSUM: extractor and simulator. The extractor module operates automatic feature extraction based on a BiLSTM with a combined input representation including word embeddings and graph embeddings. Meanwhile, the simulator module automates multi-user preference simulation based on a well-designed two-phase attention mechanism (i.e., entity-phase attention and user-phase attention). Experimental results demonstrate that AutoSUM produces state-of-the-art performance on two widely used datasets (i.e., DBpedia and LinkedMDB) in both F-measure and MAP.
ESA: Entity Summarization with Attention
May 25, 2019
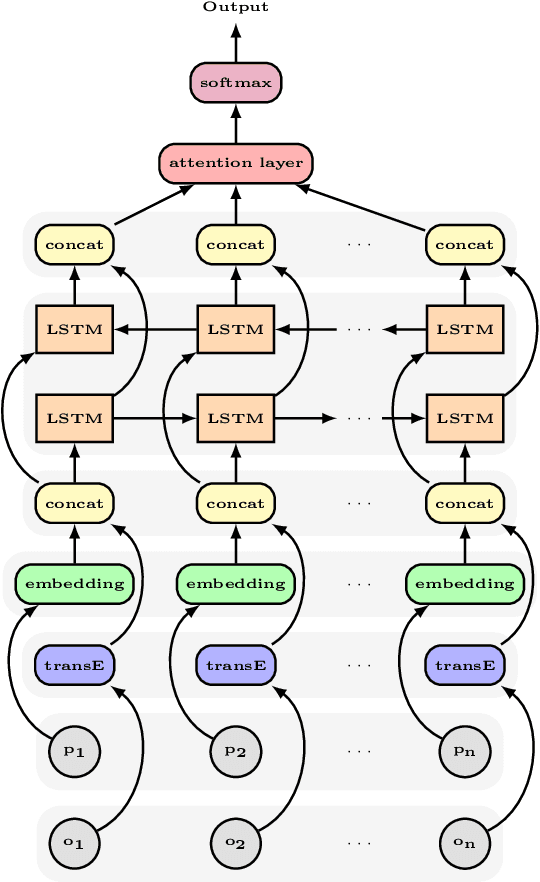
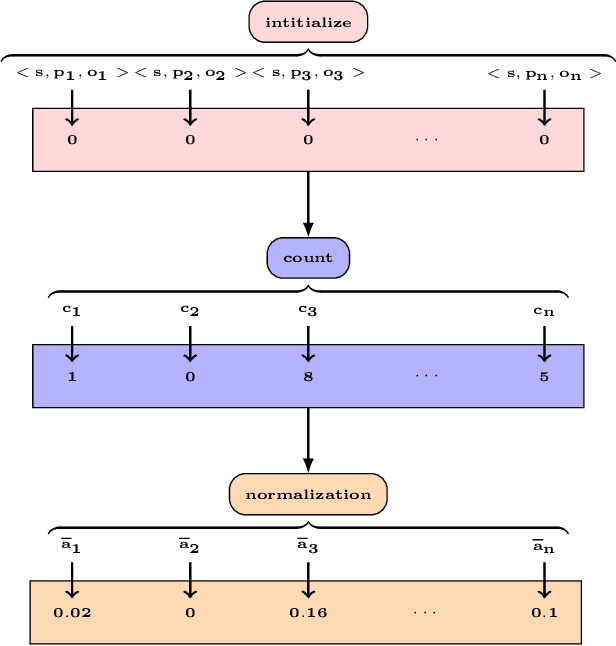
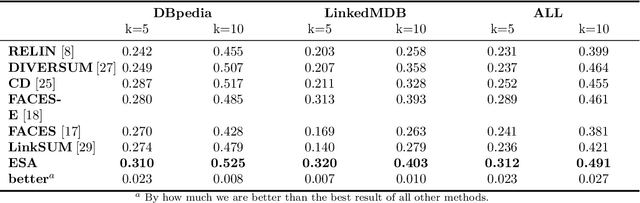
Entity summarization aims at creating brief but informative descriptions of entities from knowledge graphs. While previous work mostly focused on traditional techniques such as clustering algorithms and graph models, we ask how to apply deep learning methods into this task. In this paper we propose ESA, a neural network with supervised attention mechanisms for entity summarization. Specifically, we calculate attention weights for facts in each entity, and rank facts to generate reliable summaries. We explore techniques to solve difficult learning problems presented by the ESA, and demonstrate the effectiveness of our model in comparison with the state-of-the-art methods. Experimental results show that our model improves the quality of the entity summaries in both F-measure and MAP.