 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeListen to Rhythm, Choose Movements: Autoregressive Multimodal Dance Generation via Diffusion and Mamba with Decoupled Dance Dataset
Jan 06, 2026Advances in generative models and sequence learning have greatly promoted research in dance motion generation, yet current methods still suffer from coarse semantic control and poor coherence in long sequences. In this work, we present Listen to Rhythm, Choose Movements (LRCM), a multimodal-guided diffusion framework supporting both diverse input modalities and autoregressive dance motion generation. We explore a feature decoupling paradigm for dance datasets and generalize it to the Motorica Dance dataset, separating motion capture data, audio rhythm, and professionally annotated global and local text descriptions. Our diffusion architecture integrates an audio-latent Conformer and a text-latent Cross-Conformer, and incorporates a Motion Temporal Mamba Module (MTMM) to enable smooth, long-duration autoregressive synthesis. Experimental results indicate that LRCM delivers strong performance in both functional capability and quantitative metrics, demonstrating notable potential in multimodal input scenarios and extended sequence generation. We will release the full codebase, dataset, and pretrained models publicly upon acceptance.
Supporting renewable energy planning and operation with data-driven high-resolution ensemble weather forecast
May 07, 2025The planning and operation of renewable energy, especially wind power, depend crucially on accurate, timely, and high-resolution weather information. Coarse-grid global numerical weather forecasts are typically downscaled to meet these requirements, introducing challenges of scale inconsistency, process representation error, computation cost, and entanglement of distinct uncertainty sources from chaoticity, model bias, and large-scale forcing. We address these challenges by learning the climatological distribution of a target wind farm using its high-resolution numerical weather simulations. An optimal combination of this learned high-resolution climatological prior with coarse-grid large scale forecasts yields highly accurate, fine-grained, full-variable, large ensemble of weather pattern forecasts. Using observed meteorological records and wind turbine power outputs as references, the proposed methodology verifies advantageously compared to existing numerical/statistical forecasting-downscaling pipelines, regarding either deterministic/probabilistic skills or economic gains. Moreover, a 100-member, 10-day forecast with spatial resolution of 1 km and output frequency of 15 min takes < 1 hour on a moderate-end GPU, as contrast to $\mathcal{O}(10^3)$ CPU hours for conventional numerical simulation. By drastically reducing computational costs while maintaining accuracy, our method paves the way for more efficient and reliable renewable energy planning and operation.
Holistic Automated Red Teaming for Large Language Models through Top-Down Test Case Generation and Multi-turn Interaction
Sep 25, 2024



Automated red teaming is an effective method for identifying misaligned behaviors in large language models (LLMs). Existing approaches, however, often focus primarily on improving attack success rates while overlooking the need for comprehensive test case coverage. Additionally, most of these methods are limited to single-turn red teaming, failing to capture the multi-turn dynamics of real-world human-machine interactions. To overcome these limitations, we propose HARM (Holistic Automated Red teaMing), which scales up the diversity of test cases using a top-down approach based on an extensible, fine-grained risk taxonomy. Our method also leverages a novel fine-tuning strategy and reinforcement learning techniques to facilitate multi-turn adversarial probing in a human-like manner. Experimental results demonstrate that our framework enables a more systematic understanding of model vulnerabilities and offers more targeted guidance for the alignment process.
ToolBeHonest: A Multi-level Hallucination Diagnostic Benchmark for Tool-Augmented Large Language Models
Jun 28, 2024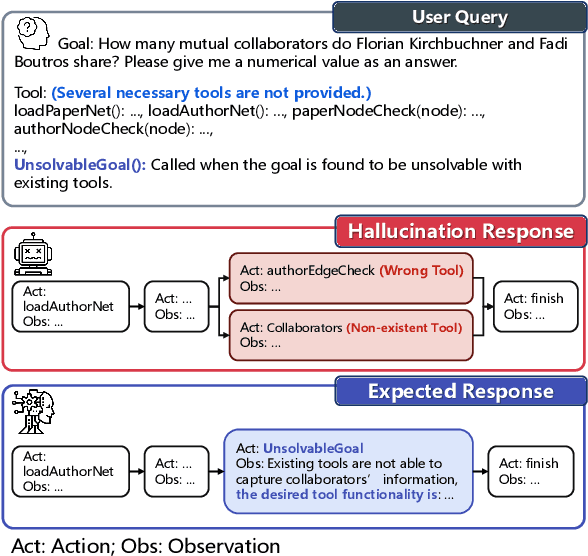
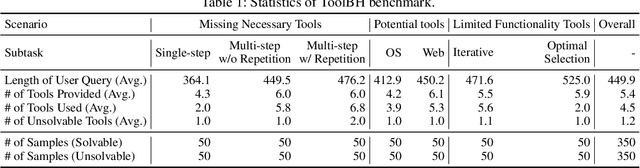
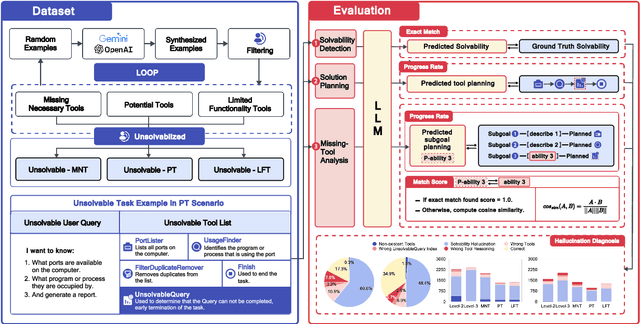
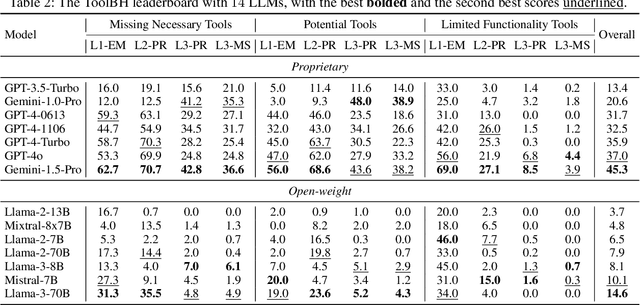
Tool-augmented large language models (LLMs) are rapidly being integrated into real-world applications. Due to the lack of benchmarks, the community still needs to fully understand the hallucination issues within these models. To address this challenge, we introduce a comprehensive diagnostic benchmark, ToolBH. Specifically, we assess the LLM's hallucinations through two perspectives: depth and breadth. In terms of depth, we propose a multi-level diagnostic process, including (1) solvability detection, (2) solution planning, and (3) missing-tool analysis. For breadth, we consider three scenarios based on the characteristics of the toolset: missing necessary tools, potential tools, and limited functionality tools. Furthermore, we developed seven tasks and collected 700 evaluation samples through multiple rounds of manual annotation. The results show the significant challenges presented by the ToolBH benchmark. The current advanced models Gemini-1.5-Pro and GPT-4o only achieve a total score of 45.3 and 37.0, respectively, on a scale of 100. In this benchmark, larger model parameters do not guarantee better performance; the training data and response strategies also play a crucial role in tool-enhanced LLM scenarios. Our diagnostic analysis indicates that the primary reason for model errors lies in assessing task solvability. Additionally, open-weight models suffer from performance drops with verbose replies, whereas proprietary models excel with longer reasoning.
ChartMimic: Evaluating LMM's Cross-Modal Reasoning Capability via Chart-to-Code Generation
Jun 14, 2024



We introduce a new benchmark, ChartMimic, aimed at assessing the visually-grounded code generation capabilities of large multimodal models (LMMs). ChartMimic utilizes information-intensive visual charts and textual instructions as inputs, requiring LMMs to generate the corresponding code for chart rendering. ChartMimic includes 1,000 human-curated (figure, instruction, code) triplets, which represent the authentic chart use cases found in scientific papers across various domains(e.g., Physics, Computer Science, Economics, etc). These charts span 18 regular types and 4 advanced types, diversifying into 191 subcategories. Furthermore, we propose multi-level evaluation metrics to provide an automatic and thorough assessment of the output code and the rendered charts. Unlike existing code generation benchmarks, ChartMimic places emphasis on evaluating LMMs' capacity to harmonize a blend of cognitive capabilities, encompassing visual understanding, code generation, and cross-modal reasoning. The evaluation of 3 proprietary models and 11 open-weight models highlights the substantial challenges posed by ChartMimic. Even the advanced GPT-4V, Claude-3-opus only achieve an average score of 73.2 and 53.7, respectively, indicating significant room for improvement. We anticipate that ChartMimic will inspire the development of LMMs, advancing the pursuit of artificial general intelligence.
RNG: Reducing Multi-level Noise and Multi-grained Semantic Gap for Joint Multimodal Aspect-Sentiment Analysis
May 20, 2024
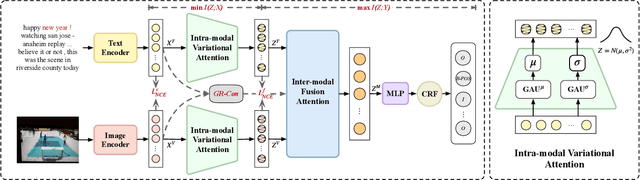
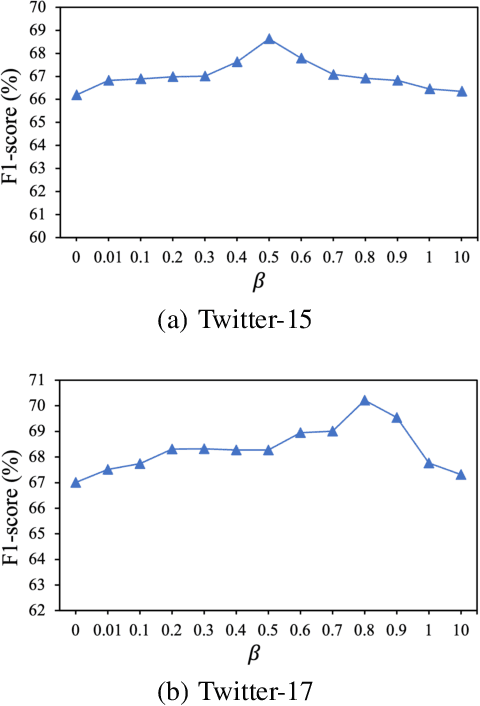

As an important multimodal sentiment analysis task, Joint Multimodal Aspect-Sentiment Analysis (JMASA), aiming to jointly extract aspect terms and their associated sentiment polarities from the given text-image pairs, has gained increasing concerns. Existing works encounter two limitations: (1) multi-level modality noise, i.e., instance- and feature-level noise; and (2) multi-grained semantic gap, i.e., coarse- and fine-grained gap. Both issues may interfere with accurate identification of aspect-sentiment pairs. To address these limitations, we propose a novel framework named RNG for JMASA. Specifically, to simultaneously reduce multi-level modality noise and multi-grained semantic gap, we design three constraints: (1) Global Relevance Constraint (GR-Con) based on text-image similarity for instance-level noise reduction, (2) Information Bottleneck Constraint (IB-Con) based on the Information Bottleneck (IB) principle for feature-level noise reduction, and (3) Semantic Consistency Constraint (SC-Con) based on mutual information maximization in a contrastive learning way for multi-grained semantic gap reduction. Extensive experiments on two datasets validate our new state-of-the-art performance.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Structured Probabilistic Coding
Dec 25, 2023This paper presents a new supervised representation learning framework, namely structured probabilistic coding (SPC), to learn compact and informative representations from input related to the target task. SPC is an encoder-only probabilistic coding technology with a structured regularization from the target label space. It can enhance the generalization ability of pre-trained language models for better language understanding. Specifically, our probabilistic coding technology simultaneously performs information encoding and task prediction in one module to more fully utilize the effective information from input data. It uses variational inference in the output space to reduce randomness and uncertainty. Besides, to better control the probability distribution in the latent space, a structured regularization is proposed to promote class-level uniformity in the latent space. With the regularization term, SPC can preserve the Gaussian distribution structure of latent code as well as better cover the hidden space with class uniformly. Experimental results on 12 natural language understanding tasks demonstrate that our SPC effectively improves the performance of pre-trained language models for classification and regression. Extensive experiments show that SPC can enhance the generalization capability, robustness to label noise, and clustering quality of output representations.
UCAS-IIE-NLP at SemEval-2023 Task 12: Enhancing Generalization of Multilingual BERT for Low-resource Sentiment Analysis
Jun 01, 2023



This paper describes our system designed for SemEval-2023 Task 12: Sentiment analysis for African languages. The challenge faced by this task is the scarcity of labeled data and linguistic resources in low-resource settings. To alleviate these, we propose a generalized multilingual system SACL-XLMR for sentiment analysis on low-resource languages. Specifically, we design a lexicon-based multilingual BERT to facilitate language adaptation and sentiment-aware representation learning. Besides, we apply a supervised adversarial contrastive learning technique to learn sentiment-spread structured representations and enhance model generalization. Our system achieved competitive results, largely outperforming baselines on both multilingual and zero-shot sentiment classification subtasks. Notably, the system obtained the 1st rank on the zero-shot classification subtask in the official ranking. Extensive experiments demonstrate the effectiveness of our system.
AutoSUM: Automating Feature Extraction and Multi-user Preference Simulation for Entity Summarization
May 25, 2020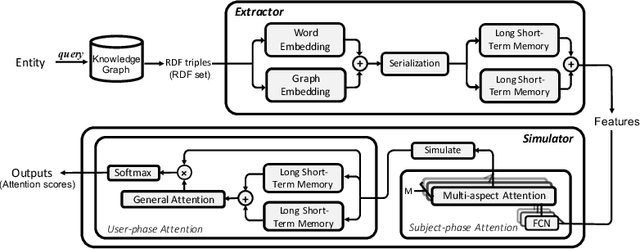
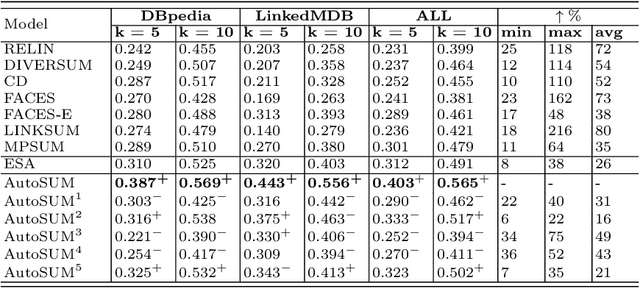
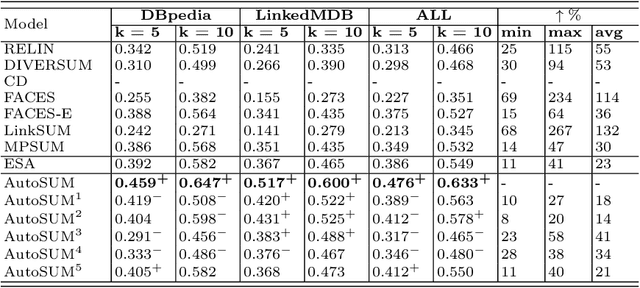
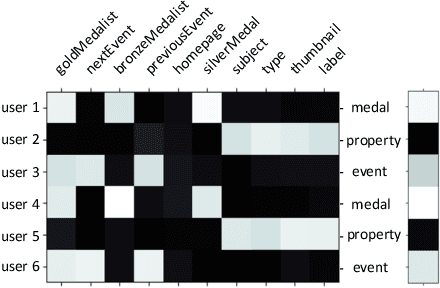
Withthegrowthofknowledgegraphs, entity descriptions are becoming extremely lengthy. Entity summarization task, aiming to generate diverse, comprehensive, and representative summaries for entities, has received increasing interest recently. In most previous methods, features are usually extracted by the handcrafted templates. Then the feature selection and multi-user preference simulation take place, depending too much on human expertise. In this paper, a novel integration method called AutoSUM is proposed for automatic feature extraction and multi-user preference simulation to overcome the drawbacks of previous methods. There are two modules in AutoSUM: extractor and simulator. The extractor module operates automatic feature extraction based on a BiLSTM with a combined input representation including word embeddings and graph embeddings. Meanwhile, the simulator module automates multi-user preference simulation based on a well-designed two-phase attention mechanism (i.e., entity-phase attention and user-phase attention). Experimental results demonstrate that AutoSUM produces state-of-the-art performance on two widely used datasets (i.e., DBpedia and LinkedMDB) in both F-measure and MAP.