 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRNG: Reducing Multi-level Noise and Multi-grained Semantic Gap for Joint Multimodal Aspect-Sentiment Analysis
Paper and Code
May 20, 2024
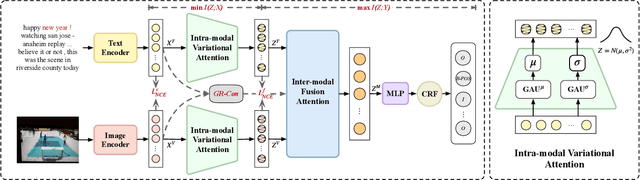

As an important multimodal sentiment analysis task, Joint Multimodal Aspect-Sentiment Analysis (JMASA), aiming to jointly extract aspect terms and their associated sentiment polarities from the given text-image pairs, has gained increasing concerns. Existing works encounter two limitations: (1) multi-level modality noise, i.e., instance- and feature-level noise; and (2) multi-grained semantic gap, i.e., coarse- and fine-grained gap. Both issues may interfere with accurate identification of aspect-sentiment pairs. To address these limitations, we propose a novel framework named RNG for JMASA. Specifically, to simultaneously reduce multi-level modality noise and multi-grained semantic gap, we design three constraints: (1) Global Relevance Constraint (GR-Con) based on text-image similarity for instance-level noise reduction, (2) Information Bottleneck Constraint (IB-Con) based on the Information Bottleneck (IB) principle for feature-level noise reduction, and (3) Semantic Consistency Constraint (SC-Con) based on mutual information maximization in a contrastive learning way for multi-grained semantic gap reduction. Extensive experiments on two datasets validate our new state-of-the-art performance.