 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreaming when Necessary: Advancing World Action Models with Adaptive Multi-Modal Reasoning
Jun 05, 2026World Action Models (WAMs) offer a promising approach to embodied intelligence, yet existing methods rely heavily on video prediction as action priors and lack adaptive multimodal reasoning, limiting their effectiveness on long-horizon, complex tasks. We observe that WAMs require different multimodal reasoning modes under different execution contexts: textual reasoning is essential during task transitions to guide high-level action prediction, while visual reasoning is critical during fine-grained manipulation for precise control. Motivated by this observation, we propose \textbf{AdaWAM}, a world action model with adaptive multimodal reasoning abilities. AdaWAM integrates a lightweight dynamic router that autonomously triggers textual or visual reasoning as needed during task execution. Experiments on both simulated and real-world embodied tasks show that AdaWAM substantially improves inference efficiency while outperforming state-of-the-art embodied policies. Codes and demos are available at: https://adawam.github.io/.
WorldArena: A Unified Benchmark for Evaluating Perception and Functional Utility of Embodied World Models
Feb 09, 2026While world models have emerged as a cornerstone of embodied intelligence by enabling agents to reason about environmental dynamics through action-conditioned prediction, their evaluation remains fragmented. Current evaluation of embodied world models has largely focused on perceptual fidelity (e.g., video generation quality), overlooking the functional utility of these models in downstream decision-making tasks. In this work, we introduce WorldArena, a unified benchmark designed to systematically evaluate embodied world models across both perceptual and functional dimensions. WorldArena assesses models through three dimensions: video perception quality, measured with 16 metrics across six sub-dimensions; embodied task functionality, which evaluates world models as data engines, policy evaluators, and action planners integrating with subjective human evaluation. Furthermore, we propose EWMScore, a holistic metric integrating multi-dimensional performance into a single interpretable index. Through extensive experiments on 14 representative models, we reveal a significant perception-functionality gap, showing that high visual quality does not necessarily translate into strong embodied task capability. WorldArena benchmark with the public leaderboard is released at https://worldarena.ai, providing a framework for tracking progress toward truly functional world models in embodied AI.
Aerial World Model for Long-horizon Visual Generation and Navigation in 3D Space
Dec 26, 2025Unmanned aerial vehicles (UAVs) have emerged as powerful embodied agents. One of the core abilities is autonomous navigation in large-scale three-dimensional environments. Existing navigation policies, however, are typically optimized for low-level objectives such as obstacle avoidance and trajectory smoothness, lacking the ability to incorporate high-level semantics into planning. To bridge this gap, we propose ANWM, an aerial navigation world model that predicts future visual observations conditioned on past frames and actions, thereby enabling agents to rank candidate trajectories by their semantic plausibility and navigational utility. ANWM is trained on 4-DoF UAV trajectories and introduces a physics-inspired module: Future Frame Projection (FFP), which projects past frames into future viewpoints to provide coarse geometric priors. This module mitigates representational uncertainty in long-distance visual generation and captures the mapping between 3D trajectories and egocentric observations. Empirical results demonstrate that ANWM significantly outperforms existing world models in long-distance visual forecasting and improves UAV navigation success rates in large-scale environments.
AgentRecBench: Benchmarking LLM Agent-based Personalized Recommender Systems
May 26, 2025



The emergence of agentic recommender systems powered by Large Language Models (LLMs) represents a paradigm shift in personalized recommendations, leveraging LLMs' advanced reasoning and role-playing capabilities to enable autonomous, adaptive decision-making. Unlike traditional recommendation approaches, agentic recommender systems can dynamically gather and interpret user-item interactions from complex environments, generating robust recommendation strategies that generalize across diverse scenarios. However, the field currently lacks standardized evaluation protocols to systematically assess these methods. To address this critical gap, we propose: (1) an interactive textual recommendation simulator incorporating rich user and item metadata and three typical evaluation scenarios (classic, evolving-interest, and cold-start recommendation tasks); (2) a unified modular framework for developing and studying agentic recommender systems; and (3) the first comprehensive benchmark comparing 10 classical and agentic recommendation methods. Our findings demonstrate the superiority of agentic systems and establish actionable design guidelines for their core components. The benchmark environment has been rigorously validated through an open challenge and remains publicly available with a continuously maintained leaderboard~\footnote[2]{https://tsinghua-fib-lab.github.io/AgentSocietyChallenge/pages/overview.html}, fostering ongoing community engagement and reproducible research. The benchmark is available at: \hyperlink{https://huggingface.co/datasets/SGJQovo/AgentRecBench}{https://huggingface.co/datasets/SGJQovo/AgentRecBench}.
Distributed Quantum Neural Networks on Distributed Photonic Quantum Computing
May 13, 2025We introduce a distributed quantum-classical framework that synergizes photonic quantum neural networks (QNNs) with matrix-product-state (MPS) mapping to achieve parameter-efficient training of classical neural networks. By leveraging universal linear-optical decompositions of $M$-mode interferometers and photon-counting measurement statistics, our architecture generates neural parameters through a hybrid quantum-classical workflow: photonic QNNs with $M(M+1)/2$ trainable parameters produce high-dimensional probability distributions that are mapped to classical network weights via an MPS model with bond dimension $\chi$. Empirical validation on MNIST classification demonstrates that photonic QT achieves an accuracy of $95.50\% \pm 0.84\%$ using 3,292 parameters ($\chi = 10$), compared to $96.89\% \pm 0.31\%$ for classical baselines with 6,690 parameters. Moreover, a ten-fold compression ratio is achieved at $\chi = 4$, with a relative accuracy loss of less than $3\%$. The framework outperforms classical compression techniques (weight sharing/pruning) by 6--12\% absolute accuracy while eliminating quantum hardware requirements during inference through classical deployment of compressed parameters. Simulations incorporating realistic photonic noise demonstrate the framework's robustness to near-term hardware imperfections. Ablation studies confirm quantum necessity: replacing photonic QNNs with random inputs collapses accuracy to chance level ($10.0\% \pm 0.5\%$). Photonic quantum computing's room-temperature operation, inherent scalability through spatial-mode multiplexing, and HPC-integrated architecture establish a practical pathway for distributed quantum machine learning, combining the expressivity of photonic Hilbert spaces with the deployability of classical neural networks.
AgentSociety Challenge: Designing LLM Agents for User Modeling and Recommendation on Web Platforms
Feb 26, 2025The AgentSociety Challenge is the first competition in the Web Conference that aims to explore the potential of Large Language Model (LLM) agents in modeling user behavior and enhancing recommender systems on web platforms. The Challenge consists of two tracks: the User Modeling Track and the Recommendation Track. Participants are tasked to utilize a combined dataset from Yelp, Amazon, and Goodreads, along with an interactive environment simulator, to develop innovative LLM agents. The Challenge has attracted 295 teams across the globe and received over 1,400 submissions in total over the course of 37 official competition days. The participants have achieved 21.9% and 20.3% performance improvement for Track 1 and Track 2 in the Development Phase, and 9.1% and 15.9% in the Final Phase, representing a significant accomplishment. This paper discusses the detailed designs of the Challenge, analyzes the outcomes, and highlights the most successful LLM agent designs. To support further research and development, we have open-sourced the benchmark environment at https://tsinghua-fib-lab.github.io/AgentSocietyChallenge.
Understanding World or Predicting Future? A Comprehensive Survey of World Models
Nov 21, 2024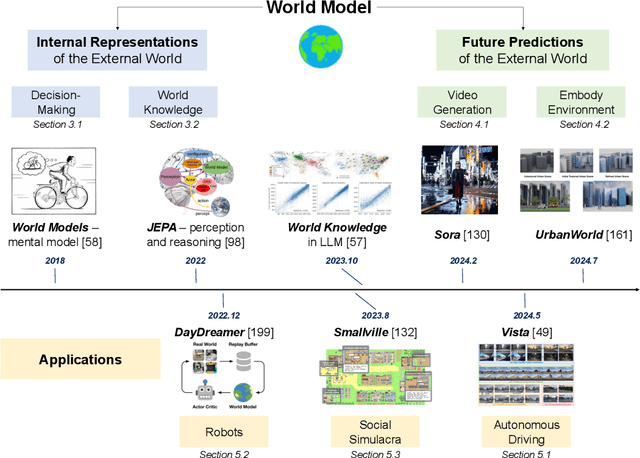

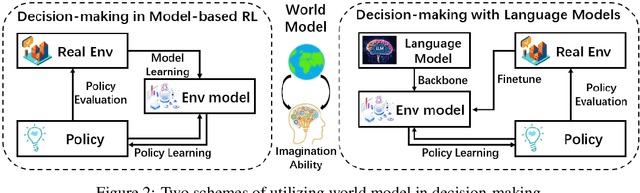
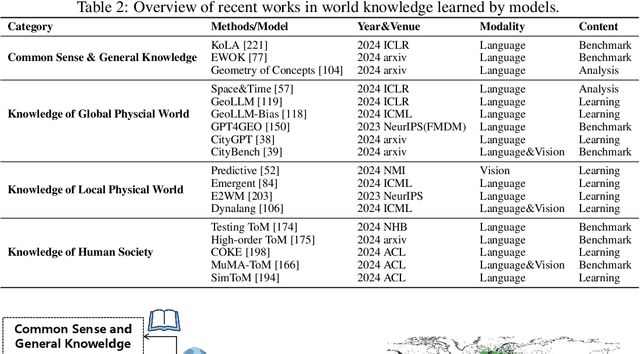
The concept of world models has garnered significant attention due to advancements in multimodal large language models such as GPT-4 and video generation models such as Sora, which are central to the pursuit of artificial general intelligence. This survey offers a comprehensive review of the literature on world models. Generally, world models are regarded as tools for either understanding the present state of the world or predicting its future dynamics. This review presents a systematic categorization of world models, emphasizing two primary functions: (1) constructing internal representations to understand the mechanisms of the world, and (2) predicting future states to simulate and guide decision-making. Initially, we examine the current progress in these two categories. We then explore the application of world models in key domains, including autonomous driving, robotics, and social simulacra, with a focus on how each domain utilizes these aspects. Finally, we outline key challenges and provide insights into potential future research directions.
AgentSquare: Automatic LLM Agent Search in Modular Design Space
Oct 08, 2024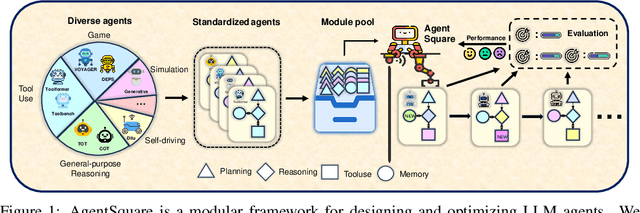
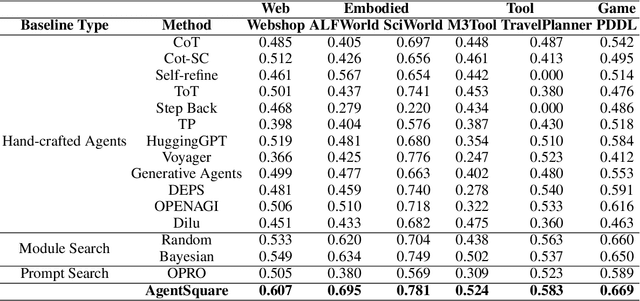
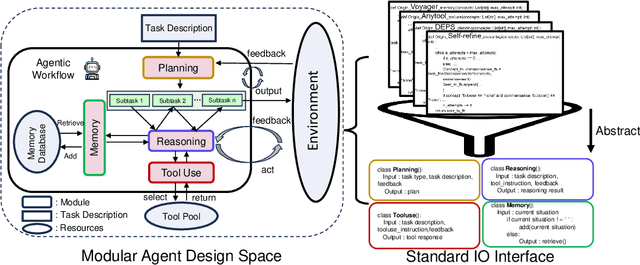

Recent advancements in Large Language Models (LLMs) have led to a rapid growth of agentic systems capable of handling a wide range of complex tasks. However, current research largely relies on manual, task-specific design, limiting their adaptability to novel tasks. In this paper, we introduce a new research problem: Modularized LLM Agent Search (MoLAS). We propose a modular design space that abstracts existing LLM agent designs into four fundamental modules with uniform IO interface: Planning, Reasoning, Tool Use, and Memory. Building on this design space, we present a novel LLM agent search framework called AgentSquare, which introduces two core mechanisms, i.e., module evolution and recombination, to efficiently search for optimized LLM agents. To further accelerate the process, we design a performance predictor that uses in-context surrogate models to skip unpromising agent designs. Extensive experiments across six benchmarks, covering the diverse scenarios of web, embodied, tool use and game applications, show that AgentSquare substantially outperforms hand-crafted agents, achieving an average performance gain of 17.2% against best-known human designs. Moreover, AgentSquare can generate interpretable design insights, enabling a deeper understanding of agentic architecture and its impact on task performance. We believe that the modular design space and AgentSquare search framework offer a platform for fully exploiting the potential of prior successful designs and consolidating the collective efforts of research community. Code repo is available at https://github.com/tsinghua-fib-lab/AgentSquare.
UrbanWorld: An Urban World Model for 3D City Generation
Jul 16, 2024



Cities, as the most fundamental environment of human life, encompass diverse physical elements such as buildings, roads and vegetation with complex interconnection. Crafting realistic, interactive 3D urban environments plays a crucial role in constructing AI agents capable of perceiving, decision-making, and acting like humans in real-world environments. However, creating high-fidelity 3D urban environments usually entails extensive manual labor from designers, involving intricate detailing and accurate representation of complex urban features. Therefore, how to accomplish this in an automatical way remains a longstanding challenge. Toward this problem, we propose UrbanWorld, the first generative urban world model that can automatically create a customized, realistic and interactive 3D urban world with flexible control conditions. UrbanWorld incorporates four key stages in the automatical crafting pipeline: 3D layout generation from openly accessible OSM data, urban scene planning and designing with a powerful urban multimodal large language model (Urban MLLM), controllable urban asset rendering with advanced 3D diffusion techniques, and finally the MLLM-assisted scene refinement. The crafted high-fidelity 3D urban environments enable realistic feedback and interactions for general AI and machine perceptual systems in simulations. We are working on contributing UrbanWorld as an open-source and versatile platform for evaluating and improving AI abilities in perception, decision-making, and interaction in realistic urban environments.
Towards Biologically Plausible Computing: A Comprehensive Comparison
Jun 23, 2024



Backpropagation is a cornerstone algorithm in training neural networks for supervised learning, which uses a gradient descent method to update network weights by minimizing the discrepancy between actual and desired outputs. Despite its pivotal role in propelling deep learning advancements, the biological plausibility of backpropagation is questioned due to its requirements for weight symmetry, global error computation, and dual-phase training. To address this long-standing challenge, many studies have endeavored to devise biologically plausible training algorithms. However, a fully biologically plausible algorithm for training multilayer neural networks remains elusive, and interpretations of biological plausibility vary among researchers. In this study, we establish criteria for biological plausibility that a desirable learning algorithm should meet. Using these criteria, we evaluate a range of existing algorithms considered to be biologically plausible, including Hebbian learning, spike-timing-dependent plasticity, feedback alignment, target propagation, predictive coding, forward-forward algorithm, perturbation learning, local losses, and energy-based learning. Additionally, we empirically evaluate these algorithms across diverse network architectures and datasets. We compare the feature representations learned by these algorithms with brain activity recorded by non-invasive devices under identical stimuli, aiming to identify which algorithm can most accurately replicate brain activity patterns. We are hopeful that this study could inspire the development of new biologically plausible algorithms for training multilayer networks, thereby fostering progress in both the fields of neuroscience and machine learning.