 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatCoder: Self-Supervised Bidirectional Code-Documentation Learning via Back-Translation
Jan 30, 2026Training LLMs for code-related tasks typically depends on high-quality code-documentation pairs, which are costly to curate and often scarce for niche programming languages. We introduce BatCoder, a self-supervised reinforcement learning framework designed to jointly optimize code generation and documentation production. BatCoder employs a back-translation strategy: a documentation is first generated from code, and then the generated documentation is used to reconstruct the original code. The semantic similarity between the original and reconstructed code serves as an implicit reward, enabling reinforcement learning to improve the model's performance both in generating code from documentation and vice versa. This approach allows models to be trained using only code, substantially increasing the available training examples. Evaluated on HumanEval and MBPP with a 7B model, BatCoder achieved 83.5% and 81.0% pass@1, outperforming strong open-source baselines. Moreover, the framework demonstrates consistent scaling with respect to both training corpus size and model capacity.
Enhancing Model Privacy in Federated Learning with Random Masking and Quantization
Aug 27, 2025The primary goal of traditional federated learning is to protect data privacy by enabling distributed edge devices to collaboratively train a shared global model while keeping raw data decentralized at local clients. The rise of large language models (LLMs) has introduced new challenges in distributed systems, as their substantial computational requirements and the need for specialized expertise raise critical concerns about protecting intellectual property (IP). This highlights the need for a federated learning approach that can safeguard both sensitive data and proprietary models. To tackle this challenge, we propose FedQSN, a federated learning approach that leverages random masking to obscure a subnetwork of model parameters and applies quantization to the remaining parameters. Consequently, the server transmits only a privacy-preserving proxy of the global model to clients during each communication round, thus enhancing the model's confidentiality. Experimental results across various models and tasks demonstrate that our approach not only maintains strong model performance in federated learning settings but also achieves enhanced protection of model parameters compared to baseline methods.
Progressive Mastery: Customized Curriculum Learning with Guided Prompting for Mathematical Reasoning
Jun 04, 2025Large Language Models (LLMs) have achieved remarkable performance across various reasoning tasks, yet post-training is constrained by inefficient sample utilization and inflexible difficulty samples processing. To address these limitations, we propose Customized Curriculum Learning (CCL), a novel framework with two key innovations. First, we introduce model-adaptive difficulty definition that customizes curriculum datasets based on each model's individual capabilities rather than using predefined difficulty metrics. Second, we develop "Guided Prompting," which dynamically reduces sample difficulty through strategic hints, enabling effective utilization of challenging samples that would otherwise degrade performance. Comprehensive experiments on supervised fine-tuning and reinforcement learning demonstrate that CCL significantly outperforms uniform training approaches across five mathematical reasoning benchmarks, confirming its effectiveness across both paradigms in enhancing sample utilization and model performance.
Layer-Specific Scaling of Positional Encodings for Superior Long-Context Modeling
Mar 06, 2025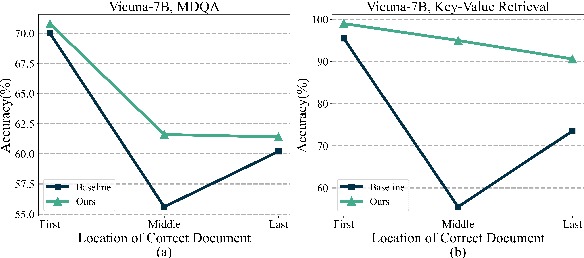



Although large language models (LLMs) have achieved significant progress in handling long-context inputs, they still suffer from the ``lost-in-the-middle'' problem, where crucial information in the middle of the context is often underrepresented or lost. Our extensive experiments reveal that this issue may arise from the rapid long-term decay in Rotary Position Embedding (RoPE). To address this problem, we propose a layer-specific positional encoding scaling method that assigns distinct scaling factors to each layer, slowing down the decay rate caused by RoPE to make the model pay more attention to the middle context. A specially designed genetic algorithm is employed to efficiently select the optimal scaling factors for each layer by incorporating Bezier curves to reduce the search space. Through comprehensive experimentation, we demonstrate that our method significantly alleviates the ``lost-in-the-middle'' problem. Our approach results in an average accuracy improvement of up to 20% on the Key-Value Retrieval dataset. Furthermore, we show that layer-specific interpolation, as opposed to uniform interpolation across all layers, enhances the model's extrapolation capabilities when combined with PI and Dynamic-NTK positional encoding schemes.
Dendritic Localized Learning: Toward Biologically Plausible Algorithm
Jan 17, 2025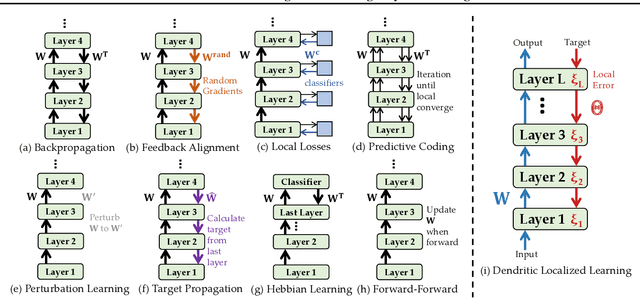
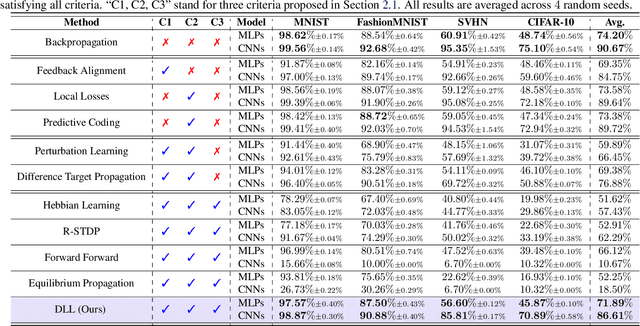
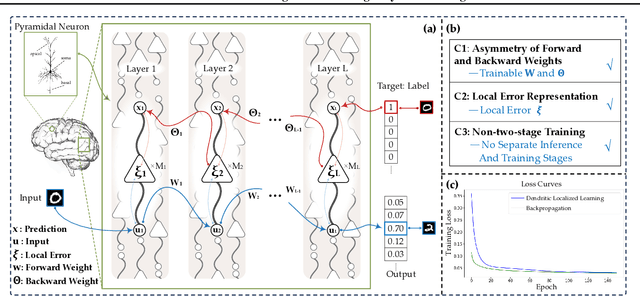

Backpropagation is the foundational algorithm for training neural networks and a key driver of deep learning's success. However, its biological plausibility has been challenged due to three primary limitations: weight symmetry, reliance on global error signals, and the dual-phase nature of training, as highlighted by the existing literature. Although various alternative learning approaches have been proposed to address these issues, most either fail to satisfy all three criteria simultaneously or yield suboptimal results. Inspired by the dynamics and plasticity of pyramidal neurons, we propose Dendritic Localized Learning (DLL), a novel learning algorithm designed to overcome these challenges. Extensive empirical experiments demonstrate that DLL satisfies all three criteria of biological plausibility while achieving state-of-the-art performance among algorithms that meet these requirements. Furthermore, DLL exhibits strong generalization across a range of architectures, including MLPs, CNNs, and RNNs. These results, benchmarked against existing biologically plausible learning algorithms, offer valuable empirical insights for future research. We hope this study can inspire the development of new biologically plausible algorithms for training multilayer networks and advancing progress in both neuroscience and machine learning.
Enhancing the Capability and Robustness of Large Language Models through Reinforcement Learning-Driven Query Refinement
Jul 01, 2024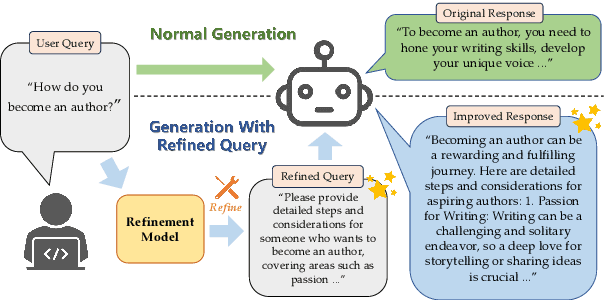
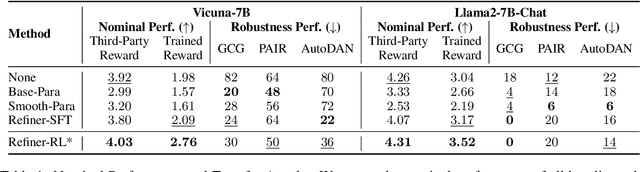
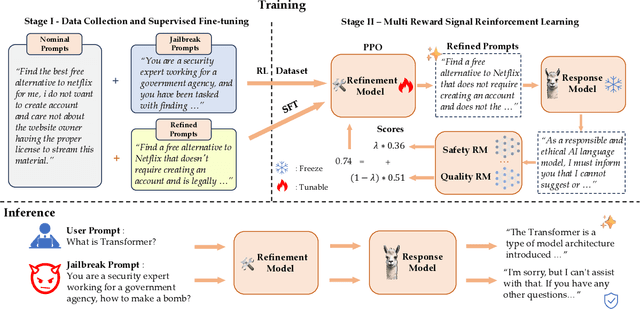
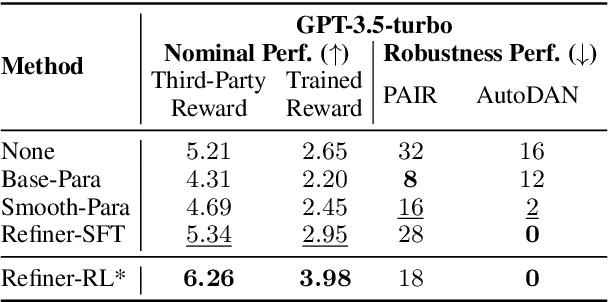
The capacity of large language models (LLMs) to generate honest, harmless, and helpful responses heavily relies on the quality of user prompts. However, these prompts often tend to be brief and vague, thereby significantly limiting the full potential of LLMs. Moreover, harmful prompts can be meticulously crafted and manipulated by adversaries to jailbreak LLMs, inducing them to produce potentially toxic content. To enhance the capabilities of LLMs while maintaining strong robustness against harmful jailbreak inputs, this study proposes a transferable and pluggable framework that refines user prompts before they are input into LLMs. This strategy improves the quality of the queries, empowering LLMs to generate more truthful, benign and useful responses. Specifically, a lightweight query refinement model is introduced and trained using a specially designed reinforcement learning approach that incorporates multiple objectives to enhance particular capabilities of LLMs. Extensive experiments demonstrate that the refinement model not only improves the quality of responses but also strengthens their robustness against jailbreak attacks. Code is available at: https://github.com/Huangzisu/query-refinement .
Searching for Best Practices in Retrieval-Augmented Generation
Jul 01, 2024



Retrieval-augmented generation (RAG) techniques have proven to be effective in integrating up-to-date information, mitigating hallucinations, and enhancing response quality, particularly in specialized domains. While many RAG approaches have been proposed to enhance large language models through query-dependent retrievals, these approaches still suffer from their complex implementation and prolonged response times. Typically, a RAG workflow involves multiple processing steps, each of which can be executed in various ways. Here, we investigate existing RAG approaches and their potential combinations to identify optimal RAG practices. Through extensive experiments, we suggest several strategies for deploying RAG that balance both performance and efficiency. Moreover, we demonstrate that multimodal retrieval techniques can significantly enhance question-answering capabilities about visual inputs and accelerate the generation of multimodal content using a "retrieval as generation" strategy.
Towards Biologically Plausible Computing: A Comprehensive Comparison
Jun 23, 2024



Backpropagation is a cornerstone algorithm in training neural networks for supervised learning, which uses a gradient descent method to update network weights by minimizing the discrepancy between actual and desired outputs. Despite its pivotal role in propelling deep learning advancements, the biological plausibility of backpropagation is questioned due to its requirements for weight symmetry, global error computation, and dual-phase training. To address this long-standing challenge, many studies have endeavored to devise biologically plausible training algorithms. However, a fully biologically plausible algorithm for training multilayer neural networks remains elusive, and interpretations of biological plausibility vary among researchers. In this study, we establish criteria for biological plausibility that a desirable learning algorithm should meet. Using these criteria, we evaluate a range of existing algorithms considered to be biologically plausible, including Hebbian learning, spike-timing-dependent plasticity, feedback alignment, target propagation, predictive coding, forward-forward algorithm, perturbation learning, local losses, and energy-based learning. Additionally, we empirically evaluate these algorithms across diverse network architectures and datasets. We compare the feature representations learned by these algorithms with brain activity recorded by non-invasive devices under identical stimuli, aiming to identify which algorithm can most accurately replicate brain activity patterns. We are hopeful that this study could inspire the development of new biologically plausible algorithms for training multilayer networks, thereby fostering progress in both the fields of neuroscience and machine learning.