 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEESE: Genotype-aware End-to-End Spatio-temporal Embedding for Behavioral Phenotyping
May 23, 2026Behavioral phenotyping of genetic animal models currently requires labor-intensive manual feature engineering that limits reproducibility and scalability. We present GEESE, an end-to-end deep learning framework that learns behavioral representations directly from 3D pose dynamics without hand-crafted features. Using a pretrained time series foundation model, we encode movement sequences into a behavioral manifold that supports both behavior classification and genotype prediction. Evaluated across three autism-associated genetic models (CNTNAP2, CHD8, FMR1), our deep learning approach surpasses hand-crafted feature baselines in both tasks, revealing that learned representations capture genotype-specific behavioral signatures. The framework generalizes across genetic backgrounds, and an all-cohort model identifies both genetic background and genotype from movement patterns alone. We further provide HONK, an interactive intelligent tool enabling researchers without programming expertise to perform behavioral phenotyping from pose data through natural language interaction.
Is Meta-Path Attention an Explanation? Evidence of Alignment and Decoupling in Heterogeneous GNNs
Feb 09, 2026Meta-path-based heterogeneous graph neural networks aggregate over meta-path-induced views, and their semantic-level attention over meta-path channels is widely used as a narrative for ``which semantics matter.'' We study this assumption empirically by asking: when does meta-path attention reflect meta-path importance, and when can it decouple? A key challenge is that most post-hoc GNN explainers are designed for homogeneous graphs, and naive adaptations to heterogeneous neighborhoods can mix semantics and confound perturbations. To enable a controlled empirical analysis, we introduce MetaXplain, a meta-path-aware post-hoc explanation protocol that applies existing explainers in the native meta-path view domain via (i) view-factorized explanations, (ii) schema-valid channel-wise perturbations, and (iii) fusion-aware attribution, without modifying the underlying predictor. We benchmark representative gradient-, perturbation-, and Shapley-style explainers on ACM, DBLP, and IMDB with HAN and HAN-GCN, comparing against xPath and type-matched random baselines under standard faithfulness metrics. To quantify attention reliability, we propose Meta-Path Attention--Explanation Alignment (MP-AEA), which measures rank correlation between learned attention weights and explanation-derived meta-path contribution scores across random runs. Our results show that meta-path-aware explanations typically outperform random controls, while MP-AEA reveals both high-alignment and statistically significant decoupling regimes depending on the dataset and backbone; moreover, retraining on explanation-induced subgraphs often preserves, and in some noisy regimes improves, predictive performance, suggesting an explanation-as-denoising effect.
AutoMiSeg: Automatic Medical Image Segmentation via Test-Time Adaptation of Foundation Models
May 23, 2025Medical image segmentation is vital for clinical diagnosis, yet current deep learning methods often demand extensive expert effort, i.e., either through annotating large training datasets or providing prompts at inference time for each new case. This paper introduces a zero-shot and automatic segmentation pipeline that combines off-the-shelf vision-language and segmentation foundation models. Given a medical image and a task definition (e.g., "segment the optic disc in an eye fundus image"), our method uses a grounding model to generate an initial bounding box, followed by a visual prompt boosting module that enhance the prompts, which are then processed by a promptable segmentation model to produce the final mask. To address the challenges of domain gap and result verification, we introduce a test-time adaptation framework featuring a set of learnable adaptors that align the medical inputs with foundation model representations. Its hyperparameters are optimized via Bayesian Optimization, guided by a proxy validation model without requiring ground-truth labels. Our pipeline offers an annotation-efficient and scalable solution for zero-shot medical image segmentation across diverse tasks. Our pipeline is evaluated on seven diverse medical imaging datasets and shows promising results. By proper decomposition and test-time adaptation, our fully automatic pipeline performs competitively with weakly-prompted interactive foundation models.
Evaluating the Logical Reasoning Abilities of Large Reasoning Models
May 17, 2025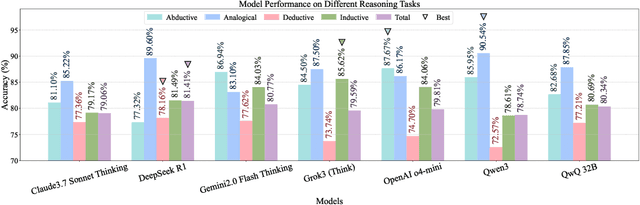

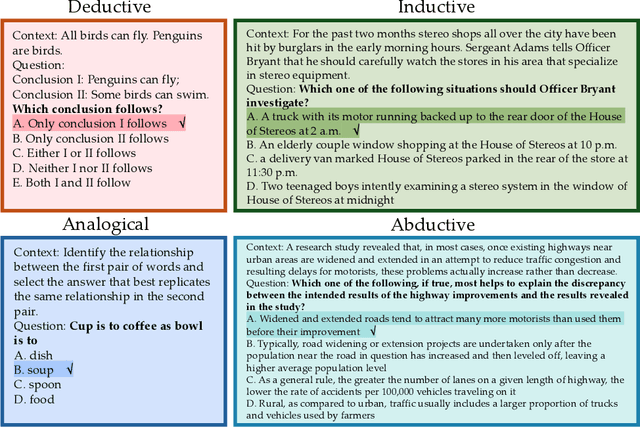
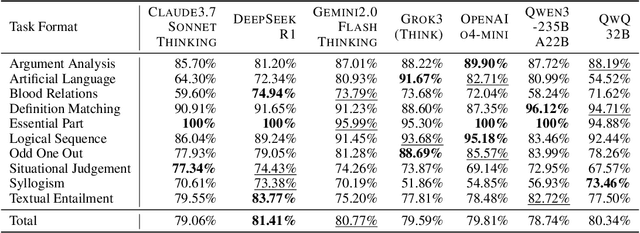
Large reasoning models, often post-trained on long chain-of-thought (long CoT) data with reinforcement learning, achieve state-of-the-art performance on mathematical, coding, and domain-specific reasoning benchmarks. However, their logical reasoning capabilities - fundamental to human cognition and independent of domain knowledge - remain understudied. To address this gap, we introduce LogiEval, a holistic benchmark for evaluating logical reasoning in large reasoning models. LogiEval spans diverse reasoning types (deductive, inductive, analogical, and abductive) and task formats (e.g., logical sequence, argument analysis), sourced from high-quality human examinations (e.g., LSAT, GMAT). Our experiments demonstrate that modern reasoning models excel at 4-choice argument analysis problems and analogical reasoning, surpassing human performance, yet exhibit uneven capabilities across reasoning types and formats, highlighting limitations in their generalization. Our analysis reveals that human performance does not mirror model failure distributions. To foster further research, we curate LogiEval-Hard, a challenging subset identified through a novel screening paradigm where small-model failures (Qwen3-30B-A3B) reliably predict difficulties for larger models. Modern models show striking, consistent failures on LogiEval-Hard. This demonstrates that fundamental reasoning bottlenecks persist across model scales, and establishes LogiEval-Hard as both a diagnostic tool and a rigorous testbed for advancing logical reasoning in LLMs.
Layer-Specific Scaling of Positional Encodings for Superior Long-Context Modeling
Mar 06, 2025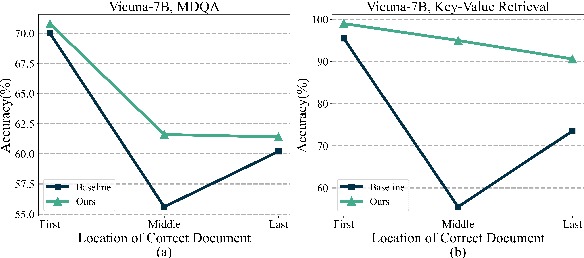



Although large language models (LLMs) have achieved significant progress in handling long-context inputs, they still suffer from the ``lost-in-the-middle'' problem, where crucial information in the middle of the context is often underrepresented or lost. Our extensive experiments reveal that this issue may arise from the rapid long-term decay in Rotary Position Embedding (RoPE). To address this problem, we propose a layer-specific positional encoding scaling method that assigns distinct scaling factors to each layer, slowing down the decay rate caused by RoPE to make the model pay more attention to the middle context. A specially designed genetic algorithm is employed to efficiently select the optimal scaling factors for each layer by incorporating Bezier curves to reduce the search space. Through comprehensive experimentation, we demonstrate that our method significantly alleviates the ``lost-in-the-middle'' problem. Our approach results in an average accuracy improvement of up to 20% on the Key-Value Retrieval dataset. Furthermore, we show that layer-specific interpolation, as opposed to uniform interpolation across all layers, enhances the model's extrapolation capabilities when combined with PI and Dynamic-NTK positional encoding schemes.
A More Advanced Group Polarization Measurement Approach Based on LLM-Based Agents and Graphs
Nov 19, 2024



Group polarization is an important research direction in social media content analysis, attracting many researchers to explore this field. Therefore, how to effectively measure group polarization has become a critical topic. Measuring group polarization on social media presents several challenges that have not yet been addressed by existing solutions. First, social media group polarization measurement involves processing vast amounts of text, which poses a significant challenge for information extraction. Second, social media texts often contain hard-to-understand content, including sarcasm, memes, and internet slang. Additionally, group polarization research focuses on holistic analysis, while texts is typically fragmented. To address these challenges, we designed a solution based on a multi-agent system and used a graph-structured Community Sentiment Network (CSN) to represent polarization states. Furthermore, we developed a metric called Community Opposition Index (COI) based on the CSN to quantify polarization. Finally, we tested our multi-agent system through a zero-shot stance detection task and achieved outstanding results. In summary, the proposed approach has significant value in terms of usability, accuracy, and interpretability.
OccLoff: Learning Optimized Feature Fusion for 3D Occupancy Prediction
Nov 06, 2024



3D semantic occupancy prediction is crucial for finely representing the surrounding environment, which is essential for ensuring the safety in autonomous driving. Existing fusion-based occupancy methods typically involve performing a 2D-to-3D view transformation on image features, followed by computationally intensive 3D operations to fuse these with LiDAR features, leading to high computational costs and reduced accuracy. Moreover, current research on occupancy prediction predominantly focuses on designing specific network architectures, often tailored to particular models, with limited attention given to the more fundamental aspect of semantic feature learning. This gap hinders the development of more transferable methods that could enhance the performance of various occupancy models. To address these challenges, we propose OccLoff, a framework that Learns to Optimize Feature Fusion for 3D occupancy prediction. Specifically, we introduce a sparse fusion encoder with entropy masks that directly fuses 3D and 2D features, improving model accuracy while reducing computational overhead. Additionally, we propose a transferable proxy-based loss function and an adaptive hard sample weighting algorithm, which enhance the performance of several state-of-the-art methods. Extensive evaluations on the nuScenes and SemanticKITTI benchmarks demonstrate the superiority of our framework, and ablation studies confirm the effectiveness of each proposed module.
OccFusion: Depth Estimation Free Multi-sensor Fusion for 3D Occupancy Prediction
Mar 08, 2024



3D occupancy prediction based on multi-sensor fusion, crucial for a reliable autonomous driving system, enables fine-grained understanding of 3D scenes. Previous fusion-based 3D occupancy predictions relied on depth estimation for processing 2D image features. However, depth estimation is an ill-posed problem, hindering the accuracy and robustness of these methods. Furthermore, fine-grained occupancy prediction demands extensive computational resources. We introduce OccFusion, a multi-modal fusion method free from depth estimation, and a corresponding point cloud sampling algorithm for dense integration of image features. Building on this, we propose an active training method and an active coarse to fine pipeline, enabling the model to adaptively learn more from complex samples and optimize predictions specifically for challenging areas such as small or overlapping objects. The active methods we propose can be naturally extended to any occupancy prediction model. Experiments on the OpenOccupancy benchmark show our method surpasses existing state-of-the-art (SOTA) multi-modal methods in IoU across all categories. Additionally, our model is more efficient during both the training and inference phases, requiring far fewer computational resources. Comprehensive ablation studies demonstrate the effectiveness of our proposed techniques.
LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens
Feb 21, 2024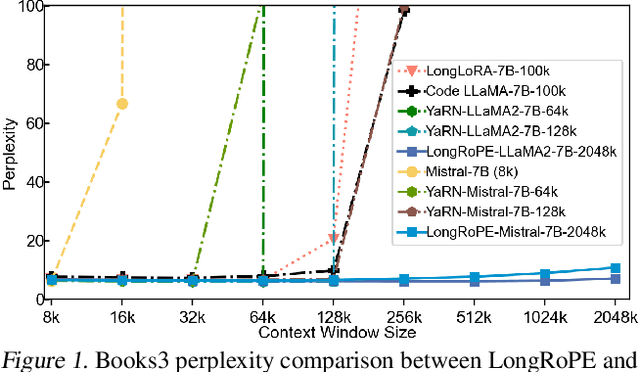
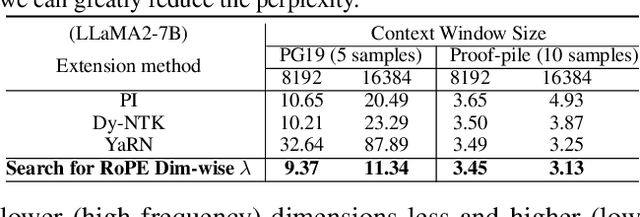
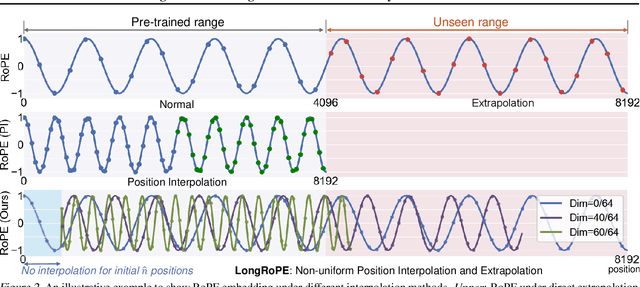

Large context window is a desirable feature in large language models (LLMs). However, due to high fine-tuning costs, scarcity of long texts, and catastrophic values introduced by new token positions, current extended context windows are limited to around 128k tokens. This paper introduces LongRoPE that, for the first time, extends the context window of pre-trained LLMs to an impressive 2048k tokens, with up to only 1k fine-tuning steps at within 256k training lengths, while maintaining performance at the original short context window. This is achieved by three key innovations: (i) we identify and exploit two forms of non-uniformities in positional interpolation through an efficient search, providing a better initialization for fine-tuning and enabling an 8x extension in non-fine-tuning scenarios; (ii) we introduce a progressive extension strategy that first fine-tunes a 256k length LLM and then conducts a second positional interpolation on the fine-tuned extended LLM to achieve a 2048k context window; (iii) we readjust LongRoPE on 8k length to recover the short context window performance. Extensive experiments on LLaMA2 and Mistral across various tasks demonstrate the effectiveness of our method. Models extended via LongRoPE retain the original architecture with minor modifications to the positional embedding, and can reuse most pre-existing optimizations.